The 100-protein NMR spectra dataset: A resource for biomolecular NMR data analysis
Piotr Klukowski1, Fred F. Damberger2, Frédéric H.-T. Allain2, Hideo Iwai3, Harindranath Kadavath1, Theresa A. Ramelot4, Gaetano T. Montelione4, Roland Riek1, Peter Güntert1,5,6
1 Institute of Molecular Physical Science, ETH Zurich, 8093 Zurich, Switzerland
2 Institute of Biochemistry, ETH Zurich, 8093 Zurich, Switzerland
3 Institute of Biotechnology, University of Helsinki, 00100 Helsinki, Finland
4 Department of Chemistry and Chemical Biology, and Center for Biotechnology and Interdisciplinary Sciences, Rensselaer Polytechnic Institute, Troy, NY, 12180, USA
5 Institute of Biophysical Chemistry, Goethe University, 60438 Frankfurt am Main, Germany
6 Department of Chemistry, Tokyo Metropolitan University, Hachioji, 192-0397 Tokyo, Japan
6SVC (35 residues, PDB,
BMRB, 2019)
Reference:
Strotz, D., Orts, J., Kadavath, H., Friedmann, M., Ghosh, D., Olsson, S., Chi, C.N., Pokharna, A., Guntert, P., Vogeli, B., Riek, R. (2020). Protein Allostery at Atomic Resolution. Angew Chem Int Ed Engl 59: 22132-22139
Experimental data:
- Deposited structure

- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×632×474 | C: 33.377 – 62.961
HC: -1.006 – 7.795
H: -0.996 – 11.000 |
700 |
151.07 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1713
sparky, xeasy |
1411
sparky, xeasy |
82.37 |
| 2 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 97.705 – 133.424
C: 25.235 – 71.056
HN: 4.952 – 11.429 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
121
sparky, xeasy |
108
sparky, xeasy |
89.26 |
| 3 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 97.702 – 135.566
C: 38.575 – 70.462
HN: 4.978 – 12.963 |
900 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
63
sparky, xeasy |
55
sparky, xeasy |
87.30 |
| 4 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×362×474 | N: 97.237 – 136.081
HN: 5.968 – 11.004
H: -0.996 – 11.000 |
700 |
84.60 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
616
sparky, xeasy |
400
sparky, xeasy |
64.94 |
| 5 |
NOESY
ucsf, pipe, .3D.16, .3D.param |
2048×1917 | H1: -1.985 – 11.906
H2: -1.510 – 11.492 |
900 |
15.21 |
H1–H2: spectrum, spectrum with peaks |
2368
sparky, xeasy |
1914
sparky, xeasy |
80.83 |
| 6 |
TOCSY
ucsf, pipe, .3D.16, .3D.param |
1024×1917 | H1: -1.981 – 11.902
H2: -1.520 – 11.482 |
900 |
7.90 |
H1–H2: spectrum, spectrum with peaks |
1392
sparky, xeasy |
1149
sparky, xeasy |
82.54 |
2JVD (54 residues, PDB,
BMRB, 2007)
Reference:
Aramini, J.M., Sharma, S., Huang, Y.J., Swapna, G.V., Ho, C.K., Shetty, K., Cunningham, K., Ma, L.C., Zhao, L., Owens, L.A., Jiang, M., Xiao, R., Liu, J., Baran, M.C., Acton, T.B., Rost, B., Montelione, G.T. (2008). Solution NMR structure of the SOS response protein YnzC from Bacillus subtilis. Proteins 72: 526-530
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 4.538 – 70.787
H: -1.846 – 4.817 |
600 |
4.00 |
C–H: spectrum, spectrum with peaks |
258
sparky, xeasy |
238
sparky, xeasy |
92.25 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
512×652×373 | C: 19.890 – 89.749
HC: 0.469 – 7.463
H: 0.185 – 9.634 |
800 |
502.18 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3331
sparky, xeasy |
3181
sparky, xeasy |
95.50 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.705 – 127.611
C: 4.359 – 79.285
HN: 4.795 – 10.284 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
210
sparky, xeasy |
180
sparky, xeasy |
85.71 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.705 – 127.611
C: 4.415 – 79.228
HN: 4.795 – 10.284 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
124
sparky, xeasy |
110
sparky, xeasy |
88.71 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×441 | C1: 29.844 – 53.747
C2: 4.415 – 79.228
H1: -0.004 – 5.989 |
800 |
221.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
956
sparky, xeasy |
918
sparky, xeasy |
96.03 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.705 – 127.611
HN: 4.802 – 10.292
H: 1.049 – 6.040 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
144
sparky, xeasy |
123
sparky, xeasy |
85.42 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×559 | C: 29.844 – 53.747
HC: 0.295 – 6.283
H: 0.002 – 5.997 |
800 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
998
sparky, xeasy |
942
sparky, xeasy |
94.39 |
| 8 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.705 – 127.611
C: 168.771 – 188.728
HN: 4.789 – 10.279 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
63
sparky, xeasy |
56
sparky, xeasy |
88.89 |
| 9 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.705 – 127.611
C: 168.790 – 188.747
HN: 4.795 – 10.285 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
107
sparky, xeasy |
92
sparky, xeasy |
85.98 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 80.164 – 140.114
H: 4.788 – 11.755 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
92
sparky, xeasy |
57
sparky, xeasy |
61.96 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
512×316×373 | N: 104.212 – 134.950
HN: 5.943 – 9.327
H: 0.185 – 9.634 |
800 |
251.09 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1109
sparky, xeasy |
899
sparky, xeasy |
81.06 |
2K57 (55 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Aramini, J.A., Hang, D., Xiao, R., Acton, T.B., Montelione, G.T. Solution NMR Structure of Putative Lipoprotein from Pseudomonas syringae Gene Locus PSPTO2350. Northeast Structural Genomics Target PsR76A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 5.252 – 80.137
H: -2.178 – 11.756 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
256
sparky, xeasy |
250
sparky, xeasy |
97.66 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 112.780 – 142.759
H: -2.179 – 11.755 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
18
sparky, xeasy |
18
sparky, xeasy |
100.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×544×440 | C: 20.021 – 89.744
HC: -1.355 – 6.041
H: -1.003 – 10.996 |
800 |
234.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5829
sparky, xeasy |
5585
sparky, xeasy |
95.81 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.220 – 134.106
C: 4.398 – 79.324
HN: 4.802 – 11.763 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
204
sparky, xeasy |
198
sparky, xeasy |
97.06 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.220 – 134.106
C: 4.266 – 79.192
HN: 4.824 – 11.784 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
125
sparky, xeasy |
119
sparky, xeasy |
95.20 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×551 | C1: 29.764 – 53.714
C2: 4.469 – 79.135
H1: -0.996 – 6.495 |
800 |
280.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
933
sparky, xeasy |
917
sparky, xeasy |
98.29 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 101.697 – 134.478
C: 15.528 – 81.711
HN: 4.792 – 11.773 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
200
sparky, xeasy |
193
sparky, xeasy |
96.50 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.220 – 134.106
HN: 4.794 – 11.754
H: 1.039 – 6.030 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
140
sparky, xeasy |
137
sparky, xeasy |
97.86 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×550 | C: 25.645 – 49.556
HC: -0.211 – 9.774
H: -0.999 – 6.501 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
962
sparky, xeasy |
940
sparky, xeasy |
97.71 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×550 | C: 25.588 – 49.499
HC: -0.204 – 9.781
H: -1.000 – 6.500 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1408
sparky, xeasy |
1382
sparky, xeasy |
98.15 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.220 – 134.106
C: 168.797 – 188.754
HN: 4.802 – 11.762 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
64
sparky, xeasy |
53
sparky, xeasy |
82.81 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.255 – 134.142
C: 168.785 – 188.742
HN: 4.793 – 11.753 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
105
sparky, xeasy |
102
sparky, xeasy |
97.14 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | N: 80.159 – 140.109
H: -2.183 – 11.757 |
800 |
8.00 |
N–H: spectrum, spectrum with peaks |
85
sparky, xeasy |
64
sparky, xeasy |
75.29 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×474×440 | N: 104.311 – 135.019
HN: 5.320 – 11.763
H: -1.003 – 10.996 |
800 |
207.19 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1794
sparky, xeasy |
1541
sparky, xeasy |
85.90 |
6SOW (58 residues, PDB,
BMRB, 2019)
Reference:
Heikkinen, H.A., Backlund, S.M., Iwai, H. (2021). NMR Structure Determinations of Small Proteins Using only One Fractionally 20% 13 C- and Uniformly 100% 15 N-Labeled Sample. Molecules 26
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
962×999 | C: 3.227 – 81.039
H: -0.064 – 5.308 |
850 |
4.00 |
C–H: spectrum, spectrum with peaks |
297
sparky, xeasy |
284
sparky, xeasy |
95.62 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×526×860 | C: 11.118 – 68.686
HC: -0.044 – 5.608
H: 0.161 – 9.415 |
850 |
229.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4070
sparky, xeasy |
3931
sparky, xeasy |
96.58 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×455×875 | C: 111.997 – 141.775
HC: 5.946 – 8.390
H: -0.319 – 9.096 |
850 |
224.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
238
sparky, xeasy |
130
sparky, xeasy |
54.62 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 105.208 – 130.999
C: 5.873 – 85.636
HN: 4.694 – 9.933 |
850 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
216
sparky, xeasy |
206
sparky, xeasy |
95.37 |
| 5 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×1024 | C: 3.148 – 70.589
HC: -2.754 – 7.167
H: -0.325 – 9.665 |
850 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1070
sparky, xeasy |
1061
sparky, xeasy |
99.16 |
| 6 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 105.096 – 130.989
C: 40.900 – 70.798
HN: 4.695 – 9.940 |
850 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
109
sparky, xeasy |
104
sparky, xeasy |
95.41 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 105.157 – 131.049
C: 168.905 – 182.850
HN: 4.691 – 9.935 |
850 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
76
sparky, xeasy |
74
sparky, xeasy |
97.37 |
| 8 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 105.086 – 130.978
C: 168.920 – 182.865
HN: 4.687 – 9.932 |
850 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
109
sparky, xeasy |
104
sparky, xeasy |
95.41 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 105.023 – 134.993
H: 4.689 – 10.196 |
850 |
4.00 |
N–H: spectrum, spectrum with peaks |
90
sparky, xeasy |
74
sparky, xeasy |
82.22 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×1024 | N: 105.189 – 130.980
HN: 4.691 – 10.198
H: -0.810 – 10.169 |
850 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1382
sparky, xeasy |
1224
sparky, xeasy |
88.57 |
2LX7 (60 residues, PDB,
BMRB, 2012)
Reference:
Yang, Y., Ramelot, T.A., Dan, L., Kohan, E., Janjua, H., Xiao, R., Acton, T., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of SH3 domain of growth arrest-specific protein 7 (GAS7) (fragment 1-60) from Homo sapiens, Northeast Structural Genomics Consortium (NESG) Target HR8574A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×440 | C: 3.466 – 88.300
H: -1.191 – 6.496 |
850 |
0.86 |
C–H: spectrum, spectrum with peaks |
252
sparky, xeasy |
251
sparky, xeasy |
99.60 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 110.082 – 139.965
H: 5.498 – 9.498 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
40
sparky, xeasy |
40
sparky, xeasy |
100.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×430×256 | C: 13.258 – 79.000
HC: -1.507 – 6.006
H: -1.173 – 10.780 |
850 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3519
sparky, xeasy |
3354
sparky, xeasy |
95.31 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×274×256 | C: 111.532 – 141.302
HC: 5.498 – 9.498
H: -1.189 – 10.768 |
850 |
36.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
353
sparky, xeasy |
345
sparky, xeasy |
97.73 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×439 | N: 105.081 – 131.374
C: 16.808 – 81.300
HN: 4.999 – 10.999 |
600 |
28.69 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
206
sparky, xeasy |
201
sparky, xeasy |
97.57 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×439 | N: 105.081 – 131.374
C: 9.808 – 74.300
HN: 5.003 – 11.003 |
600 |
28.69 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
114
sparky, xeasy |
113
sparky, xeasy |
99.12 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×398 | C1: 0.352 – 70.086
C2: 0.356 – 70.082
H1: -1.014 – 5.973 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
851
sparky, xeasy |
850
sparky, xeasy |
99.88 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
1694
sparky, xeasy |
1685
sparky, xeasy |
99.47 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×370 | N: 104.957 – 131.250
C: 11.547 – 81.000
HN: 5.497 – 11.993 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
176
sparky, xeasy |
175
sparky, xeasy |
99.43 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×371×128 | N: 104.957 – 131.250
HN: 5.495 – 11.993
H: 0.561 – 6.514 |
600 |
24.44 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
150
sparky, xeasy |
148
sparky, xeasy |
98.67 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×542 | C: 7.630 – 77.354
HC: -0.470 – 6.475
H: -1.999 – 7.502 |
600 |
70.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
904
sparky, xeasy |
903
sparky, xeasy |
99.89 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×541 | C: 7.380 – 77.114
HC: -0.497 – 6.475
H: -2.008 – 7.498 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1264
sparky, xeasy |
1263
sparky, xeasy |
99.92 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×371 | N: 104.957 – 131.250
H: -0.697 – 6.276
HN: 5.490 – 11.988 |
600 |
48.88 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
265
sparky, xeasy |
263
sparky, xeasy |
99.25 |
| 14 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 104.957 – 131.250
C: 41.234 – 71.000
HN: 5.993 – 11.003 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
113
sparky, xeasy |
110
sparky, xeasy |
97.35 |
| 15 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×399 | N: 104.957 – 131.250
C: 167.115 – 180.927
HN: 4.986 – 11.993 |
600 |
25.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
62
sparky, xeasy |
54
sparky, xeasy |
87.10 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×370 | N: 104.957 – 131.250
C: 41.234 – 71.000
HN: 5.496 – 11.991 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
56
sparky, xeasy |
55
sparky, xeasy |
98.21 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×342 | N: 103.029 – 133.000
H: 5.008 – 10.997 |
600 |
1.48 |
N–H: spectrum, spectrum with peaks |
93
sparky, xeasy |
65
sparky, xeasy |
69.89 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×343×512 | N: 104.954 – 131.350
HN: 5.013 – 11.002
H: -1.197 – 10.780 |
850 |
175.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1295
sparky, xeasy |
1015
sparky, xeasy |
78.38 |
2MA6 (61 residues, PDB,
BMRB, 2013)
Reference:
Ramelot, T.A., Yang, Y., Janjua, H., Kohan, E., Wang, H., Xiao, R., Acton, T.B., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR Structure of the RING finger domain from the Kip1 ubiquitination-promoting E3 complex protein 1 (KPC1/RNF123) from Homo sapiens, Northeast Structural Genomics Consortium (NESG) Target HR8700A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×431 | C: 7.721 – 77.683
H: -0.486 – 5.814 |
850 |
1.86 |
C–H: spectrum, spectrum with peaks |
263
sparky, xeasy |
258
sparky, xeasy |
98.10 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×206 | C: 110.031 – 139.918
H: 6.001 – 9.004 |
850 |
0.25 |
C–H: spectrum, spectrum with peaks |
32
sparky, xeasy |
32
sparky, xeasy |
100.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×431×256 | C: 9.087 – 70.563
HC: -0.491 – 5.810
H: -1.668 – 11.279 |
850 |
55.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4583
sparky, xeasy |
4466
sparky, xeasy |
97.45 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×206×256 | C: 111.681 – 141.216
HC: 6.001 – 9.004
H: -0.911 – 10.543 |
850 |
14.06 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
484
sparky, xeasy |
474
sparky, xeasy |
97.93 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×302 | N: 109.156 – 129.992
C: 13.831 – 78.324
HN: 5.695 – 10.993 |
600 |
19.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
223
sparky, xeasy |
217
sparky, xeasy |
97.31 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×302 | N: 102.758 – 136.491
C: 13.984 – 78.476
HN: 5.695 – 10.993 |
600 |
19.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
131
sparky, xeasy |
129
sparky, xeasy |
98.47 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×359 | C1: 5.159 – 74.893
C2: 5.162 – 74.889
H1: -0.512 – 5.789 |
600 |
93.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
892
sparky, xeasy |
884
sparky, xeasy |
99.10 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.940 – 33.987
C2: 13.940 – 33.987
H1: -3.695 – 9.628
H2: -0.484 – 6.459 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
2213
sparky, xeasy |
2186
sparky, xeasy |
98.78 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×419 | N: 109.231 – 130.077
C: 7.196 – 76.679
HN: 5.709 – 11.005 |
850 |
27.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
191
sparky, xeasy |
189
sparky, xeasy |
98.95 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 109.157 – 129.993
HN: 5.692 – 11.003
H: -0.189 – 5.764 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
154
sparky, xeasy |
151
sparky, xeasy |
98.05 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×553 | C: 9.270 – 79.163
HC: -0.444 – 6.531
H: -0.998 – 5.996 |
850 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
961
sparky, xeasy |
950
sparky, xeasy |
98.86 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | C: 11.077 – 74.577
HC: -0.399 – 6.546
H: -1.000 – 5.999 |
600 |
32.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1357
sparky, xeasy |
1346
sparky, xeasy |
99.19 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×419 | N: 109.151 – 130.067
H: -0.449 – 6.526
HN: 5.705 – 11.001 |
850 |
110.50 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
281
sparky, xeasy |
278
sparky, xeasy |
98.93 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×302 | N: 102.626 – 136.493
C: 167.119 – 180.931
HN: 5.690 – 10.989 |
600 |
38.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
66
sparky, xeasy |
65
sparky, xeasy |
98.48 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
2048×419 | N: 109.052 – 130.043
H: 5.713 – 11.009 |
850 |
3.45 |
N–H: spectrum, spectrum with peaks |
77
sparky, xeasy |
66
sparky, xeasy |
85.71 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×363×512 | N: 109.235 – 130.073
HN: 5.712 – 11.016
H: -1.686 – 11.287 |
850 |
93.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1409
sparky, xeasy |
1313
sparky, xeasy |
93.19 |
2JRM (65 residues, PDB,
BMRB, 2007)
Reference:
Tang, Y., Rossi, P., Swapna, G., Wang, H., Jiang, M., Cunningham, K., Owens, L., Ma, L., Xiao, R., Liu, J., Baran, M.C., Acton, T.B., Rost, B., Montelione, G.T. Solution NMR Structure of Ribosome Modulation Factor VP1593 from Vibrio parahaemolyticus. (To be published)
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 5.445 – 80.257
H: -2.136 – 11.805 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
291
sparky, xeasy |
268
sparky, xeasy |
92.10 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×460×256 | C: 33.898 – 57.708
HC: -1.062 – 5.189
H: -0.911 – 10.541 |
800 |
61.88 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4854
sparky, xeasy |
4534
sparky, xeasy |
93.41 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×1024×256 | C: 116.199 – 139.820
HC: -2.166 – 11.768
H: -0.898 – 10.554 |
800 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
466
sparky, xeasy |
438
sparky, xeasy |
93.99 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 104.265 – 132.108
C: 4.498 – 79.166
HN: 4.819 – 10.799 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
242
sparky, xeasy |
218
sparky, xeasy |
90.08 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 104.265 – 132.108
C: 4.586 – 79.254
HN: 4.821 – 10.801 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
152
sparky, xeasy |
141
sparky, xeasy |
92.76 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×2048 | C1: 29.839 – 53.745
C2: 4.586 – 79.254
H1: -1.166 – 10.799 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
988
sparky, xeasy |
937
sparky, xeasy |
94.84 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 104.298 – 132.140
C: 4.586 – 79.254
HN: 4.821 – 10.801 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
228
sparky, xeasy |
216
sparky, xeasy |
94.74 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×1024×256 | N: 104.265 – 132.108
HN: 4.818 – 10.797
H: 0.337 – 6.314 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
177
sparky, xeasy |
160
sparky, xeasy |
90.40 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×2048 | C: 29.839 – 53.745
HC: -1.155 – 6.814
H: -1.166 – 10.799 |
600 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1585
sparky, xeasy |
1506
sparky, xeasy |
95.02 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 104.298 – 132.140
C: 168.913 – 188.713
HN: 4.819 – 10.799 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
79
sparky, xeasy |
58
sparky, xeasy |
73.42 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 105.214 – 127.129
H: 4.857 – 11.824 |
800 |
1.00 |
N–H: spectrum, spectrum with peaks |
133
sparky, xeasy |
79
sparky, xeasy |
59.40 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×956×256 | N: 105.300 – 127.129
HN: 4.956 – 11.460
H: -0.876 – 10.576 |
800 |
125.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2124
sparky, xeasy |
1675
sparky, xeasy |
78.86 |
1YEZ (68 residues, PDB,
BMRB, 2004)
Reference:
Rossi, P., Aramini, J.M., Swapna, G.V.T., Huang, Y.P., Xiao, R., Ho, C.K., Ma, L.C., Acton, T.B., Montelione, G.T.. Solution structure of the conserved protein from the gene locus MM1357 of Methanosarcina mazei. Northeast Structural Genomics target MaR30. (To be published).
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: -3.012 – 76.478
H: -1.405 – 11.087 |
600 |
4.00 |
C–H: spectrum, spectrum with peaks |
306
sparky, xeasy |
299
sparky, xeasy |
97.71 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×533×512 | C: 0.834 – 80.685
HC: -0.482 – 6.021
H: -1.400 – 11.096 |
600 |
544.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3866
sparky, xeasy |
3663
sparky, xeasy |
94.75 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×130×412 | C: 114.879 – 144.146
HC: 6.139 – 7.716
H: -0.449 – 9.601 |
600 |
117.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
246
sparky, xeasy |
211
sparky, xeasy |
85.77 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.749 – 136.198
C: 4.605 – 79.475
HN: 4.865 – 11.361 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
246
sparky, xeasy |
236
sparky, xeasy |
95.93 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.748 – 136.198
C: 4.625 – 79.496
HN: 4.881 – 11.377 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
130
sparky, xeasy |
126
sparky, xeasy |
96.92 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.749 – 136.198
C: 4.681 – 79.552
HN: 4.892 – 11.388 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
212
sparky, xeasy |
207
sparky, xeasy |
97.64 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.706 – 136.155
HN: 4.881 – 11.377
H: -1.837 – 7.143 |
500 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
164
sparky, xeasy |
159
sparky, xeasy |
96.95 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×533 | C: -3.147 – 76.705
HC: -1.416 – 11.066
H: -0.504 – 6.000 |
600 |
544.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1116
sparky, xeasy |
1087
sparky, xeasy |
97.40 |
| 9 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×1024 | C: 100.049 – 152.987
HC: -1.372 – 11.108
H: -1.392 – 11.114 |
600 |
1024.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
133
sparky, xeasy |
103
sparky, xeasy |
77.44 |
| 10 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.758 – 136.207
H: -3.334 – 7.641
HN: 4.883 – 11.379 |
500 |
512.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
306
sparky, xeasy |
299
sparky, xeasy |
97.71 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.698 – 136.148
C: 41.064 – 73.065
HN: 4.870 – 11.366 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
129
sparky, xeasy |
124
sparky, xeasy |
96.12 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.717 – 136.166
C: 164.955 – 184.796
HN: 4.870 – 11.366 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
68
sparky, xeasy |
61
sparky, xeasy |
89.71 |
| 13 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.704 – 136.154
C: 166.959 – 182.831
HN: 4.880 – 11.376 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
129
sparky, xeasy |
122
sparky, xeasy |
94.57 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.749 – 136.198
C: 41.075 – 73.076
HN: 4.884 – 11.380 |
500 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
64
sparky, xeasy |
62
sparky, xeasy |
96.88 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×512 | N: 100.239 – 136.365
H: 4.853 – 11.094 |
600 |
1.00 |
N–H: spectrum, spectrum with peaks |
102
sparky, xeasy |
66
sparky, xeasy |
64.71 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.067 – 135.549
HN: 4.870 – 11.116
H: -1.365 – 11.115 |
600 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1327
sparky, xeasy |
1025
sparky, xeasy |
77.24 |
2L9R (69 residues, PDB,
BMRB, 2011)
Reference:
Liu, G., Xiao, R., Lee, H.-W., Hamilton, K., Ciccosanti, C., Wang, H.B., Acton, T.B., Everett, J.K., Huang, Y.J., Montelione, G.T. Solution NMR Structure of Homeobox domain of Homeobox protein Nkx-3.1 from homo sapiens, Northeast Structural Genomics Consortium Target HR6470A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×464×412 | C: 20.319 – 89.773
HC: -1.344 – 4.962
H: -0.800 – 10.439 |
800 |
97.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4339
sparky, xeasy |
3898
sparky, xeasy |
89.84 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×264×256 | C: 113.242 – 142.773
HC: 4.649 – 8.231
H: -1.643 – 11.306 |
800 |
20.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
412
sparky, xeasy |
332
sparky, xeasy |
80.58 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 106.506 – 130.131
C: 4.417 – 79.124
HN: 4.813 – 11.773 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
267
sparky, xeasy |
227
sparky, xeasy |
85.02 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 106.506 – 130.131
C: 4.417 – 79.124
HN: 4.813 – 11.773 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
161
sparky, xeasy |
142
sparky, xeasy |
88.20 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 30.145 – 53.770
C2: 4.856 – 79.270
H1: -2.161 – 11.773 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1202
sparky, xeasy |
1141
sparky, xeasy |
94.93 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 106.506 – 130.131
HN: 4.813 – 11.773
H: -0.417 – 6.556 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
190
sparky, xeasy |
161
sparky, xeasy |
84.74 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 106.506 – 130.131
C: 167.943 – 189.599
HN: 4.813 – 11.773 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
81
sparky, xeasy |
57
sparky, xeasy |
70.37 |
| 8 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 106.155 – 130.108
H: 4.806 – 11.773 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
126
sparky, xeasy |
72
sparky, xeasy |
57.14 |
| 9 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×324×452 | N: 102.873 – 133.631
HN: 6.011 – 10.411
H: -1.360 – 10.972 |
800 |
79.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1547
sparky, xeasy |
1090
sparky, xeasy |
70.46 |
2K52 (74 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Xiao, R., Acton, T.B., Montelione, G.T. Structure of uncharacterized protein MJ1198 from Methanocaldococcus jannaschii. Northeast Structural Genomics Target MjR117B. To be published.
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | C: 6.412 – 81.265
H: -1.869 – 11.470 |
600 |
2.00 |
C–H: spectrum, spectrum with peaks |
394
sparky, xeasy |
379
sparky, xeasy |
96.19 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1027×403 | C: 20.375 – 89.828
HC: -0.994 – 5.993
H: -0.982 – 10.010 |
800 |
209.18 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5532
sparky, xeasy |
5203
sparky, xeasy |
94.05 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×221×256 | C: 113.006 – 142.772
HC: 6.018 – 9.015
H: -0.644 – 10.313 |
800 |
27.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
303
sparky, xeasy |
216
sparky, xeasy |
71.29 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.351 – 132.117
C: 4.895 – 79.325
HN: 4.813 – 11.789 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
268
sparky, xeasy |
265
sparky, xeasy |
98.88 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.398 – 132.163
C: 4.903 – 79.317
HN: 4.810 – 11.786 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
157
sparky, xeasy |
157
sparky, xeasy |
100.00 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×514 | C1: 32.099 – 55.912
C2: 6.261 – 80.968
H1: -1.000 – 6.003 |
600 |
68.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1400
sparky, xeasy |
1329
sparky, xeasy |
94.93 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 103.585 – 133.117
HN: 4.811 – 11.787
H: 0.317 – 6.294 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
185
sparky, xeasy |
183
sparky, xeasy |
98.92 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×514 | C: 32.014 – 55.826
HC: -0.338 – 6.112
H: -1.006 – 5.997 |
600 |
34.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1391
sparky, xeasy |
1326
sparky, xeasy |
95.33 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×514 | C: 31.993 – 55.805
HC: -0.338 – 6.112
H: -1.014 – 5.989 |
600 |
34.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2079
sparky, xeasy |
1976
sparky, xeasy |
95.05 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.304 – 133.070
C: 41.053 – 72.865
HN: 4.807 – 11.783 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
139
sparky, xeasy |
138
sparky, xeasy |
99.28 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 104.460 – 134.226
C: 167.889 – 189.801
HN: 4.806 – 11.782 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
81
sparky, xeasy |
69
sparky, xeasy |
85.19 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.351 – 133.117
C: 41.078 – 72.839
HN: 4.807 – 11.783 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
69
sparky, xeasy |
69
sparky, xeasy |
100.00 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×512 | N: 100.769 – 135.632
H: 4.823 – 11.783 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
122
sparky, xeasy |
81
sparky, xeasy |
66.39 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×403 | N: 104.459 – 135.047
HN: 4.812 – 11.779
H: -0.985 – 10.007 |
800 |
204.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1710
sparky, xeasy |
1343
sparky, xeasy |
78.54 |
2KRS (74 residues, PDB,
BMRB, 2009)
Reference:
Ramelot, T.A., Cort, J.R., Maglaqui, M., Ciccosanti, C., Janjua, H., Nair, R., Rost, B., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of SH3 domain from CPF_0587 (fragment 415-479) from Clostridium perfringens. Northeast Structural Genomics Consortium (NESG) Target CpR74A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
957×371 | C: 10.144 – 80.163
H: -0.317 – 6.181 |
600 |
1.69 |
C–H: spectrum, spectrum with peaks |
310
sparky, xeasy |
292
sparky, xeasy |
94.19 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×192 | C: 110.117 – 140.000
H: 5.996 – 8.794 |
600 |
0.19 |
C–H: spectrum, spectrum with peaks |
38
sparky, xeasy |
26
sparky, xeasy |
68.42 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×478×256 | C: 11.334 – 78.797
HC: -0.495 – 6.494
H: -0.679 – 10.282 |
850 |
61.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5793
sparky, xeasy |
5458
sparky, xeasy |
94.22 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×192×512 | C: 110.234 – 140.000
HC: 5.996 – 8.794
H: -0.699 – 10.280 |
600 |
48.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
438
sparky, xeasy |
350
sparky, xeasy |
79.91 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×257 | N: 101.125 – 133.000
C: 14.008 – 78.500
HN: 5.995 – 10.502 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
273
sparky, xeasy |
249
sparky, xeasy |
91.21 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×285 | N: 101.113 – 132.987
C: 13.805 – 78.297
HN: 6.226 – 11.226 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
168
sparky, xeasy |
156
sparky, xeasy |
92.86 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×383 | C1: 8.434 – 78.168
C2: 8.260 – 78.123
H1: -0.517 – 6.192 |
600 |
192.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1063
sparky, xeasy |
1027
sparky, xeasy |
96.61 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.617 – 33.987
C2: 13.940 – 33.987
H1: -0.474 – 6.469
H2: -3.685 – 9.638 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
2616
sparky, xeasy |
2560
sparky, xeasy |
97.86 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×253 | N: 101.136 – 132.989
C: 9.086 – 83.500
HN: 5.997 – 10.508 |
600 |
31.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
246
sparky, xeasy |
233
sparky, xeasy |
94.72 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×330×128 | N: 101.261 – 132.988
HN: 6.009 – 10.506
H: 0.341 – 6.294 |
600 |
21.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
190
sparky, xeasy |
172
sparky, xeasy |
90.53 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×513 | C: 8.354 – 78.084
HC: -0.672 – 6.300
H: -0.480 – 6.519 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1088
sparky, xeasy |
1034
sparky, xeasy |
95.04 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×392 | C: 8.272 – 78.002
HC: -0.992 – 6.508
H: -0.490 – 6.509 |
600 |
101.60 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1560
sparky, xeasy |
1506
sparky, xeasy |
96.54 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×253 | N: 101.136 – 132.989
H: -1.189 – 6.780
HN: 5.997 – 10.508 |
600 |
63.75 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
355
sparky, xeasy |
335
sparky, xeasy |
94.37 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×257 | N: 101.125 – 133.000
C: 167.475 – 180.629
HN: 5.995 – 10.502 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
88
sparky, xeasy |
81
sparky, xeasy |
92.05 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×258 | N: 101.261 – 132.988
C: 41.484 – 71.016
HN: 6.011 – 10.511 |
600 |
9.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
72
sparky, xeasy |
66
sparky, xeasy |
91.67 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×258×256 | N: 101.323 – 133.077
HN: 6.006 – 10.506
H: -0.679 – 10.282 |
850 |
34.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1934
sparky, xeasy |
1586
sparky, xeasy |
82.01 |
2K53 (76 residues, PDB,
BMRB, 2008)
Reference:
Swapna, G.V.T., Huang, W., Jiang, M., Foote, E.L., Xiao, R., Nair, R., Everett, J., Acton, T.B., Rost, B., Montelione, G.T. NMR Solution Structure of A3DK08 protein from Clostridium thermocellum: Northeast Structural Genomics Consortium Target CmR9. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478 | C: 5.144 – 78.855
H: -0.541 – 5.956 |
800 |
0.58 |
C–H: spectrum, spectrum with peaks |
337
sparky, xeasy |
322
sparky, xeasy |
95.55 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×361×357 | C: 19.949 – 89.812
HC: 0.027 – 4.930
H: 0.052 – 9.787 |
800 |
271.69 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4922
sparky, xeasy |
4787
sparky, xeasy |
97.26 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×148×441 | C: 113.002 – 142.885
HC: 5.810 – 7.812
H: -0.210 – 10.102 |
800 |
70.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
293
sparky, xeasy |
272
sparky, xeasy |
92.83 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.668 – 134.449
C: 8.817 – 88.515
HN: 4.797 – 11.454 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
284
sparky, xeasy |
265
sparky, xeasy |
93.31 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×203×267 | N: 101.706 – 134.487
C: 14.568 – 77.701
HN: 6.530 – 9.995 |
600 |
58.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
157
sparky, xeasy |
149
sparky, xeasy |
94.90 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×462 | C1: 25.735 – 49.642
C2: -1.874 – 77.393
H1: -0.029 – 5.977 |
600 |
119.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1182
sparky, xeasy |
1152
sparky, xeasy |
97.46 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×288×110 | N: 101.668 – 134.449
HN: 6.713 – 10.452
H: 0.980 – 5.240 |
600 |
31.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
197
sparky, xeasy |
185
sparky, xeasy |
93.91 |
| 8 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
156×93×162 | C: 115.608 – 135.682
HC: 5.088 – 8.084
H: 6.070 – 7.643 |
600 |
11.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
74
sparky, xeasy |
59
sparky, xeasy |
79.73 |
| 9 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
240×146×239 | N: 103.197 – 133.921
H: 0.120 – 5.787
HN: 6.717 – 9.818 |
600 |
37.50 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
352
sparky, xeasy |
340
sparky, xeasy |
96.59 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
245×493 | N: 103.946 – 132.540
H: 6.538 – 9.888 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
101
sparky, xeasy |
77
sparky, xeasy |
76.24 |
| 11 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
493×259×403 | N: 103.616 – 133.010
HN: 6.544 – 10.058
H: -0.546 – 10.446 |
800 |
209.98 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1457
sparky, xeasy |
1331
sparky, xeasy |
91.35 |
2JT1 (77 residues, PDB,
BMRB, 2007)
Reference:
Aramini, J.M., Rossi, P., Cort, J.R., Ma, L.C., Xiao, R., Acton, T.B., Montelione, G.T. (2011). Solution NMR structure of the plasmid-encoded fimbriae regulatory protein PefI from Salmonella enterica serovar Typhimurium. Proteins 79: 335-339
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 5.338 – 80.223
H: -2.174 – 11.759 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
342
sparky, xeasy |
317
sparky, xeasy |
92.69 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×495×512 | C: 2.372 – 80.747
HC: -0.921 – 5.807
H: -0.207 – 9.771 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4218
sparky, xeasy |
4059
sparky, xeasy |
96.23 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.980 – 142.871
HC: 4.789 – 11.749
H: -0.945 – 10.529 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
124
sparky, xeasy |
114
sparky, xeasy |
91.94 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.749 – 131.640
C: 4.331 – 79.257
HN: 4.795 – 11.756 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
286
sparky, xeasy |
252
sparky, xeasy |
88.11 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.746 – 131.637
C: 4.324 – 79.249
HN: 4.792 – 11.752 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
166
sparky, xeasy |
150
sparky, xeasy |
90.36 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.715 – 131.605
HN: 4.796 – 11.756
H: 1.038 – 6.029 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
197
sparky, xeasy |
173
sparky, xeasy |
87.82 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.725 – 131.615
C: 168.783 – 188.741
HN: 4.790 – 11.750 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
86
sparky, xeasy |
78
sparky, xeasy |
90.70 |
| 8 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.715 – 131.605
C: 168.797 – 188.755
HN: 4.795 – 11.755 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
149
sparky, xeasy |
132
sparky, xeasy |
88.59 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 104.638 – 131.613
H: 4.794 – 11.761 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
119
sparky, xeasy |
81
sparky, xeasy |
68.07 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.718 – 131.614
HN: 4.808 – 11.769
H: -0.934 – 10.540 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1389
sparky, xeasy |
1171
sparky, xeasy |
84.31 |
2JVO (77 residues, PDB,
BMRB, 2007)
Reference:
Skrisovska, L., Allain, F.H. (2008). Improved segmental isotope labeling methods for the NMR study of multidomain or large proteins: application to the RRMs of Npl3p and hnRNP L. J Mol Biol 375: 151-164
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
415×1020 | C: 6.534 – 71.217
H: -0.458 – 6.509 |
500 |
1.63 |
C–H: spectrum, spectrum with peaks |
350
sparky, xeasy |
310
sparky, xeasy |
88.57 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
173×298 | C: 110.215 – 137.087
H: 6.085 – 8.116 |
500 |
0.28 |
C–H: spectrum, spectrum with peaks |
46
sparky, xeasy |
22
sparky, xeasy |
47.83 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×993×433 | C: 0.904 – 80.600
HC: -0.496 – 6.305
H: -0.336 – 11.481 |
900 |
448.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5293
sparky, xeasy |
4705
sparky, xeasy |
88.89 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 94.308 – 130.168
C: 11.188 – 72.946
HN: 4.706 – 11.700 |
500 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
276
sparky, xeasy |
241
sparky, xeasy |
87.32 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×2048 | C1: 5.990 – 75.708
C2: 6.017 – 75.736
H1: -0.863 – 10.152 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1252
sparky, xeasy |
1068
sparky, xeasy |
85.30 |
| 6 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×302×585 | C: 5.728 – 71.513
HC: -0.519 – 6.545
H: -0.402 – 6.451 |
500 |
180.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1878
sparky, xeasy |
1596
sparky, xeasy |
84.98 |
| 7 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 94.248 – 130.108
C: 40.409 – 72.285
HN: 4.718 – 11.712 |
500 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
141
sparky, xeasy |
119
sparky, xeasy |
84.40 |
| 8 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 94.240 – 130.100
C: 40.908 – 72.783
HN: 4.706 – 11.700 |
500 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
70
sparky, xeasy |
59
sparky, xeasy |
84.29 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 94.897 – 130.828
H: 4.715 – 11.651 |
600 |
2.00 |
N–H: spectrum, spectrum with peaks |
99
sparky, xeasy |
79
sparky, xeasy |
79.80 |
| 10 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024×512 | N: 94.378 – 130.095
HN: 4.713 – 11.696
H: -2.258 – 11.714 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1567
sparky, xeasy |
1319
sparky, xeasy |
84.17 |
2ERR (81 residues, PDB,
BMRB, 2005)
Reference:
Auweter, S.D., Fasan, R., Reymond, L., Underwood, J.G., Black, D.L., Pitsch, S., Allain, F.H. (2006). Molecular basis of RNA recognition by the human alternative splicing factor Fox-1. EMBO J 25: 163-173
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
460×1154 | C: 5.576 – 73.702
H: -0.402 – 6.337 |
600 |
2.34 |
C–H: spectrum, spectrum with peaks |
365
sparky, xeasy |
317
sparky, xeasy |
86.85 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×609×474 | C: 7.402 – 76.867
HC: -0.463 – 6.648
H: -0.914 – 10.149 |
900 |
150.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5760
sparky, xeasy |
4392
sparky, xeasy |
76.25 |
| 3 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 90.990 – 141.592
C: 15.191 – 74.952
HN: 4.613 – 12.098 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
177
sparky, xeasy |
172
sparky, xeasy |
97.18 |
| 4 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×282×521 | C: 7.124 – 72.228
HC: -0.783 – 6.625
H: -0.258 – 6.332 |
600 |
76.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1963
sparky, xeasy |
1493
sparky, xeasy |
76.06 |
| 5 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
120×128×767 | N: 101.833 – 133.443
C: 40.756 – 74.489
HN: 6.328 – 11.556 |
600 |
45.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
156
sparky, xeasy |
151
sparky, xeasy |
96.79 |
| 6 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 98.779 – 138.700
H: 4.625 – 12.629 |
600 |
2.00 |
N–H: spectrum, spectrum with peaks |
144
sparky, xeasy |
91
sparky, xeasy |
63.19 |
| 7 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024×512 | N: 99.188 – 132.922
HN: 4.606 – 12.610
H: -3.374 – 12.593 |
750 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1778
sparky, xeasy |
1315
sparky, xeasy |
73.96 |
2L1P (83 residues, PDB,
BMRB, 2010)
Reference:
Swapna, G.V.T., Montelione, A.F., Shastry, R., Ciccosanti, C., Janjua, H., Xiao, R., Acton, T.B., Everett, J.K., Montelione, G.T. NMR solution structure of the N-terminal domain of DNA-binding protein SATB1 from Homo sapiens: Northeast Structural Genomics Target HR4435B(179-250). To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: -9.964 – 155.532
H: -1.224 – 10.734 |
600 |
4.00 |
C–H: spectrum, spectrum with peaks |
419
sparky, xeasy |
361
sparky, xeasy |
86.16 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×537×512 | C: 19.884 – 89.747
HC: -0.859 – 6.442
H: -2.220 – 11.753 |
800 |
544.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4754
sparky, xeasy |
4166
sparky, xeasy |
87.63 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | C: 113.623 – 141.568
HC: 4.764 – 11.724
H: -2.222 – 11.751 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
334
sparky, xeasy |
242
sparky, xeasy |
72.46 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.331 – 135.198
C: 4.500 – 79.223
HN: 4.770 – 11.746 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
314
sparky, xeasy |
274
sparky, xeasy |
87.26 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×477 | C1: 29.820 – 53.727
C2: 4.625 – 79.332
H1: -0.500 – 5.998 |
600 |
123.25 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1259
sparky, xeasy |
1153
sparky, xeasy |
91.58 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | N: 100.272 – 136.132
HN: 4.770 – 11.746
H: -1.213 – 6.756 |
600 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
221
sparky, xeasy |
192
sparky, xeasy |
86.88 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.331 – 135.198
C: 167.792 – 189.791
HN: 4.770 – 11.746 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
95
sparky, xeasy |
67
sparky, xeasy |
70.53 |
| 8 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 102.289 – 134.164
H: 4.760 – 11.727 |
800 |
1.00 |
N–H: spectrum, spectrum with peaks |
125
sparky, xeasy |
87
sparky, xeasy |
69.60 |
| 9 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 100.792 – 131.561
HN: 4.764 – 11.724
H: -2.221 – 11.752 |
800 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1868
sparky, xeasy |
1450
sparky, xeasy |
77.62 |
2LN3 (83 residues, PDB,
BMRB, 2011)
Reference:
Koga, N., Tatsumi-Koga, R., Liu, G., Xiao, R., Acton, T.B., Montelione, G.T., Baker, D. (2012). Principles for designing ideal protein structures. Nature 491: 222-227
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.791 – 76.654
H: -2.165 – 11.776 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
396
sparky, xeasy |
375
sparky, xeasy |
94.70 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×2048 | C: 112.890 – 142.656
H: -2.165 – 11.776 |
800 |
1.00 |
C–H: spectrum, spectrum with peaks |
32
sparky, xeasy |
20
sparky, xeasy |
62.50 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×504×412 | C: 20.046 – 89.499
HC: -0.799 – 6.052
H: -0.800 – 10.439 |
800 |
104.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5630
sparky, xeasy |
5284
sparky, xeasy |
93.85 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×144×256 | C: 113.242 – 142.773
HC: 6.018 – 7.966
H: -1.643 – 11.306 |
800 |
12.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
363
sparky, xeasy |
310
sparky, xeasy |
85.40 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.569 – 132.131
C: 4.417 – 79.124
HN: 4.813 – 11.773 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
320
sparky, xeasy |
288
sparky, xeasy |
90.00 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.569 – 132.131
C: 4.417 – 79.124
HN: 4.813 – 11.773 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
191
sparky, xeasy |
176
sparky, xeasy |
92.15 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 29.958 – 53.583
C2: 4.856 – 79.270
H1: -2.161 – 11.773 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1466
sparky, xeasy |
1420
sparky, xeasy |
96.86 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 104.569 – 132.131
HN: 4.813 – 11.773
H: -0.417 – 6.556 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
226
sparky, xeasy |
203
sparky, xeasy |
89.82 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 104.569 – 132.131
C: 167.943 – 189.599
HN: 4.813 – 11.773 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
98
sparky, xeasy |
73
sparky, xeasy |
74.49 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 104.158 – 132.104
H: 4.803 – 11.770 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
134
sparky, xeasy |
93
sparky, xeasy |
69.40 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×324×512 | N: 102.873 – 133.631
HN: 6.011 – 10.411
H: -2.164 – 11.803 |
800 |
88.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1791
sparky, xeasy |
1420
sparky, xeasy |
79.29 |
2HEQ (84 residues, PDB,
BMRB, 2006)
Reference:
Ramelot, T.A., Cort, J.R., Xiao, R., Swapna, G.V.T., Acton, T.B., Montelione, G.T., Kennedy, M.A.. NMR Structure of Bacillus subtilis protein YorP, Northeast Structural Genomics Target SR399. (To be published)
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
854×512 | C: 5.046 – 80.017
H: -2.001 – 7.003 |
749 |
1.86 |
C–H: spectrum, spectrum with peaks |
349
sparky, xeasy |
340
sparky, xeasy |
97.42 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | C: 31.137 – 54.949
HC: -2.004 – 7.000
H: -1.641 – 11.310 |
749 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3686
sparky, xeasy |
3496
sparky, xeasy |
94.85 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×481×256 | C: 31.177 – 55.084
HC: -2.030 – 6.964
H: -0.191 – 9.770 |
600 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3686
sparky, xeasy |
3496
sparky, xeasy |
94.85 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×378 | N: 106.201 – 130.013
C: 11.514 – 80.967
HN: 5.012 – 12.008 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
298
sparky, xeasy |
284
sparky, xeasy |
95.30 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×378 | N: 106.201 – 130.013
C: 11.492 – 80.945
HN: 5.010 – 12.006 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
160
sparky, xeasy |
154
sparky, xeasy |
96.25 |
| 6 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.614 – 33.990
C2: 13.902 – 33.955
H1: -0.463 – 6.482
H2: -3.672 – 9.656 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
2689
sparky, xeasy |
2640
sparky, xeasy |
98.18 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×406 | C: 31.056 – 54.963
HC: -1.023 – 6.478
H: -1.023 – 6.493 |
600 |
105.84 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1237
sparky, xeasy |
1206
sparky, xeasy |
97.49 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×406 | C: 31.057 – 54.964
HC: -1.020 – 6.480
H: -1.022 – 6.493 |
600 |
105.84 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1771
sparky, xeasy |
1736
sparky, xeasy |
98.02 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×378 | N: 106.212 – 130.024
C: 41.380 – 70.911
HN: 5.010 – 12.006 |
600 |
13.22 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
157
sparky, xeasy |
150
sparky, xeasy |
95.54 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×378 | N: 106.210 – 130.026
C: 166.291 – 181.957
HN: 5.010 – 12.005 |
600 |
13.22 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
84
sparky, xeasy |
75
sparky, xeasy |
89.29 |
| 11 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×378 | N: 106.201 – 130.013
C: 41.440 – 70.972
HN: 5.010 – 12.006 |
600 |
13.22 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
78
sparky, xeasy |
75
sparky, xeasy |
96.15 |
| 12 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×444 | N: 106.009 – 129.962
H: 4.514 – 12.023 |
749 |
0.97 |
N–H: spectrum, spectrum with peaks |
112
sparky, xeasy |
84
sparky, xeasy |
75.00 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×400×512 | N: 106.087 – 129.993
HN: 4.998 – 12.007
H: -1.669 – 11.306 |
600 |
204.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1247
sparky, xeasy |
1023
sparky, xeasy |
82.04 |
2KK8 (84 residues, PDB,
BMRB, 2009)
Reference:
Mani, R., Gurla, S.V.T., Shastry, R., Ciccosanti, C., Foote, E., Jiang, M., Xiao, R., Nair, R., Everett, J., Huang, Y., Acton, T., Rost, B., Montelione, G.T. NMR Solution Structure of a Putative Uncharacterized Protein obtained from Arabidopsis thaliana: Northeast Structural Genomics Consortium Target AR3449A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×998 | C: -2.011 – 77.413
H: -0.498 – 5.997 |
600 |
2.18 |
C–H: spectrum, spectrum with peaks |
383
sparky, xeasy |
340
sparky, xeasy |
88.77 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478×512 | C: 20.092 – 89.818
HC: -0.504 – 5.993
H: -2.123 – 11.849 |
800 |
245.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7332
sparky, xeasy |
6501
sparky, xeasy |
88.67 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | C: 114.178 – 142.068
HC: 4.862 – 11.822
H: -2.047 – 11.899 |
800 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
208
sparky, xeasy |
105
sparky, xeasy |
50.48 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.581 – 134.363
C: 8.819 – 88.517
HN: 4.827 – 11.484 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
320
sparky, xeasy |
288
sparky, xeasy |
90.00 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 100.048 – 136.107
C: 12.415 – 85.077
HN: 4.844 – 11.488 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
191
sparky, xeasy |
176
sparky, xeasy |
92.15 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×270 | C1: 25.753 – 49.661
C2: 1.415 – 74.078
H1: -0.505 – 6.504 |
600 |
68.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1391
sparky, xeasy |
1264
sparky, xeasy |
90.87 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 100.048 – 136.107
C: 12.415 – 85.077
HN: 4.835 – 11.492 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
307
sparky, xeasy |
291
sparky, xeasy |
94.79 |
| 8 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 99.056 – 135.186
H: -0.165 – 9.821
HN: 4.831 – 11.488 |
600 |
512.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
440
sparky, xeasy |
399
sparky, xeasy |
90.68 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 101.680 – 134.462
C: 34.834 – 74.468
HN: 4.845 – 11.818 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
163
sparky, xeasy |
146
sparky, xeasy |
89.57 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 100.048 – 136.107
C: 168.041 – 185.213
HN: 4.844 – 11.488 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
97
sparky, xeasy |
70
sparky, xeasy |
72.16 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×512 | N: 101.277 – 135.144
H: 4.855 – 11.815 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
125
sparky, xeasy |
89
sparky, xeasy |
71.20 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | N: 102.847 – 133.556
HN: 4.855 – 11.815
H: -2.113 – 11.833 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2408
sparky, xeasy |
1976
sparky, xeasy |
82.06 |
2KD0 (85 residues, PDB,
BMRB, 2008)
Reference:
Swapna, G.V.T., Shastry, R., Foote, E., Ciccosanti, C., Jiang, M., Xiao, R., Nair, R., Everett, J., Huang, Y., Acton, T.B., Rost, B., Montelione, G.T. NMR solution structure of O64736 protein from Arabidopsis thaliana. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×515 | C: 5.093 – 78.948
H: -0.504 – 6.497 |
800 |
1.13 |
C–H: spectrum, spectrum with peaks |
395
sparky, xeasy |
364
sparky, xeasy |
92.15 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478×512 | C: 20.256 – 89.982
HC: -0.504 – 5.993
H: -2.123 – 11.849 |
800 |
245.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8208
sparky, xeasy |
7693
sparky, xeasy |
93.73 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | C: 113.862 – 141.753
HC: 4.863 – 11.823
H: -2.096 – 11.849 |
800 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
268
sparky, xeasy |
178
sparky, xeasy |
66.42 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.389 – 133.256
C: 4.689 – 79.412
HN: 4.863 – 11.827 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
307
sparky, xeasy |
267
sparky, xeasy |
86.97 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.349 – 133.217
C: 4.602 – 79.323
HN: 4.863 – 11.827 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
177
sparky, xeasy |
158
sparky, xeasy |
89.27 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×508 | C1: 30.050 – 53.957
C2: 7.171 – 76.898
H1: -0.508 – 6.398 |
800 |
131.75 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1482
sparky, xeasy |
1419
sparky, xeasy |
95.75 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | N: 99.310 – 133.177
HN: 4.865 – 12.860
H: 0.373 – 6.349 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
215
sparky, xeasy |
185
sparky, xeasy |
86.05 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×515 | C: 30.219 – 54.125
HC: -0.373 – 6.599
H: -0.504 – 6.497 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2209
sparky, xeasy |
2110
sparky, xeasy |
95.52 |
| 9 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.323 – 133.190
H: -1.144 – 6.825
HN: 4.851 – 11.826 |
600 |
128.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
426
sparky, xeasy |
392
sparky, xeasy |
92.02 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.270 – 133.137
C: 167.860 – 189.859
HN: 4.863 – 11.823 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
92
sparky, xeasy |
70
sparky, xeasy |
76.09 |
| 11 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.310 – 133.177
C: 167.860 – 189.859
HN: 4.863 – 11.823 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
161
sparky, xeasy |
140
sparky, xeasy |
86.96 |
| 12 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×512 | N: 99.263 – 133.197
H: 4.863 – 11.827 |
800 |
1.00 |
N–H: spectrum, spectrum with peaks |
115
sparky, xeasy |
82
sparky, xeasy |
71.30 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | N: 100.883 – 131.591
HN: 4.863 – 11.823
H: -2.096 – 11.849 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2326
sparky, xeasy |
1907
sparky, xeasy |
81.99 |
2LML (86 residues, PDB,
BMRB, 2011)
Reference:
Ramelot, T.A., Smola, M.J., Lee, H.W., Ciccosanti, C., Hamilton, K., Acton, T.B., Xiao, R., Everett, J.K., Prestegard, J.H., Montelione, G.T., Kennedy, M.A. (2011). Solution structure of 4'-phosphopantetheine - GmACP3 from Geobacter metallireducens: a specialized acyl carrier protein with atypical structural features and a putative role in lipopolysaccharide biosynthesis. Biochemistry 50: 1442-1453
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×359 | C: 3.250 – 83.094
H: -1.003 – 5.985 |
600 |
0.77 |
C–H: spectrum, spectrum with peaks |
387
sparky, xeasy |
370
sparky, xeasy |
95.61 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×401×256 | C: 7.074 – 76.800
HC: -0.996 – 6.008
H: -1.004 – 10.650 |
850 |
106.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8251
sparky, xeasy |
7859
sparky, xeasy |
95.25 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×172×256 | C: 112.733 – 140.305
HC: 6.008 – 9.003
H: -1.036 – 10.682 |
850 |
11.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
583
sparky, xeasy |
497
sparky, xeasy |
85.25 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×258 | N: 103.234 – 133.000
C: 14.160 – 78.652
HN: 5.985 – 11.002 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
332
sparky, xeasy |
308
sparky, xeasy |
92.77 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×386 | N: 103.082 – 132.965
C: 14.008 – 78.500
HN: 5.985 – 13.500 |
600 |
51.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
186
sparky, xeasy |
174
sparky, xeasy |
93.55 |
| 6 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.986
C2: 13.617 – 33.986
H1: -3.670 – 9.653
H2: -0.459 – 6.484 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3755
sparky, xeasy |
3686
sparky, xeasy |
98.16 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.082 – 132.965
C: 14.008 – 78.500
HN: 5.991 – 11.007 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
297
sparky, xeasy |
282
sparky, xeasy |
94.95 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×315×256 | N: 102.910 – 133.337
HN: 5.506 – 11.004
H: 0.412 – 6.271 |
850 |
80.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
230
sparky, xeasy |
212
sparky, xeasy |
92.17 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×401 | C: 7.348 – 76.799
HC: -1.381 – 5.592
H: -1.012 – 5.993 |
850 |
53.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1387
sparky, xeasy |
1334
sparky, xeasy |
96.18 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×401 | C: 7.074 – 76.799
HC: -1.438 – 5.534
H: -0.996 – 6.008 |
850 |
106.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2079
sparky, xeasy |
2016
sparky, xeasy |
96.97 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.082 – 132.965
H: -0.669 – 6.277
HN: 5.991 – 11.007 |
600 |
34.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
418
sparky, xeasy |
396
sparky, xeasy |
94.74 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.082 – 132.965
C: 165.633 – 182.500
HN: 5.991 – 11.007 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
94
sparky, xeasy |
82
sparky, xeasy |
87.23 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×386 | N: 103.082 – 132.965
C: 41.305 – 71.070
HN: 5.991 – 13.506 |
600 |
51.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
84
sparky, xeasy |
78
sparky, xeasy |
92.86 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×308 | N: 103.193 – 133.076
H: 6.006 – 10.504 |
850 |
0.30 |
N–H: spectrum, spectrum with peaks |
125
sparky, xeasy |
91
sparky, xeasy |
72.80 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×315×256 | N: 103.240 – 133.077
HN: 4.998 – 10.497
H: -1.036 – 10.682 |
850 |
40.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2627
sparky, xeasy |
2209
sparky, xeasy |
84.09 |
2K3D (87 residues, PDB,
BMRB, 2008)
Reference:
Ramelot, T.A., Zhao, L., Jiang, M., Foote, E.L., Xiao, R., Liu, J., Baran, M.C., Swapna, G.V.T., Acton, T.B., Rost, B., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the folded 79 residue fragment of Lin0334 from Listeria innocua. Northeast Structural Genomics Consortium target LkR15. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×240 | C: 112.841 – 142.782
H: 5.503 – 9.005 |
850 |
0.47 |
C–H: spectrum, spectrum with peaks |
66
sparky, xeasy |
47
sparky, xeasy |
71.21 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478×256 | C: 6.768 – 81.324
HC: -0.989 – 6.001
H: -0.679 – 10.282 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6753
sparky, xeasy |
6387
sparky, xeasy |
94.58 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×240×256 | C: 114.871 – 140.770
HC: 5.503 – 9.005
H: -0.657 – 10.300 |
850 |
60.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
695
sparky, xeasy |
538
sparky, xeasy |
77.41 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×308 | N: 103.849 – 132.642
C: 10.444 – 79.719
HN: 5.503 – 10.002 |
850 |
20.19 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
326
sparky, xeasy |
298
sparky, xeasy |
91.41 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×308 | N: 103.849 – 132.642
C: 10.662 – 80.210
HN: 5.499 – 9.997 |
850 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
202
sparky, xeasy |
188
sparky, xeasy |
93.07 |
| 6 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.986
C2: 13.617 – 33.986
H1: -3.660 – 9.663
H2: -0.449 – 6.494 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3131
sparky, xeasy |
3070
sparky, xeasy |
98.05 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×308×256 | N: 103.817 – 132.610
HN: 5.499 – 9.997
H: 0.412 – 6.271 |
850 |
40.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
229
sparky, xeasy |
211
sparky, xeasy |
92.14 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×479 | C: 7.248 – 76.699
HC: -0.382 – 6.591
H: -0.963 – 6.041 |
850 |
61.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2027
sparky, xeasy |
1978
sparky, xeasy |
97.58 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
64×128×308 | N: 104.008 – 132.574
C: 41.432 – 71.185
HN: 5.499 – 9.997 |
850 |
10.69 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
167
sparky, xeasy |
153
sparky, xeasy |
91.62 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×274 | N: 103.817 – 132.610
C: 166.822 – 183.698
HN: 6.002 – 10.002 |
850 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
103
sparky, xeasy |
96
sparky, xeasy |
93.20 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×343 | N: 103.579 – 132.466
H: 4.988 – 11.000 |
600 |
0.42 |
N–H: spectrum, spectrum with peaks |
124
sparky, xeasy |
98
sparky, xeasy |
79.03 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×410×256 | N: 103.704 – 132.610
HN: 5.503 – 11.496
H: -0.657 – 10.300 |
850 |
106.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2291
sparky, xeasy |
1969
sparky, xeasy |
85.95 |
2LK2 (89 residues, PDB,
BMRB, 2011)
Reference:
Yang, Y., Ramelot, T.A., Cort, J.R., Shastry, R., Ciccosanti, C., Hamilton, K., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of homeobox domain (171-248) of human homeobox protein TGIF1, Northeast Structural Genomics Consortium Target HR4411B. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×429 | C: 3.234 – 88.151
H: -0.994 – 6.501 |
850 |
1.86 |
C–H: spectrum, spectrum with peaks |
413
sparky, xeasy |
388
sparky, xeasy |
93.95 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 108.133 – 142.000
H: 5.498 – 9.498 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
50
sparky, xeasy |
22
sparky, xeasy |
44.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×458×256 | C: 12.974 – 78.845
HC: -1.506 – 6.496
H: -1.173 – 10.780 |
850 |
231.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6499
sparky, xeasy |
5923
sparky, xeasy |
91.14 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274×256 | C: 111.416 – 141.301
HC: 5.498 – 9.498
H: -1.173 – 10.780 |
850 |
72.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
459
sparky, xeasy |
220
sparky, xeasy |
47.93 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×343 | N: 103.113 – 132.000
C: 13.180 – 78.923
HN: 5.500 – 11.506 |
600 |
89.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
332
sparky, xeasy |
312
sparky, xeasy |
93.98 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.113 – 132.000
C: 14.500 – 78.000
HN: 5.500 – 11.998 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
205
sparky, xeasy |
195
sparky, xeasy |
95.12 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.940 – 33.987
C2: 13.940 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3055
sparky, xeasy |
2876
sparky, xeasy |
94.14 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×401 | N: 103.226 – 132.001
C: 9.086 – 83.500
HN: 5.496 – 12.004 |
600 |
26.56 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
312
sparky, xeasy |
301
sparky, xeasy |
96.47 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×371×128 | N: 103.226 – 132.000
HN: 5.505 – 12.003
H: 0.093 – 7.039 |
600 |
24.44 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
236
sparky, xeasy |
221
sparky, xeasy |
93.64 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×110×462 | C: 3.313 – 82.999
HC: -0.996 – 6.499
H: -0.991 – 6.510 |
600 |
52.99 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1555
sparky, xeasy |
1458
sparky, xeasy |
93.76 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×462 | C: 8.190 – 77.920
HC: -1.179 – 6.789
H: -0.986 – 6.514 |
600 |
119.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2225
sparky, xeasy |
2071
sparky, xeasy |
93.08 |
| 12 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×371 | N: 103.113 – 132.000
H: -0.672 – 6.300
HN: 5.505 – 12.003 |
600 |
97.75 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
471
sparky, xeasy |
448
sparky, xeasy |
95.12 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.113 – 132.000
C: 41.164 – 70.930
HN: 5.505 – 12.003 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
159
sparky, xeasy |
94.08 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×371 | N: 103.226 – 132.000
C: 168.218 – 183.968
HN: 5.495 – 11.993 |
600 |
12.94 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
104
sparky, xeasy |
100
sparky, xeasy |
96.15 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.113 – 132.000
C: 41.094 – 70.859
HN: 5.505 – 12.003 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
84
sparky, xeasy |
79
sparky, xeasy |
94.05 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×445 | N: 103.038 – 133.009
H: 5.498 – 12.002 |
600 |
1.93 |
N–H: spectrum, spectrum with peaks |
161
sparky, xeasy |
108
sparky, xeasy |
67.08 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×287×256 | N: 103.295 – 132.068
HN: 5.498 – 10.506
H: -0.677 – 10.280 |
850 |
36.13 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2445
sparky, xeasy |
1885
sparky, xeasy |
77.10 |
MH04 (90 residues, PDB)
Reference:
Not available
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×1024 | C: 6.306 – 84.411
H: -1.907 – 11.421 |
600 |
2.00 |
C–H: spectrum, spectrum with peaks |
411
sparky, xeasy |
352
sparky, xeasy |
85.64 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×2048×512 | C: 6.223 – 80.214
HC: -2.133 – 11.614
H: -2.119 – 11.608 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6163
sparky, xeasy |
4616
sparky, xeasy |
74.90 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 101.438 – 135.305
C: 7.689 – 87.378
HN: 4.774 – 11.438 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
325
sparky, xeasy |
315
sparky, xeasy |
96.92 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 101.451 – 135.318
C: 10.203 – 84.910
HN: 4.775 – 11.439 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
210
sparky, xeasy |
206
sparky, xeasy |
98.10 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 101.584 – 135.318
C: 6.797 – 88.477
HN: 4.775 – 11.439 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
324
sparky, xeasy |
318
sparky, xeasy |
98.15 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | N: 101.557 – 135.292
HN: 4.786 – 11.433
H: -1.696 – 11.253 |
600 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
220
sparky, xeasy |
203
sparky, xeasy |
92.27 |
| 7 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×639 | C: -7.026 – 72.865
HC: -1.478 – 11.004
H: -1.493 – 11.003 |
600 |
646.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2237
sparky, xeasy |
1676
sparky, xeasy |
74.92 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×512 | N: 101.384 – 135.250
C: 42.612 – 72.381
HN: 4.773 – 11.431 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
164
sparky, xeasy |
97.04 |
| 9 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 101.384 – 135.250
C: 163.066 – 187.873
HN: 4.768 – 11.432 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
164
sparky, xeasy |
97.04 |
| 10 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 101.410 – 135.277
C: 42.612 – 72.381
HN: 4.767 – 11.431 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
84
sparky, xeasy |
82
sparky, xeasy |
97.62 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 101.334 – 135.302
H: 4.773 – 11.437 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
165
sparky, xeasy |
107
sparky, xeasy |
64.85 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | N: 101.651 – 135.386
HN: 4.763 – 11.407
H: -1.858 – 11.390 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2051
sparky, xeasy |
1442
sparky, xeasy |
70.31 |
1PQX (91 residues, PDB,
BMRB, 2003)
Reference:
Baran, M.C., Aramini, J.M., Xiao, R., Huang, Y.J., Acton, T.B., Shih, L., Montelione, G.T.. Solution Strucutre of the Hypothetical Staphylococcus Aureus protein SAV1430. Northest Strucutral Genomics Consortium target ZR18. (To be published).
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
488×2048 | C: -3.257 – 76.145
H: -1.873 – 11.459 |
600 |
3.98 |
C–H: spectrum, spectrum with peaks |
402
sparky, xeasy |
381
sparky, xeasy |
94.78 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 106.536 – 146.241
H: -1.883 – 11.449 |
600 |
4.00 |
C–H: spectrum, spectrum with peaks |
45
sparky, xeasy |
31
sparky, xeasy |
68.89 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×654×512 | C: -3.471 – 76.378
HC: -1.483 – 7.009
H: -1.861 – 11.451 |
600 |
660.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8071
sparky, xeasy |
7613
sparky, xeasy |
94.33 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 2.349 – 48.579
HC: 4.787 – 11.432
H: -1.869 – 11.443 |
600 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
402
sparky, xeasy |
337
sparky, xeasy |
83.83 |
| 5 |
CcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.211 – 135.986
C: 5.764 – 89.142
HN: 4.783 – 11.428 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
295
sparky, xeasy |
285
sparky, xeasy |
96.61 |
| 6 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | C: -3.410 – 76.282
HC: -0.626 – 10.178
H: -1.884 – 11.420 |
600 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1440
sparky, xeasy |
1353
sparky, xeasy |
93.96 |
| 7 |
HCcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.250 – 136.025
H: -0.624 – 10.192
HN: 4.787 – 11.432 |
600 |
256.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
421
sparky, xeasy |
401
sparky, xeasy |
95.25 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 103.250 – 136.025
C: 39.230 – 75.625
HN: -1.872 – 11.432 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
175
sparky, xeasy |
164
sparky, xeasy |
93.71 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×2048 | N: 103.250 – 136.025
C: 167.144 – 183.685
HN: -1.878 – 11.432 |
600 |
1024.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
99
sparky, xeasy |
82
sparky, xeasy |
82.83 |
| 10 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.250 – 136.025
C: 39.208 – 75.603
HN: 4.787 – 11.432 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
87
sparky, xeasy |
82
sparky, xeasy |
94.25 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
2048×1024 | N: 99.948 – 136.124
H: -2.262 – 11.896 |
600 |
8.00 |
N–H: spectrum, spectrum with peaks |
121
sparky, xeasy |
95
sparky, xeasy |
78.51 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.211 – 135.986
HN: 4.787 – 11.432
H: -1.869 – 11.443 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2418
sparky, xeasy |
2091
sparky, xeasy |
86.48 |
2L33 (91 residues, PDB,
BMRB, 2010)
Reference:
Liu, G., Janjua, H., Xiao, R., Acton, T.B., Everett, J., Montelione, G.T. Northeast Structural Genomics Consortium Target HR4527E. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.592 – 76.452
H: -2.212 – 11.729 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
411
sparky, xeasy |
378
sparky, xeasy |
91.97 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 112.648 – 142.618
H: -2.194 – 11.740 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
41
sparky, xeasy |
26
sparky, xeasy |
63.41 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×524×512 | C: 19.992 – 89.446
HC: -0.831 – 6.293
H: -2.203 – 11.770 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5612
sparky, xeasy |
5183
sparky, xeasy |
92.36 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×124×512 | C: 113.069 – 142.600
HC: 5.981 – 7.656
H: -1.704 – 11.271 |
800 |
16.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
311
sparky, xeasy |
236
sparky, xeasy |
75.88 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 104.608 – 130.526
C: 13.740 – 83.199
HN: 4.766 – 10.758 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
334
sparky, xeasy |
283
sparky, xeasy |
84.73 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 102.266 – 133.043
C: 13.800 – 83.259
HN: 4.766 – 10.758 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
190
sparky, xeasy |
166
sparky, xeasy |
87.37 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 29.784 – 53.409
C2: 4.590 – 79.004
H1: -2.192 – 11.741 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1477
sparky, xeasy |
1401
sparky, xeasy |
94.85 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 102.487 – 133.002
HN: 4.780 – 11.740
H: 0.291 – 6.267 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
236
sparky, xeasy |
199
sparky, xeasy |
84.32 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 102.067 – 133.006
H: 4.774 – 11.741 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
135
sparky, xeasy |
88
sparky, xeasy |
65.19 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×253×376 | N: 102.003 – 132.941
HN: 6.292 – 9.724
H: -0.262 – 9.992 |
800 |
48.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1750
sparky, xeasy |
1340
sparky, xeasy |
76.57 |
2KZV (92 residues, PDB,
BMRB, 2010)
Reference:
Yang, Y., Ramelot, T.A., Wang, D., Ciccosanti, C., Mao, L., Janjua, H., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of CV_0373(175-257) protein from Chromobacterium violaceum, Northeast Structural Genomics Consortium Target CvR118A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
449×449 | C: 10.003 – 80.003
H: -0.496 – 6.497 |
850 |
0.97 |
C–H: spectrum, spectrum with peaks |
404
sparky, xeasy |
398
sparky, xeasy |
98.51 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 112.117 – 142.000
H: 5.498 – 9.498 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
51
sparky, xeasy |
27
sparky, xeasy |
52.94 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×429×256 | C: 13.180 – 78.923
HC: -0.999 – 6.496
H: -1.173 – 10.780 |
850 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6584
sparky, xeasy |
6184
sparky, xeasy |
93.92 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×229×256 | C: 111.416 – 141.301
HC: 6.006 – 9.998
H: -1.173 – 10.780 |
850 |
59.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
558
sparky, xeasy |
370
sparky, xeasy |
66.31 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.323 – 128.838
C: 16.486 – 76.017
HN: 5.500 – 10.505 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
338
sparky, xeasy |
332
sparky, xeasy |
98.22 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.323 – 128.838
C: 16.486 – 76.017
HN: 5.495 – 10.500 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
192
sparky, xeasy |
190
sparky, xeasy |
98.96 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 8.454 – 78.188
C2: 8.458 – 78.184
H1: -1.003 – 6.496 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1391
sparky, xeasy |
1366
sparky, xeasy |
98.20 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3164
sparky, xeasy |
3114
sparky, xeasy |
98.42 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×286 | N: 105.323 – 128.838
C: 11.434 – 77.176
HN: 5.992 – 10.997 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
290
sparky, xeasy |
285
sparky, xeasy |
98.28 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×286×128 | N: 105.323 – 128.838
HN: 5.495 – 10.500
H: 0.561 – 6.514 |
600 |
18.06 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
241
sparky, xeasy |
238
sparky, xeasy |
98.76 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×400 | C: 13.298 – 83.023
HC: -0.189 – 5.788
H: -0.506 – 6.501 |
600 |
100.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1492
sparky, xeasy |
1462
sparky, xeasy |
97.99 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×400 | C: 13.294 – 83.028
HC: -0.189 – 5.788
H: -0.501 – 6.506 |
600 |
100.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2120
sparky, xeasy |
2084
sparky, xeasy |
98.30 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.323 – 128.838
C: 41.241 – 71.007
HN: 5.505 – 10.511 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
175
sparky, xeasy |
172
sparky, xeasy |
98.29 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 105.323 – 128.838
C: 168.250 – 183.910
HN: 5.500 – 10.505 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
99
sparky, xeasy |
85
sparky, xeasy |
85.86 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.323 – 128.838
C: 41.241 – 71.007
HN: 5.500 – 10.505 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
87
sparky, xeasy |
86
sparky, xeasy |
98.85 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×287 | N: 105.270 – 128.947
H: 5.498 – 10.506 |
850 |
1.23 |
N–H: spectrum, spectrum with peaks |
149
sparky, xeasy |
106
sparky, xeasy |
71.14 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×287×512 | N: 105.354 – 128.961
HN: 5.498 – 10.506
H: -1.197 – 10.780 |
850 |
144.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2336
sparky, xeasy |
1893
sparky, xeasy |
81.04 |
2KCT (94 residues, PDB,
BMRB, 2008)
Reference:
Aramini, J.M., Rossi, P., Lee, H., Lemak, A., Wang, H., Foote, E.L., Jiang, M., Xiao, R., Nair, R., Swapna, G.V.T., Acton, T.B., Rost, B., Everett, J.K., Montelione, G.T. Solution nmr structure of the ob-fold domain of heme chaperone ccme from desulfovibrio vulgaris. northeast structural genomics target dvr115g. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.840 – 76.771
H: -2.160 – 11.781 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
410
sparky, xeasy |
386
sparky, xeasy |
94.15 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 112.782 – 142.753
H: -1.855 – 11.490 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
43
sparky, xeasy |
29
sparky, xeasy |
67.44 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×552×440 | C: 19.908 – 89.771
HC: -1.002 – 6.503
H: -1.010 – 10.994 |
800 |
484.30 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7325
sparky, xeasy |
7052
sparky, xeasy |
96.27 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.818 – 142.701
HC: 4.814 – 11.774
H: -1.179 – 10.797 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
629
sparky, xeasy |
611
sparky, xeasy |
97.14 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.199 – 132.702
C: 8.685 – 88.540
HN: 4.804 – 11.461 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
332
sparky, xeasy |
302
sparky, xeasy |
90.96 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.218 – 132.721
C: 8.733 – 88.588
HN: 4.802 – 11.460 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
173
sparky, xeasy |
159
sparky, xeasy |
91.91 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×551 | C1: 31.846 – 55.752
C2: 9.108 – 78.834
H1: -1.012 – 6.496 |
600 |
140.25 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1465
sparky, xeasy |
1413
sparky, xeasy |
96.45 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.199 – 132.702
C: 12.246 – 85.050
HN: 4.802 – 11.459 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
278
sparky, xeasy |
262
sparky, xeasy |
94.24 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.199 – 132.702
HN: 4.802 – 11.459
H: -0.208 – 9.778 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
229
sparky, xeasy |
208
sparky, xeasy |
90.83 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×550 | C: 31.846 – 55.752
HC: -0.063 – 6.424
H: -1.003 – 6.492 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1478
sparky, xeasy |
1402
sparky, xeasy |
94.86 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | C: 31.846 – 55.752
HC: -0.063 – 6.424
H: -2.181 – 11.784 |
600 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2170
sparky, xeasy |
2090
sparky, xeasy |
96.31 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.608 – 134.390
C: 164.372 – 188.812
HN: 4.802 – 11.459 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
175
sparky, xeasy |
159
sparky, xeasy |
90.86 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.233 – 132.737
C: 42.698 – 74.466
HN: 4.802 – 11.459 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
87
sparky, xeasy |
80
sparky, xeasy |
91.95 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 103.159 – 133.130
H: 4.815 – 11.782 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
127
sparky, xeasy |
89
sparky, xeasy |
70.08 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×440 | N: 104.336 – 135.045
HN: 4.824 – 11.784
H: -1.010 – 10.994 |
800 |
221.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2114
sparky, xeasy |
1817
sparky, xeasy |
85.95 |
ADAR1 (94 residues)
Reference:
Not available
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×960 | C: 11.092 – 44.357
H: -1.201 – 6.276 |
900 |
1.88 |
C–H: spectrum, spectrum with peaks |
429
sparky, xeasy |
283
sparky, xeasy |
65.97 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×832×512 | C: 11.161 – 44.331
HC: -0.887 – 6.410
H: -0.574 – 10.006 |
900 |
416.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6511
sparky, xeasy |
4201
sparky, xeasy |
64.52 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×320×512 | C: 113.080 – 134.994
HC: 6.202 – 8.386
H: -0.578 – 10.001 |
600 |
160.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
679
sparky, xeasy |
145
sparky, xeasy |
21.35 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 104.380 – 133.153
C: 12.702 – 74.460
HN: 4.734 – 11.728 |
500 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
333
sparky, xeasy |
294
sparky, xeasy |
88.29 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×640 | N: 104.465 – 127.375
C: 13.260 – 73.025
HN: 5.994 – 10.993 |
600 |
160.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
198
sparky, xeasy |
175
sparky, xeasy |
88.38 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×1216 | C1: 10.287 – 72.045
C2: 10.316 – 72.074
H1: -0.935 – 6.479 |
600 |
304.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1548
sparky, xeasy |
997
sparky, xeasy |
64.41 |
| 7 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1216 | C: 10.251 – 72.009
HC: -0.588 – 9.991
H: -1.229 – 6.494 |
600 |
608.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2399
sparky, xeasy |
1265
sparky, xeasy |
52.73 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×608 | N: 104.459 – 127.369
C: 39.603 – 68.490
HN: 5.979 – 10.728 |
600 |
152.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
175
sparky, xeasy |
155
sparky, xeasy |
88.57 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×928 | N: 104.097 – 133.069
H: 4.743 – 11.995 |
600 |
3.63 |
N–H: spectrum, spectrum with peaks |
147
sparky, xeasy |
94
sparky, xeasy |
63.95 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×672×512 | N: 104.386 – 127.296
HN: 5.423 – 10.991
H: -0.581 – 9.998 |
900 |
336.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2084
sparky, xeasy |
1362
sparky, xeasy |
65.36 |
2FB7 (95 residues, PDB,
BMRB, 2005)
Reference:
Tyler, R.C., Song, J., Markley, J.L.. NMR Solution Structure of protein from Zebra Fish Dr.13312. (To be published).
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
215×860×338 | C: 10.032 – 76.918
HC: -0.494 – 6.503
H: -0.994 – 9.986 |
600 |
247.65 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
3766
sparky, xeasy |
2876
sparky, xeasy |
76.37 |
| 2 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 103.490 – 135.502
C: 8.960 – 88.658
HN: 4.782 – 13.115 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
332
sparky, xeasy |
295
sparky, xeasy |
88.86 |
| 3 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 103.502 – 135.514
C: 9.272 – 88.970
HN: 4.782 – 13.115 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
148
sparky, xeasy |
87.57 |
| 4 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×2048 | C1: -1.722 – 77.966
C2: -1.769 – 77.920
H1: -3.556 – 13.118 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1557
sparky, xeasy |
1263
sparky, xeasy |
81.12 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 103.505 – 135.517
C: 9.293 – 88.981
HN: 4.783 – 13.116 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
271
sparky, xeasy |
243
sparky, xeasy |
89.67 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | N: 103.505 – 135.517
HN: 4.779 – 13.112
H: -1.849 – 11.444 |
600 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
227
sparky, xeasy |
200
sparky, xeasy |
88.11 |
| 7 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
216×256×860 | C: 9.743 – 76.932
HC: -1.031 – 10.601
H: -0.509 – 6.488 |
600 |
186.47 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2318
sparky, xeasy |
1695
sparky, xeasy |
73.12 |
| 8 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 103.505 – 135.517
H: -3.509 – 13.107
HN: 4.780 – 13.113 |
600 |
128.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
387
sparky, xeasy |
321
sparky, xeasy |
82.95 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×1024 | N: 103.486 – 135.498
C: 167.992 – 182.109
HN: 4.774 – 13.107 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
88
sparky, xeasy |
72
sparky, xeasy |
81.82 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 103.378 – 135.516
H: 4.782 – 13.115 |
600 |
1.00 |
N–H: spectrum, spectrum with peaks |
130
sparky, xeasy |
77
sparky, xeasy |
59.23 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
116×431×423 | N: 105.002 – 133.989
HN: 6.502 – 10.005
H: -0.496 – 10.504 |
600 |
88.69 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1302
sparky, xeasy |
919
sparky, xeasy |
70.58 |
2MB0 (95 residues, PDB,
BMRB, 2013)
Reference:
Moursy, A., Allain, F.H., Clery, A. (2014). Characterization of the RNA recognition mode of hnRNP G extends its role in SMN2 splicing regulation. Nucleic Acids Res 42: 6659-6672
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
932×877 | C: 10.410 – 74.050
H: -0.626 – 6.203 |
900 |
3.28 |
C–H: spectrum, spectrum with peaks |
427
sparky, xeasy |
403
sparky, xeasy |
94.38 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×962×436 | C: 8.755 – 73.501
HC: -0.982 – 6.510
H: -0.369 – 10.656 |
900 |
448.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7159
sparky, xeasy |
6614
sparky, xeasy |
92.39 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×290×325 | C: 117.345 – 139.001
HC: 5.848 – 8.097
H: -0.325 – 9.800 |
700 |
26.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
610
sparky, xeasy |
353
sparky, xeasy |
57.87 |
| 4 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×511×259 | N: 100.907 – 130.790
C: 5.292 – 70.968
HN: 6.579 – 10.616 |
500 |
144.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
297
sparky, xeasy |
280
sparky, xeasy |
94.28 |
| 5 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×295×297 | N: 100.907 – 130.790
H: -0.515 – 6.385
HN: 6.283 – 10.915 |
500 |
95.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
437
sparky, xeasy |
427
sparky, xeasy |
97.71 |
| 6 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×106×509 | N: 100.919 – 130.802
C: 41.247 – 67.505
HN: 6.671 – 10.645 |
500 |
56.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
183
sparky, xeasy |
160
sparky, xeasy |
87.43 |
| 7 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1001×591 | N: 101.127 – 130.424
H: 6.166 – 10.766 |
900 |
2.50 |
N–H: spectrum, spectrum with peaks |
147
sparky, xeasy |
102
sparky, xeasy |
69.39 |
| 8 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×618×358 | N: 101.036 – 130.802
HN: 6.228 – 11.038
H: -0.374 – 10.801 |
900 |
115.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2300
sparky, xeasy |
1883
sparky, xeasy |
81.87 |
2L05 (95 residues, PDB,
BMRB, 2010)
Reference:
Aramini, J.M., Janjua, H., Ciccosanti, C., Shastry, R., Huang, Y.J., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T. Solution NMR Structure of the Ras-binding domain of Serine/threonine-protein kinase B-raf from Homo sapiens, Northeast Structural Genomics Consortium Target HR4694F. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.847 – 76.779
H: -2.150 – 11.790 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
488
sparky, xeasy |
439
sparky, xeasy |
89.96 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×588×512 | C: 29.809 – 53.762
HC: -1.496 – 6.500
H: -1.166 – 10.811 |
800 |
594.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8757
sparky, xeasy |
8416
sparky, xeasy |
96.11 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | C: 112.820 – 142.761
HC: 4.826 – 11.786
H: -1.164 – 10.812 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
323
sparky, xeasy |
303
sparky, xeasy |
93.81 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.809 – 135.672
C: 4.324 – 79.193
HN: 4.822 – 11.797 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
334
sparky, xeasy |
292
sparky, xeasy |
87.43 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.768 – 135.631
C: 4.419 – 79.273
HN: 4.822 – 11.797 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
186
sparky, xeasy |
165
sparky, xeasy |
88.71 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C1: 31.823 – 55.776
C2: 6.466 – 81.320
H1: -1.503 – 6.497 |
600 |
594.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1666
sparky, xeasy |
1597
sparky, xeasy |
95.86 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C: 31.865 – 55.818
HC: -0.428 – 6.558
H: -1.507 – 6.493 |
600 |
594.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1703
sparky, xeasy |
1602
sparky, xeasy |
94.07 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C: 31.823 – 55.776
HC: -0.428 – 6.558
H: -1.499 – 6.501 |
600 |
594.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2507
sparky, xeasy |
2402
sparky, xeasy |
95.81 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.809 – 135.672
C: 40.710 – 72.710
HN: 4.826 – 11.802 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
173
sparky, xeasy |
151
sparky, xeasy |
87.28 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 100.850 – 135.713
C: 167.791 – 189.790
HN: 4.822 – 11.797 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
96
sparky, xeasy |
83
sparky, xeasy |
86.46 |
| 11 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 100.809 – 135.672
C: 167.843 – 189.842
HN: 4.826 – 11.802 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
173
sparky, xeasy |
146
sparky, xeasy |
84.39 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.809 – 135.672
C: 40.774 – 72.722
HN: 4.822 – 11.797 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
86
sparky, xeasy |
75
sparky, xeasy |
87.21 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 105.211 – 132.106
HN: 4.823 – 11.783
H: -1.168 – 10.809 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2484
sparky, xeasy |
2074
sparky, xeasy |
83.49 |
2KJR (95 residues, PDB,
BMRB, 2009)
Reference:
Ramelot, T.A., Cort, J.R., Shastry, R., Ciccosanti, C., Jiang, M., Nair, R., Rost, B., Swapna, G., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the N-terminal Ubiquitin-like Domain from Tubulin-binding Cofactor B, CG11242, from Drosophila melanogaster. Northeast Structural Genomics Consortium Target FR629A (residues 8-92). To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
449×411 | C: 10.019 – 80.019
H: -0.006 – 6.002 |
850 |
0.88 |
C–H: spectrum, spectrum with peaks |
381
sparky, xeasy |
347
sparky, xeasy |
91.08 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×390×256 | C: 8.073 – 77.800
HC: -0.506 – 6.306
H: -0.955 – 10.600 |
850 |
102.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8021
sparky, xeasy |
7539
sparky, xeasy |
93.99 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×201×256 | C: 116.190 – 140.800
HC: 5.500 – 9.003
H: -0.955 – 10.600 |
850 |
14.06 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
440
sparky, xeasy |
341
sparky, xeasy |
77.50 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×128×462 | N: 103.500 – 135.000
C: 11.547 – 81.000
HN: 5.990 – 10.493 |
500 |
16.03 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
362
sparky, xeasy |
319
sparky, xeasy |
88.12 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×462 | N: 103.250 – 135.000
C: 11.547 – 81.000
HN: 5.990 – 10.493 |
500 |
29.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
216
sparky, xeasy |
195
sparky, xeasy |
90.28 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×385 | C1: 8.177 – 78.041
C2: 8.274 – 78.000
H1: -1.014 – 6.488 |
500 |
198.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1291
sparky, xeasy |
1223
sparky, xeasy |
94.73 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×330 | N: 103.088 – 134.962
C: 9.086 – 83.500
HN: 5.987 – 10.486 |
500 |
42.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
312
sparky, xeasy |
288
sparky, xeasy |
92.31 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×128×487 | C: 8.136 – 78.000
HC: -0.702 – 6.244
H: -2.022 – 7.473 |
500 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1867
sparky, xeasy |
1761
sparky, xeasy |
94.32 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×462 | N: 103.250 – 135.000
C: 41.328 – 70.859
HN: 6.007 – 10.510 |
500 |
16.03 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
189
sparky, xeasy |
166
sparky, xeasy |
87.83 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×232 | N: 103.250 – 135.000
C: 166.294 – 181.955
HN: 5.992 – 10.505 |
500 |
7.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
112
sparky, xeasy |
100
sparky, xeasy |
89.29 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×257 | N: 103.236 – 135.114
H: 6.008 – 10.491 |
850 |
0.31 |
N–H: spectrum, spectrum with peaks |
135
sparky, xeasy |
102
sparky, xeasy |
75.56 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×257×256 | N: 103.325 – 135.075
HN: 6.008 – 10.491
H: -0.955 – 10.600 |
850 |
34.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2541
sparky, xeasy |
2134
sparky, xeasy |
83.98 |
2M5O (97 residues, PDB,
BMRB, 2013)
Reference:
Liu, G., Xiao, R., Janjua, H., Hamilton, K., Shastry, R., Kohan, E., Acton, T.B., Everett, J.K., Pederson, K., Huang, Y.J., Montelione, G.T. Solution NMR Structure CTD domain of NFU1 Iron-Sulfur Cluster Scaffold Homolog from Homo sapiens, Northeast Structural Genomics Consortium (NESG) Target HR2876C. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×464×412 | C: 20.049 – 89.502
HC: -0.524 – 5.782
H: -0.797 – 10.441 |
800 |
97.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6304
sparky, xeasy |
5931
sparky, xeasy |
94.08 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×144×256 | C: 113.245 – 142.776
HC: 6.020 – 7.968
H: -1.641 – 11.308 |
800 |
12.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
291
sparky, xeasy |
225
sparky, xeasy |
77.32 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 102.755 – 133.513
C: 4.273 – 78.980
HN: 4.815 – 11.775 |
800 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
354
sparky, xeasy |
310
sparky, xeasy |
87.57 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.118 – 133.634
C: 4.420 – 79.127
HN: 4.815 – 11.775 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
208
sparky, xeasy |
187
sparky, xeasy |
89.90 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×1024 | C1: 29.680 – 53.492
C2: 4.566 – 78.980
H1: -2.159 – 11.775 |
800 |
64.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1419
sparky, xeasy |
1358
sparky, xeasy |
95.70 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 103.369 – 133.134
HN: 4.823 – 11.783
H: -0.413 – 6.559 |
800 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
249
sparky, xeasy |
217
sparky, xeasy |
87.15 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 103.118 – 133.634
C: 167.860 – 189.688
HN: 4.815 – 11.775 |
800 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
109
sparky, xeasy |
81
sparky, xeasy |
74.31 |
| 8 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 106.087 – 129.993
H: 4.798 – 11.765 |
800 |
1.00 |
N–H: spectrum, spectrum with peaks |
131
sparky, xeasy |
99
sparky, xeasy |
75.57 |
| 9 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×304×422 | N: 102.752 – 133.510
HN: 6.284 – 10.411
H: -0.524 – 10.983 |
800 |
67.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1932
sparky, xeasy |
1613
sparky, xeasy |
83.49 |
HDM2 (97 residues)
Reference:
Not available
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
64×880×405 | C: -1.192 – 28.339
HC: -0.809 – 5.321
H: -0.527 – 9.719 |
700 |
91.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5710
sparky, xeasy |
4211
sparky, xeasy |
73.75 |
| 2 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×647 | N: 100.376 – 131.207
C: 10.349 – 74.643
HN: 5.978 – 10.484 |
700 |
42.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
357
sparky, xeasy |
352
sparky, xeasy |
98.60 |
| 3 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×203×741 | C: 4.374 – 78.821
HC: -0.635 – 5.679
H: -0.355 – 5.404 |
700 |
79.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2622
sparky, xeasy |
1915
sparky, xeasy |
73.04 |
| 4 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×646 | N: 100.350 – 131.426
C: 46.198 – 74.487
HN: 5.986 – 10.485 |
700 |
85.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
183
sparky, xeasy |
180
sparky, xeasy |
98.36 |
| 5 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×97×534 | N: 100.346 – 131.421
C: 43.011 – 69.632
HN: 6.286 – 10.003 |
700 |
28.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
91
sparky, xeasy |
90
sparky, xeasy |
98.90 |
| 6 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
64×651×424 | N: 97.739 – 136.277
HN: 5.685 – 10.218
H: -0.808 – 9.920 |
700 |
74.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1796
sparky, xeasy |
1416
sparky, xeasy |
78.84 |
| 7 |
N15TOCSY
ucsf, pipe, .3D.16, .3D.param |
64×575×512 | N: 101.509 – 132.340
HN: 5.738 – 9.741
H: -2.501 – 11.754 |
700 |
74.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
610
sparky, xeasy |
438
sparky, xeasy |
71.80 |
2LNA (99 residues, PDB,
BMRB, 2011)
Reference:
Ramelot, T.A., Yang, Y., Sahu, I.D., Lee, H.W., Xiao, R., Lorigan, G.A., Montelione, G.T., Kennedy, M.A. (2013). NMR structure and MD simulations of the AAA protease intermembrane space domain indicates peripheral membrane localization within the hexaoligomer. FEBS Lett 587: 3522-3528
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×417 | C: 3.285 – 88.256
H: -0.486 – 6.007 |
850 |
1.83 |
C–H: spectrum, spectrum with peaks |
425
sparky, xeasy |
397
sparky, xeasy |
93.41 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×342 | C: 110.029 – 139.916
H: 5.004 – 10.001 |
850 |
0.42 |
C–H: spectrum, spectrum with peaks |
61
sparky, xeasy |
46
sparky, xeasy |
75.41 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×476×256 | C: 11.996 – 77.718
HC: -0.487 – 6.009
H: -2.167 – 11.782 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8127
sparky, xeasy |
7620
sparky, xeasy |
93.76 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×293×512 | C: 111.189 – 140.716
HC: 5.006 – 9.005
H: -1.402 – 10.972 |
600 |
38.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1032
sparky, xeasy |
893
sparky, xeasy |
86.53 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×285 | N: 104.098 – 133.981
C: 13.654 – 78.400
HN: 5.989 – 10.988 |
600 |
72.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
365
sparky, xeasy |
329
sparky, xeasy |
90.14 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×285 | N: 104.098 – 133.981
C: 13.984 – 78.476
HN: 5.989 – 10.988 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
218
sparky, xeasy |
201
sparky, xeasy |
92.20 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×427 | C1: -4.712 – 74.972
C2: -4.621 – 75.069
H1: -1.014 – 6.484 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1454
sparky, xeasy |
1395
sparky, xeasy |
95.94 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.940 – 33.987
C2: 13.940 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3591
sparky, xeasy |
3475
sparky, xeasy |
96.77 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×286 | N: 104.213 – 133.979
C: 11.246 – 80.973
HN: 5.992 – 10.997 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
327
sparky, xeasy |
309
sparky, xeasy |
94.50 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×286×256 | N: 104.221 – 133.988
HN: 5.992 – 10.997
H: 0.390 – 6.367 |
600 |
36.13 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
256
sparky, xeasy |
230
sparky, xeasy |
89.84 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | C: 3.001 – 72.702
HC: -0.410 – 6.563
H: -0.972 – 6.028 |
600 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1519
sparky, xeasy |
1433
sparky, xeasy |
94.34 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×383 | C: 0.067 – 69.938
HC: -0.689 – 6.284
H: -0.506 – 6.203 |
600 |
192.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2145
sparky, xeasy |
2055
sparky, xeasy |
95.80 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×286 | N: 104.213 – 133.979
H: -0.506 – 6.467
HN: 5.992 – 10.997 |
600 |
36.13 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
477
sparky, xeasy |
449
sparky, xeasy |
94.13 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 104.216 – 133.981
C: 167.227 – 180.930
HN: 6.002 – 11.008 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
113
sparky, xeasy |
104
sparky, xeasy |
92.04 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×285 | N: 104.215 – 133.981
C: 41.445 – 70.976
HN: 6.005 – 11.003 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
95
sparky, xeasy |
86
sparky, xeasy |
90.53 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×285 | N: 104.154 – 134.036
H: 6.011 – 11.012 |
600 |
0.35 |
N–H: spectrum, spectrum with peaks |
163
sparky, xeasy |
110
sparky, xeasy |
67.48 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×440×512 | N: 104.306 – 134.073
HN: 5.007 – 11.011
H: -0.793 – 10.388 |
850 |
114.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2814
sparky, xeasy |
2277
sparky, xeasy |
80.92 |
2LA6 (99 residues, PDB,
BMRB, 2011)
Reference:
Liu, G., Xiao, R., Janjua, H., Lee, H., Ciccosanti, C.T., Acton, T.B., Everett, J.K., Huang, Y.J., Montelione, G.T. Northeast Structural Genomics Consortium Target HR6430A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×524×512 | C: 20.048 – 89.497
HC: -0.799 – 6.325
H: -2.178 – 11.789 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6228
sparky, xeasy |
5805
sparky, xeasy |
93.21 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×264×256 | C: 113.242 – 142.773
HC: 4.656 – 8.238
H: -1.643 – 11.306 |
800 |
20.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
660
sparky, xeasy |
589
sparky, xeasy |
89.24 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 103.501 – 132.659
C: 13.790 – 83.250
HN: 4.804 – 11.462 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
360
sparky, xeasy |
304
sparky, xeasy |
84.44 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 103.501 – 132.659
C: 13.790 – 83.250
HN: 4.804 – 11.462 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
215
sparky, xeasy |
188
sparky, xeasy |
87.44 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | C1: 25.422 – 49.237
C2: 1.183 – 73.851
H1: -1.880 – 11.449 |
600 |
128.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1437
sparky, xeasy |
1371
sparky, xeasy |
95.41 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 103.501 – 132.659
C: 9.350 – 88.312
HN: 4.804 – 11.462 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
315
sparky, xeasy |
287
sparky, xeasy |
91.11 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×128 | N: 103.501 – 132.659
HN: 4.804 – 11.462
H: -0.134 – 9.794 |
600 |
16.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
247
sparky, xeasy |
206
sparky, xeasy |
83.40 |
| 8 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 103.501 – 132.659
C: 168.068 – 185.039
HN: 4.804 – 11.462 |
600 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
112
sparky, xeasy |
80
sparky, xeasy |
71.43 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.038 – 132.601
H: 4.797 – 11.462 |
600 |
2.00 |
N–H: spectrum, spectrum with peaks |
135
sparky, xeasy |
99
sparky, xeasy |
73.33 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×324×512 | N: 102.752 – 133.510
HN: 6.011 – 10.411
H: -2.178 – 11.789 |
800 |
88.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1916
sparky, xeasy |
1572
sparky, xeasy |
82.05 |
6FIP (99 residues, PDB,
BMRB, 2018)
Reference:
Oeemig, J.S., Ollila, O.H.S., Iwai, H. (2018). NMR structure of the C-terminal domain of TonB protein fromPseudomonas aeruginosa. PeerJ 6: e5412-e5412
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×1075 | C: 3.320 – 83.222
H: -1.003 – 5.998 |
600 |
2.23 |
C–H: spectrum, spectrum with peaks |
480
sparky, xeasy |
475
sparky, xeasy |
98.96 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1323×1024 | C: 3.816 – 83.188
HC: -0.502 – 6.499
H: -2.315 – 11.855 |
600 |
676.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5788
sparky, xeasy |
5460
sparky, xeasy |
94.33 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×746 | N: 102.735 – 137.008
C: 9.400 – 83.109
HN: 5.994 – 10.996 |
800 |
97.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
358
sparky, xeasy |
352
sparky, xeasy |
98.32 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×746 | N: 102.741 – 137.014
C: 9.394 – 83.103
HN: 6.001 – 11.003 |
800 |
97.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
198
sparky, xeasy |
196
sparky, xeasy |
98.99 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×746 | N: 102.768 – 137.042
C: 6.386 – 86.072
HN: 6.003 – 11.006 |
800 |
97.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
322
sparky, xeasy |
320
sparky, xeasy |
99.38 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×746×256 | N: 102.735 – 137.008
HN: 6.000 – 11.003
H: -2.377 – 11.945 |
800 |
97.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
247
sparky, xeasy |
244
sparky, xeasy |
98.79 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×172×1323 | C: -4.184 – 75.190
HC: -0.198 – 6.482
H: -0.504 – 6.497 |
600 |
122.52 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1848
sparky, xeasy |
1827
sparky, xeasy |
98.86 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×166×1323 | C: -4.580 – 74.794
HC: -0.491 – 6.500
H: -0.504 – 6.497 |
600 |
115.71 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2694
sparky, xeasy |
2653
sparky, xeasy |
98.48 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×746 | N: 102.741 – 137.014
C: 167.177 – 183.744
HN: 6.000 – 11.003 |
800 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
102
sparky, xeasy |
90
sparky, xeasy |
88.24 |
| 10 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×746 | N: 102.741 – 137.014
C: 165.169 – 183.767
HN: 6.000 – 11.003 |
800 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
185
sparky, xeasy |
180
sparky, xeasy |
97.30 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 102.489 – 136.999
H: 4.764 – 11.634 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
177
sparky, xeasy |
107
sparky, xeasy |
60.45 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×1024×856 | N: 102.600 – 137.008
HN: 4.768 – 11.637
H: -0.504 – 11.501 |
800 |
858.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2102
sparky, xeasy |
1537
sparky, xeasy |
73.12 |
| 13 |
N15TOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×746×256 | N: 102.708 – 136.982
HN: 5.993 – 10.996
H: -2.376 – 11.947 |
800 |
97.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
720
sparky, xeasy |
503
sparky, xeasy |
69.86 |
2LEA (100 residues, PDB,
BMRB, 2011)
Reference:
Daubner, G.M., Clery, A., Jayne, S., Stevenin, J., Allain, F.H. (2012). A syn-anti conformational difference allows SRSF2 to recognize guanines and cytosines equally well. EMBO J 31: 162-174
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 8.905 – 69.846
H: -3.363 – 12.588 |
900 |
8.00 |
C–H: spectrum, spectrum with peaks |
444
sparky, xeasy |
353
sparky, xeasy |
79.50 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
404×369 | C: 115.998 – 139.611
H: 6.083 – 8.962 |
600 |
0.61 |
C–H: spectrum, spectrum with peaks |
50
sparky, xeasy |
25
sparky, xeasy |
50.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×895×318 | C: 13.788 – 45.663
HC: -0.505 – 6.461
H: -0.118 – 9.806 |
900 |
280.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7272
sparky, xeasy |
5811
sparky, xeasy |
79.91 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×395×475 | C: 116.169 – 134.872
HC: 6.033 – 9.104
H: 0.095 – 9.353 |
900 |
52.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
686
sparky, xeasy |
329
sparky, xeasy |
47.96 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 106.177 – 130.982
C: 9.135 – 70.916
HN: 4.661 – 12.664 |
500 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
354
sparky, xeasy |
295
sparky, xeasy |
83.33 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×1024 | N: 103.760 – 133.525
C: 9.395 – 70.898
HN: 4.664 – 12.667 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
184
sparky, xeasy |
154
sparky, xeasy |
83.70 |
| 7 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×300×1140 | C: 13.406 – 45.281
HC: -0.160 – 6.263
H: -0.090 – 6.008 |
750 |
342.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2340
sparky, xeasy |
1727
sparky, xeasy |
73.80 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 97.611 – 132.475
C: 38.990 – 70.862
HN: 4.666 – 12.668 |
500 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
185
sparky, xeasy |
144
sparky, xeasy |
77.84 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 97.968 – 132.899
H: 4.658 – 10.647 |
900 |
2.00 |
N–H: spectrum, spectrum with peaks |
174
sparky, xeasy |
98
sparky, xeasy |
56.32 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×512 | N: 105.900 – 131.103
HN: 4.667 – 11.686
H: -0.669 – 10.010 |
900 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2475
sparky, xeasy |
1794
sparky, xeasy |
72.48 |
2LL8 (101 residues, PDB,
BMRB, 2011)
Reference:
Ramelot, T.A., Rossi, P., Forouhar, F., Lee, H.W., Yang, Y., Ni, S., Unser, S., Lew, S., Seetharaman, J., Xiao, R., Acton, T.B., Everett, J.K., Prestegard, J.H., Hunt, J.F., Montelione, G.T., Kennedy, M.A. (2012). Structure of a specialized acyl carrier protein essential for lipid A biosynthesis with very long-chain fatty acids in open and closed conformations. Biochemistry 51: 7239-7249
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
449×478 | C: 9.964 – 79.934
H: -0.997 – 5.992 |
850 |
1.02 |
C–H: spectrum, spectrum with peaks |
431
sparky, xeasy |
413
sparky, xeasy |
95.82 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×342 | C: 109.128 – 140.997
H: 4.983 – 9.980 |
850 |
0.42 |
C–H: spectrum, spectrum with peaks |
48
sparky, xeasy |
36
sparky, xeasy |
75.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478×256 | C: 10.590 – 76.313
HC: -0.997 – 5.992
H: -1.175 – 10.782 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9932
sparky, xeasy |
9556
sparky, xeasy |
96.21 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×342×256 | C: 111.242 – 142.000
HC: 5.000 – 9.996
H: -1.173 – 10.780 |
850 |
44.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
774
sparky, xeasy |
693
sparky, xeasy |
89.53 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×315 | N: 105.680 – 132.575
C: 14.026 – 78.518
HN: 5.997 – 11.512 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
382
sparky, xeasy |
356
sparky, xeasy |
93.19 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×315 | N: 105.680 – 132.575
C: 14.026 – 78.518
HN: 5.997 – 11.512 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
206
sparky, xeasy |
194
sparky, xeasy |
94.17 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×428 | C1: 4.632 – 70.503
C2: 4.761 – 70.503
H1: -1.024 – 6.475 |
600 |
214.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1555
sparky, xeasy |
1519
sparky, xeasy |
97.68 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×315 | N: 105.754 – 132.543
C: 13.232 – 78.974
HN: 5.997 – 11.512 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
318
sparky, xeasy |
305
sparky, xeasy |
95.91 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×479×128 | N: 105.770 – 132.665
HN: 5.000 – 12.004
H: -0.412 – 6.534 |
850 |
61.63 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
254
sparky, xeasy |
236
sparky, xeasy |
92.91 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×478 | C: 7.480 – 73.223
HC: -0.459 – 6.514
H: -1.006 – 5.983 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2219
sparky, xeasy |
2165
sparky, xeasy |
97.57 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×315 | N: 104.183 – 131.078
H: -0.681 – 6.292
HN: 6.002 – 11.517 |
600 |
80.75 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
444
sparky, xeasy |
424
sparky, xeasy |
95.50 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 105.754 – 132.543
C: 166.218 – 181.968
HN: 5.992 – 10.997 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
105
sparky, xeasy |
97
sparky, xeasy |
92.38 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×314 | N: 105.679 – 132.574
C: 41.241 – 71.007
HN: 6.018 – 11.515 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
97
sparky, xeasy |
91
sparky, xeasy |
93.81 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×285 | N: 105.612 – 132.559
H: 6.000 – 11.000 |
600 |
0.62 |
N–H: spectrum, spectrum with peaks |
135
sparky, xeasy |
107
sparky, xeasy |
79.26 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×322×256 | N: 105.901 – 132.690
HN: 5.997 – 11.008
H: -1.173 – 10.780 |
850 |
42.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3045
sparky, xeasy |
2726
sparky, xeasy |
89.52 |
2KPN (103 residues, PDB,
BMRB, 2009)
Reference:
Aramini, J.M., Wang, D., Ciccosanti, C.T., Janjua, H., Rost, B., Acton, T.B., Xiao, R., Swapna, G.V.T., Everett, J.K., Montelione, G.T. Solution NMR structure of a Bacterial Ig-like (Big_3) domain from Bacillus cereus. Northeast Structural Genomics Consortium target BcR147A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.314 – 81.240
H: -2.210 – 11.762 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
446
sparky, xeasy |
423
sparky, xeasy |
94.84 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×552×512 | C: 29.822 – 53.775
HC: -1.000 – 6.505
H: -1.171 – 10.805 |
800 |
561.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8649
sparky, xeasy |
8309
sparky, xeasy |
96.07 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | C: 112.823 – 142.764
HC: 4.811 – 11.771
H: -1.179 – 10.797 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
280
sparky, xeasy |
262
sparky, xeasy |
93.57 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 105.296 – 132.191
C: 4.288 – 79.157
HN: -2.189 – 11.776 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
378
sparky, xeasy |
344
sparky, xeasy |
91.01 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 105.265 – 132.159
C: 4.384 – 79.237
HN: -2.189 – 11.776 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
200
sparky, xeasy |
184
sparky, xeasy |
92.00 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×550 | C1: 31.787 – 55.740
C2: 6.387 – 81.240
H1: -1.004 – 6.490 |
600 |
561.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1605
sparky, xeasy |
1564
sparky, xeasy |
97.45 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×1024×512 | N: 105.265 – 132.159
HN: -2.189 – 11.776
H: -1.210 – 6.774 |
600 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
252
sparky, xeasy |
227
sparky, xeasy |
90.08 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×550 | C: 31.783 – 55.736
HC: -1.206 – 6.779
H: -0.996 – 6.498 |
600 |
561.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1586
sparky, xeasy |
1523
sparky, xeasy |
96.03 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×550 | C: 31.801 – 55.755
HC: -1.215 – 6.769
H: -1.004 – 6.490 |
600 |
561.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2344
sparky, xeasy |
2281
sparky, xeasy |
97.31 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 105.265 – 132.159
C: 40.694 – 72.694
HN: -2.189 – 11.776 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
197
sparky, xeasy |
178
sparky, xeasy |
90.36 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 105.265 – 132.159
C: 167.782 – 189.780
HN: -2.189 – 11.776 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
104
sparky, xeasy |
96
sparky, xeasy |
92.31 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 105.233 – 132.128
C: 167.808 – 189.806
HN: -2.189 – 11.776 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
197
sparky, xeasy |
180
sparky, xeasy |
91.37 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
2048×2048 | N: 101.154 – 136.137
H: -2.196 – 11.776 |
600 |
16.00 |
N–H: spectrum, spectrum with peaks |
128
sparky, xeasy |
97
sparky, xeasy |
75.78 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×1024×512 | N: 105.228 – 132.122
HN: -2.162 – 11.771
H: -1.179 – 10.798 |
800 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2368
sparky, xeasy |
2094
sparky, xeasy |
88.43 |
2K0M (104 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Xiao, R., Acton, T.B., Montelione, G.T. Solution NMR structure of the uncharacterized protein from Rhodospirillum rubrum gene locus Rru_A0810. Northeast Structural Genomics Target RrR43. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 5.886 – 85.758
H: -5.221 – 14.797 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
451
sparky, xeasy |
426
sparky, xeasy |
94.46 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×768×214 | C: 33.968 – 57.778
HC: -0.915 – 6.585
H: -1.438 – 11.044 |
800 |
82.88 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5550
sparky, xeasy |
5084
sparky, xeasy |
91.60 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×359×214 | C: 112.995 – 142.768
HC: 5.574 – 9.075
H: -1.450 – 11.033 |
800 |
40.36 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
617
sparky, xeasy |
539
sparky, xeasy |
87.36 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.614 – 131.188
C: 4.416 – 79.195
HN: 4.799 – 11.759 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
385
sparky, xeasy |
327
sparky, xeasy |
84.94 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.488 – 131.062
C: 4.555 – 79.222
HN: 4.799 – 11.759 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
208
sparky, xeasy |
180
sparky, xeasy |
86.54 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×551 | C1: 29.964 – 53.773
C2: 4.555 – 79.222
H1: -1.412 – 6.079 |
800 |
72.25 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1568
sparky, xeasy |
1511
sparky, xeasy |
96.36 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 105.841 – 132.626
HN: 4.795 – 11.755
H: 1.054 – 6.035 |
800 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
264
sparky, xeasy |
223
sparky, xeasy |
84.47 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×551 | C: 34.100 – 57.722
HC: 0.334 – 6.287
H: -1.412 – 6.079 |
800 |
18.06 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1653
sparky, xeasy |
1566
sparky, xeasy |
94.74 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×551 | C: 29.964 – 53.773
HC: 0.334 – 6.287
H: -1.416 – 6.075 |
800 |
36.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2371
sparky, xeasy |
2274
sparky, xeasy |
95.91 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 104.614 – 131.188
C: 42.007 – 71.765
HN: 4.795 – 11.755 |
800 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
199
sparky, xeasy |
170
sparky, xeasy |
85.43 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 104.614 – 131.188
C: 168.970 – 188.810
HN: 4.795 – 11.755 |
800 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
107
sparky, xeasy |
82
sparky, xeasy |
76.64 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 105.089 – 130.688
C: 168.970 – 188.810
HN: 4.795 – 11.755 |
800 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
199
sparky, xeasy |
164
sparky, xeasy |
82.41 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×614 | N: 100.234 – 135.101
H: 5.007 – 11.001 |
800 |
0.67 |
N–H: spectrum, spectrum with peaks |
164
sparky, xeasy |
94
sparky, xeasy |
57.32 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | N: 104.337 – 131.128
HN: 4.795 – 14.799
H: -2.669 – 12.275 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2012
sparky, xeasy |
1406
sparky, xeasy |
69.88 |
2K5V (104 residues, PDB,
BMRB, 2008)
Reference:
Aramini, J.M., Maglaqui, M., Jiang, M., Ciccosanti, C., Xiao, R., Nair, R., Everett, J.K., Swapna, G.VT., Acton, T.B., Montelione, G.T. SOLUTION NMR STRUCTURE OF the second OB-fold domain of replication protein A from Methanococcus maripaludis. NORTHEAST STRUCTURAL GENOMICS TARGET MrR110B. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 4.300 – 79.227
H: -2.181 – 11.791 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
512
sparky, xeasy |
482
sparky, xeasy |
94.14 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×551×440 | C: 20.022 – 89.885
HC: -1.001 – 6.490
H: -0.992 – 11.012 |
800 |
484.30 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9121
sparky, xeasy |
8898
sparky, xeasy |
97.56 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.856 – 142.738
HC: 4.820 – 11.780
H: -0.672 – 10.306 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
471
sparky, xeasy |
453
sparky, xeasy |
96.18 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.292 – 133.175
C: 4.304 – 79.158
HN: 4.816 – 11.792 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
386
sparky, xeasy |
360
sparky, xeasy |
93.26 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.257 – 133.139
C: 4.392 – 79.246
HN: 4.829 – 11.805 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
220
sparky, xeasy |
208
sparky, xeasy |
94.55 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×550 | C1: 31.796 – 55.749
C2: 6.439 – 81.293
H1: -0.998 – 6.497 |
600 |
561.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1690
sparky, xeasy |
1654
sparky, xeasy |
97.87 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.143 – 133.026
HN: 4.828 – 11.803
H: 0.324 – 6.312 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
270
sparky, xeasy |
252
sparky, xeasy |
93.33 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×551 | C: 31.814 – 55.721
HC: -0.059 – 6.428
H: -1.003 – 6.506 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1696
sparky, xeasy |
1642
sparky, xeasy |
96.82 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×551 | C: 31.796 – 55.749
HC: -0.063 – 6.424
H: -1.003 – 6.506 |
600 |
561.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2524
sparky, xeasy |
2470
sparky, xeasy |
97.86 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.292 – 133.175
C: 40.752 – 72.690
HN: 4.818 – 11.794 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
203
sparky, xeasy |
190
sparky, xeasy |
93.60 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.257 – 133.139
C: 167.773 – 189.815
HN: 4.845 – 11.821 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
115
sparky, xeasy |
109
sparky, xeasy |
94.78 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.292 – 133.175
C: 167.734 – 189.776
HN: 4.820 – 11.796 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
203
sparky, xeasy |
190
sparky, xeasy |
93.60 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.292 – 133.175
C: 40.827 – 72.765
HN: 4.828 – 11.804 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
101
sparky, xeasy |
95
sparky, xeasy |
94.06 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 103.160 – 133.131
H: 4.811 – 11.794 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
144
sparky, xeasy |
112
sparky, xeasy |
77.78 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×440 | N: 104.347 – 135.055
HN: 4.826 – 11.786
H: -1.008 – 10.996 |
800 |
221.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2643
sparky, xeasy |
2385
sparky, xeasy |
90.24 |
2MQL (105 residues, PDB,
BMRB, 2014)
Reference:
Blatter, M., Dunin-Horkawicz, S., Grishina, I., Maris, C., Thore, S., Maier, T., Bindereif, A., Bujnicki, J.M., Allain, F.H. (2015). The Signature of the Five-Stranded vRRM Fold Defined by Functional, Structural and Computational Analysis of the hnRNP L Protein. J Mol Biol 427: 3001-3022
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2560 | C: 10.559 – 75.495
H: -0.298 – 5.944 |
900 |
10.00 |
C–H: spectrum, spectrum with peaks |
435
sparky, xeasy |
404
sparky, xeasy |
92.87 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1280 | C: 116.028 – 139.006
H: 5.419 – 9.172 |
750 |
5.00 |
C–H: spectrum, spectrum with peaks |
41
sparky, xeasy |
25
sparky, xeasy |
60.98 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×2463×473 | C: 11.629 – 47.986
HC: -0.137 – 5.869
H: -0.203 – 9.938 |
900 |
1170.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6439
sparky, xeasy |
5907
sparky, xeasy |
91.74 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×509×480 | C: 115.171 – 135.014
HC: 6.108 – 8.842
H: -0.244 – 10.047 |
900 |
120.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
521
sparky, xeasy |
309
sparky, xeasy |
59.31 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×248×1477 | N: 104.677 – 127.089
C: 9.198 – 68.054
HN: 6.052 – 10.002 |
750 |
372.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
338
sparky, xeasy |
307
sparky, xeasy |
90.83 |
| 6 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×281×353 | N: 104.677 – 127.089
H: -0.216 – 5.800
HN: 6.098 – 9.867 |
750 |
108.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
481
sparky, xeasy |
429
sparky, xeasy |
89.19 |
| 7 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 100.307 – 132.979
C: 43.204 – 69.001
HN: 4.723 – 10.215 |
500 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
195
sparky, xeasy |
185
sparky, xeasy |
94.87 |
| 8 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
949×1525 | N: 100.432 – 133.760
H: 5.926 – 10.027 |
900 |
5.63 |
N–H: spectrum, spectrum with peaks |
145
sparky, xeasy |
110
sparky, xeasy |
75.86 |
| 9 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1453×441 | N: 106.665 – 127.501
HN: 5.915 – 10.160
H: -0.253 – 10.059 |
900 |
322.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2012
sparky, xeasy |
1701
sparky, xeasy |
84.54 |
2K75 (106 residues, PDB,
BMRB, 2008)
Reference:
Ramelot, T.A., Ding, K., Lee, D., Jiang, M., Ciccosanti, C., Xiao, R., Nair, R., Everett, J.K., Swapna, G., Acton, T.B., Rost, B., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the OB domain of Ta0387 from Thermoplasma acidophilum. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×308 | C: 3.119 – 83.041
H: -0.022 – 5.976 |
600 |
1.34 |
C–H: spectrum, spectrum with peaks |
453
sparky, xeasy |
453
sparky, xeasy |
100.00 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×206 | C: 112.603 – 137.506
H: 5.991 – 9.996 |
600 |
0.25 |
C–H: spectrum, spectrum with peaks |
44
sparky, xeasy |
30
sparky, xeasy |
68.18 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×479×256 | C: 6.994 – 84.656
HC: -1.004 – 6.000
H: -1.284 – 10.922 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5514
sparky, xeasy |
5300
sparky, xeasy |
96.12 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×309 | N: 102.248 – 132.014
C: 14.023 – 78.515
HN: 4.994 – 11.006 |
600 |
20.19 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
400
sparky, xeasy |
398
sparky, xeasy |
99.50 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×309 | N: 102.251 – 132.016
C: 13.962 – 78.454
HN: 4.994 – 11.006 |
600 |
20.19 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
231
sparky, xeasy |
231
sparky, xeasy |
100.00 |
| 6 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.578 – 33.948
C2: 13.581 – 33.951
H1: -3.674 – 9.649
H2: -0.463 – 6.479 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4019
sparky, xeasy |
4019
sparky, xeasy |
100.00 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×258 | N: 102.251 – 132.016
C: 16.445 – 75.977
HN: 5.989 – 11.006 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
353
sparky, xeasy |
353
sparky, xeasy |
100.00 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×232×128 | N: 102.253 – 132.019
HN: 5.990 – 10.499
H: 0.063 – 6.016 |
600 |
14.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
275
sparky, xeasy |
275
sparky, xeasy |
100.00 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×102×385 | C: 8.159 – 78.019
HC: -0.968 – 5.975
H: -0.993 – 6.502 |
600 |
81.28 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1597
sparky, xeasy |
1597
sparky, xeasy |
100.00 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×205×385 | C: 8.112 – 77.981
HC: -1.008 – 6.005
H: -0.999 – 6.497 |
600 |
162.42 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2309
sparky, xeasy |
2309
sparky, xeasy |
100.00 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×232 | N: 102.253 – 132.019
H: -0.673 – 6.273
HN: 5.988 – 10.497 |
600 |
14.50 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
505
sparky, xeasy |
505
sparky, xeasy |
100.00 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×309 | N: 102.250 – 132.017
C: 41.131 – 70.897
HN: 4.995 – 11.007 |
600 |
20.19 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
207
sparky, xeasy |
206
sparky, xeasy |
99.52 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×309 | N: 102.250 – 132.017
C: 165.763 – 182.497
HN: 4.995 – 11.008 |
600 |
10.69 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
119
sparky, xeasy |
116
sparky, xeasy |
97.48 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×308 | N: 102.183 – 132.137
H: 6.001 – 10.500 |
850 |
0.30 |
N–H: spectrum, spectrum with peaks |
163
sparky, xeasy |
125
sparky, xeasy |
76.69 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×376×256 | N: 102.297 – 132.133
HN: 5.006 – 10.500
H: -1.034 – 10.683 |
850 |
48.88 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1951
sparky, xeasy |
1639
sparky, xeasy |
84.01 |
2LTM (107 residues, PDB,
BMRB, 2012)
Reference:
Liu, G., Xiao, R., Janjua, H., Hamilton, K., Shastry, R., Kohan, E., Acton, T.B., Everett, J.K., Lee, H., Huang, Y.J., Montelione, G.T. Solution NMR Structure of NFU1 Iron-Sulfur Cluster Scaffold Homolog from Homo sapiens, Northeast Structural Genomics Consortium (NESG) Target HR2876B. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.654 – 76.517
H: -2.165 – 11.776 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
478
sparky, xeasy |
446
sparky, xeasy |
93.31 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024 | C: 112.786 – 142.551
H: 4.812 – 11.779 |
800 |
0.50 |
C–H: spectrum, spectrum with peaks |
68
sparky, xeasy |
54
sparky, xeasy |
79.41 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×604×472 | C: 20.048 – 89.501
HC: -1.615 – 6.599
H: -1.618 – 11.261 |
800 |
142.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6710
sparky, xeasy |
6259
sparky, xeasy |
93.28 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×224×256 | C: 113.243 – 142.775
HC: 5.332 – 8.369
H: -1.642 – 11.308 |
800 |
16.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
754
sparky, xeasy |
686
sparky, xeasy |
90.98 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.117 – 133.633
C: 4.272 – 78.979
HN: 4.808 – 11.768 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
377
sparky, xeasy |
321
sparky, xeasy |
85.15 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.117 – 133.633
C: 4.418 – 79.126
HN: 4.808 – 11.768 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
216
sparky, xeasy |
189
sparky, xeasy |
87.50 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 29.958 – 53.583
C2: 4.563 – 78.977
H1: -2.154 – 11.780 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1680
sparky, xeasy |
1614
sparky, xeasy |
96.07 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 103.367 – 132.898
HN: 4.814 – 11.775
H: -0.429 – 6.544 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
261
sparky, xeasy |
220
sparky, xeasy |
84.29 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 103.117 – 133.633
C: 167.944 – 189.601
HN: 4.808 – 11.768 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
110
sparky, xeasy |
81
sparky, xeasy |
73.64 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 102.572 – 133.512
H: 4.808 – 11.775 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
144
sparky, xeasy |
97
sparky, xeasy |
67.36 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×374×512 | N: 102.752 – 133.510
HN: 6.011 – 11.092
H: -2.164 – 11.803 |
800 |
96.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1940
sparky, xeasy |
1502
sparky, xeasy |
77.42 |
2KOB (108 residues, PDB,
BMRB, 2009)
Reference:
Ramelot, T.A., Lee, D., Ciccosanti, C., Jiang, M., Nair, R., Rost, B., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of CLOLEP_01837 (fragment 61-160) from Clostridium leptum. Northeast Structural Genomics Consortium Target QlR8A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×515 | C: 5.926 – 85.736
H: -1.986 – 7.014 |
850 |
1.13 |
C–H: spectrum, spectrum with peaks |
490
sparky, xeasy |
462
sparky, xeasy |
94.29 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×344×256 | C: 8.692 – 71.407
HC: -0.517 – 5.490
H: -2.164 – 11.786 |
850 |
89.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9994
sparky, xeasy |
9268
sparky, xeasy |
92.74 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×228×256 | C: 114.438 – 142.000
HC: 5.008 – 8.995
H: -2.165 – 11.780 |
600 |
15.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
865
sparky, xeasy |
678
sparky, xeasy |
78.38 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×314 | N: 106.010 – 129.915
C: 14.008 – 78.500
HN: 5.029 – 10.526 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
410
sparky, xeasy |
392
sparky, xeasy |
95.61 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×314 | N: 106.010 – 129.915
C: 14.008 – 78.500
HN: 5.029 – 10.526 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
248
sparky, xeasy |
239
sparky, xeasy |
96.37 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×371 | C1: 8.694 – 71.576
C2: 8.746 – 71.500
H1: -0.485 – 6.013 |
600 |
187.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1801
sparky, xeasy |
1694
sparky, xeasy |
94.06 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4420
sparky, xeasy |
4220
sparky, xeasy |
95.48 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×314×256 | N: 106.131 – 129.944
HN: 5.029 – 10.526
H: -0.175 – 5.802 |
600 |
40.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
282
sparky, xeasy |
267
sparky, xeasy |
94.68 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×344×256 | C: 6.881 – 76.774
HC: -0.517 – 5.490
H: -0.432 – 6.543 |
850 |
175.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1814
sparky, xeasy |
1688
sparky, xeasy |
93.05 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×344 | C: 6.881 – 76.774
HC: -0.432 – 6.543
H: -0.517 – 5.490 |
850 |
175.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1814
sparky, xeasy |
1688
sparky, xeasy |
93.05 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×122×343 | C: 8.744 – 71.503
HC: -0.175 – 5.497
H: -0.485 – 5.521 |
600 |
43.93 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2682
sparky, xeasy |
2498
sparky, xeasy |
93.14 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 106.131 – 129.944
C: 41.469 – 71.000
HN: 6.013 – 11.018 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
207
sparky, xeasy |
199
sparky, xeasy |
96.14 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×64×342 | N: 106.009 – 129.916
C: 166.294 – 181.955
HN: 5.029 – 11.018 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
125
sparky, xeasy |
120
sparky, xeasy |
96.00 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×342 | N: 106.131 – 129.944
C: 41.469 – 71.000
HN: 5.029 – 11.018 |
600 |
11.81 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
103
sparky, xeasy |
99
sparky, xeasy |
96.12 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×400 | N: 104.116 – 134.001
H: 5.029 – 12.016 |
850 |
0.39 |
N–H: spectrum, spectrum with peaks |
173
sparky, xeasy |
124
sparky, xeasy |
71.68 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×400×256 | N: 106.188 – 130.000
HN: 5.029 – 12.016
H: -1.654 – 11.295 |
850 |
50.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3382
sparky, xeasy |
2803
sparky, xeasy |
82.88 |
2KHD (108 residues, PDB,
BMRB, 2009)
Reference:
Ramelot, T.A., Cort, J.R., Wang, H., Ciccosanti, C., Jiang, M., Liu, J., Rost, B., Swapna, G.V.T., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of VC_A0919 from Vibrio cholerae. Northeast Structural Genomics Consortium Target VcR52. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×615 | C: 5.816 – 85.659
H: -1.999 – 6.998 |
850 |
1.34 |
C–H: spectrum, spectrum with peaks |
448
sparky, xeasy |
425
sparky, xeasy |
94.87 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×240 | C: 112.915 – 142.802
H: 5.503 – 9.005 |
850 |
0.23 |
C–H: spectrum, spectrum with peaks |
53
sparky, xeasy |
31
sparky, xeasy |
58.49 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×479×256 | C: 10.710 – 79.236
HC: -0.998 – 6.006
H: -0.409 – 10.050 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6998
sparky, xeasy |
6503
sparky, xeasy |
92.93 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×254×256 | C: 116.972 – 138.800
HC: 5.298 – 9.005
H: -0.409 – 10.050 |
850 |
31.88 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
716
sparky, xeasy |
554
sparky, xeasy |
77.37 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×376 | N: 104.204 – 133.110
C: 10.281 – 79.556
HN: 5.503 – 10.998 |
850 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
414
sparky, xeasy |
377
sparky, xeasy |
91.06 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×376 | N: 104.204 – 133.110
C: 10.935 – 80.210
HN: 5.503 – 10.998 |
850 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
230
sparky, xeasy |
205
sparky, xeasy |
89.13 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×385 | C1: 3.314 – 82.998
C2: 3.312 – 83.001
H1: -0.998 – 6.498 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1538
sparky, xeasy |
1484
sparky, xeasy |
96.49 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×257 | N: 106.162 – 135.057
C: 13.999 – 78.509
HN: 5.983 – 10.995 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
343
sparky, xeasy |
315
sparky, xeasy |
91.84 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×258×128 | N: 104.113 – 133.000
HN: 5.991 – 11.008
H: 0.066 – 6.019 |
600 |
34.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
282
sparky, xeasy |
256
sparky, xeasy |
90.78 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×113×460 | C: 31.038 – 54.944
HC: -1.032 – 5.969
H: -1.007 – 6.482 |
600 |
55.32 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1582
sparky, xeasy |
1503
sparky, xeasy |
95.01 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×225×460 | C: 30.978 – 54.885
HC: -1.031 – 5.969
H: -1.012 – 6.477 |
600 |
110.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2234
sparky, xeasy |
2139
sparky, xeasy |
95.75 |
| 12 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×206 | N: 104.113 – 133.000
H: -0.450 – 6.495
HN: 5.991 – 9.992 |
600 |
27.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
486
sparky, xeasy |
440
sparky, xeasy |
90.53 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×206 | N: 104.113 – 133.000
C: 41.164 – 70.930
HN: 5.986 – 9.991 |
600 |
27.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
213
sparky, xeasy |
194
sparky, xeasy |
91.08 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×274 | N: 104.317 – 133.110
C: 166.822 – 183.698
HN: 6.006 – 10.006 |
850 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
118
sparky, xeasy |
103
sparky, xeasy |
87.29 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×206 | N: 104.113 – 133.000
C: 41.234 – 71.000
HN: 5.991 – 9.992 |
600 |
27.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
106
sparky, xeasy |
97
sparky, xeasy |
91.51 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×301 | N: 104.147 – 133.035
H: 5.296 – 9.989 |
749 |
0.37 |
N–H: spectrum, spectrum with peaks |
153
sparky, xeasy |
106
sparky, xeasy |
69.28 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×329×256 | N: 104.317 – 133.110
HN: 5.196 – 10.002
H: -0.231 – 9.870 |
850 |
42.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2501
sparky, xeasy |
1995
sparky, xeasy |
79.77 |
2RN7 (108 residues, PDB,
BMRB, 2007)
Reference:
Ramelot, T.A., Cort, J.R., Semesi, A., Garcia, M., Yee, A., Arrowsmith, C.H., Kennedy, M.A. NMR solution structure of TnpE protein from Shigella flexneri. Northeast Structural Genomics Target SfR125. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
481×660 | C: -0.047 – 74.953
H: -2.002 – 6.994 |
749 |
1.52 |
C–H: spectrum, spectrum with peaks |
501
sparky, xeasy |
397
sparky, xeasy |
79.24 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×416×256 | C: 31.021 – 54.929
HC: -0.992 – 5.499
H: -0.960 – 10.595 |
749 |
104.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6960
sparky, xeasy |
5433
sparky, xeasy |
78.06 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×257×256 | C: 110.164 – 139.929
HC: 4.985 – 8.989
H: -0.968 – 10.586 |
749 |
34.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
359
sparky, xeasy |
191
sparky, xeasy |
53.20 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×246 | N: 101.239 – 134.893
C: 11.547 – 81.000
HN: 6.002 – 9.998 |
600 |
31.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
402
sparky, xeasy |
320
sparky, xeasy |
79.60 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×246 | N: 101.239 – 134.893
C: 11.547 – 81.000
HN: 6.002 – 9.998 |
600 |
31.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
232
sparky, xeasy |
192
sparky, xeasy |
82.76 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×461 | C1: 31.037 – 54.944
C2: 5.767 – 80.474
H1: -1.012 – 6.491 |
600 |
119.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1786
sparky, xeasy |
1384
sparky, xeasy |
77.49 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×369 | N: 101.239 – 134.893
C: 3.226 – 77.641
HN: 4.986 – 10.988 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
365
sparky, xeasy |
304
sparky, xeasy |
83.29 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×430×128 | N: 101.239 – 134.893
HN: 4.991 – 11.988
H: -1.138 – 6.800 |
600 |
55.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
280
sparky, xeasy |
222
sparky, xeasy |
79.29 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×576 | C: 31.009 – 54.916
HC: -1.012 – 6.487
H: -1.000 – 6.494 |
749 |
137.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1913
sparky, xeasy |
1453
sparky, xeasy |
75.95 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×460 | N: 101.239 – 134.893
C: 167.463 – 180.641
HN: 4.502 – 11.988 |
600 |
59.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
119
sparky, xeasy |
83
sparky, xeasy |
69.75 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×614 | N: 101.239 – 134.893
H: 5.999 – 10.998 |
600 |
0.67 |
N–H: spectrum, spectrum with peaks |
205
sparky, xeasy |
102
sparky, xeasy |
49.76 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×257×256 | N: 101.216 – 134.836
HN: 5.993 – 11.001
H: -0.861 – 10.505 |
749 |
68.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2862
sparky, xeasy |
1748
sparky, xeasy |
61.08 |
2LXU (108 residues, PDB,
BMRB, 2012)
Reference:
Ramelot, T.A., Yang, Y., Pederson, K., Shastry, R., Kohan, E., Janjua, H., Xiao, R., Acton, T.B., Everett, J.K., Prestegard, J.H., Montelione, G.T., Kennedy, M.A. Solution NMR Structure of the eukaryotic RNA recognition motif, RRM1, from the heterogeneous nuclear ribonucleoprotein H from Homo sapiens, Northeast Structural Genomics Consortium (NESG) Target HR8614A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×410 | C: 5.801 – 85.688
H: 0.003 – 5.996 |
850 |
1.79 |
C–H: spectrum, spectrum with peaks |
465
sparky, xeasy |
458
sparky, xeasy |
98.49 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×257 | C: 113.773 – 143.718
H: 5.505 – 9.006 |
850 |
0.63 |
C–H: spectrum, spectrum with peaks |
54
sparky, xeasy |
47
sparky, xeasy |
87.04 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×513×256 | C: 11.998 – 76.716
HC: -0.003 – 5.999
H: -0.924 – 10.529 |
850 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8386
sparky, xeasy |
8040
sparky, xeasy |
95.87 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×206×256 | C: 113.419 – 139.217
HC: 5.999 – 8.402
H: -0.924 – 10.529 |
850 |
27.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
596
sparky, xeasy |
533
sparky, xeasy |
89.43 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×257 | N: 106.155 – 127.983
C: 13.823 – 78.316
HN: 5.989 – 10.495 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
394
sparky, xeasy |
381
sparky, xeasy |
96.70 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×257 | N: 106.150 – 127.978
C: 13.971 – 78.463
HN: 5.989 – 10.495 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
229
sparky, xeasy |
224
sparky, xeasy |
97.82 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×427 | C1: 8.246 – 77.980
C2: 8.249 – 77.976
H1: -1.014 – 6.484 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1569
sparky, xeasy |
1556
sparky, xeasy |
99.17 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.705 – 9.618
H2: -0.494 – 6.449 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3805
sparky, xeasy |
3778
sparky, xeasy |
99.29 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×257 | N: 106.073 – 127.987
C: 11.519 – 80.972
HN: 5.979 – 10.486 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
338
sparky, xeasy |
333
sparky, xeasy |
98.52 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×258×128 | N: 106.158 – 127.986
HN: 5.981 – 10.495
H: -0.203 – 5.750 |
600 |
18.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
278
sparky, xeasy |
270
sparky, xeasy |
97.12 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×541 | C: 8.088 – 77.822
HC: -0.705 – 6.240
H: -2.014 – 7.493 |
600 |
70.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2397
sparky, xeasy |
2378
sparky, xeasy |
99.21 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×257 | N: 106.064 – 127.978
C: 169.107 – 182.918
HN: 5.989 – 10.496 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
119
sparky, xeasy |
116
sparky, xeasy |
97.48 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×330 | N: 106.094 – 128.073
H: 5.997 – 10.496 |
850 |
1.44 |
N–H: spectrum, spectrum with peaks |
167
sparky, xeasy |
121
sparky, xeasy |
72.46 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×385×512 | N: 106.244 – 128.073
HN: 5.999 – 10.500
H: -0.947 – 10.529 |
850 |
102.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2913
sparky, xeasy |
2412
sparky, xeasy |
82.80 |
2KIF (108 residues, PDB,
BMRB, 2009)
Reference:
Aramini, J.M., Tubbs, J.L., Kanugula, S., Rossi, P., Ertekin, A., Maglaqui, M., Hamilton, K., Ciccosanti, C.T., Jiang, M., Xiao, R., Soong, T.T., Rost, B., Acton, T.B., Everett, J.K., Pegg, A.E., Tainer, J.A., Montelione, G.T. (2010). Structural basis of O6-alkylguanine recognition by a bacterial alkyltransferase-like DNA repair protein. J Biol Chem 285: 13736-13741
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.844 – 76.776
H: -2.153 – 11.788 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
512
sparky, xeasy |
494
sparky, xeasy |
96.48 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×551×440 | C: 19.844 – 89.708
HC: -0.997 – 6.494
H: -0.513 – 11.491 |
800 |
484.30 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7492
sparky, xeasy |
7233
sparky, xeasy |
96.54 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.893 – 142.776
HC: 4.823 – 11.783
H: -1.167 – 10.809 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
581
sparky, xeasy |
569
sparky, xeasy |
97.93 |
| 4 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | N: 100.669 – 135.635
H: -2.154 – 11.787 |
800 |
8.00 |
N–H: spectrum, spectrum with peaks |
168
sparky, xeasy |
113
sparky, xeasy |
67.26 |
| 5 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×440 | N: 104.340 – 135.049
HN: 4.828 – 11.788
H: -0.490 – 11.514 |
800 |
221.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2209
sparky, xeasy |
1818
sparky, xeasy |
82.30 |
2KBN (109 residues, PDB,
BMRB, 2008)
Reference:
Kennedy, M.A., Ramelot, T.A., Ding, K., Magliqui, M., Jiang, M., Ciccosanti, C., Xiao, R., Lui, J., Everett, J.K., Swapna, G., Acton, T.B., Rost, B., Montelione, G.T. NMR structure of the OB domain of mm0293 from the archea methanosarcina mazei. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
475×513 | C: 5.909 – 79.972
H: -1.007 – 6.495 |
850 |
1.17 |
C–H: spectrum, spectrum with peaks |
495
sparky, xeasy |
460
sparky, xeasy |
92.93 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×257 | C: 110.059 – 140.000
H: 4.995 – 9.997 |
600 |
0.63 |
C–H: spectrum, spectrum with peaks |
47
sparky, xeasy |
34
sparky, xeasy |
72.34 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×479×256 | C: 7.030 – 84.692
HC: -1.007 – 5.997
H: -1.289 – 10.917 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9177
sparky, xeasy |
8542
sparky, xeasy |
93.08 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×206×256 | C: 112.514 – 140.305
HC: 6.002 – 9.005
H: -1.401 – 11.050 |
850 |
27.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
601
sparky, xeasy |
511
sparky, xeasy |
85.02 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×258 | N: 103.719 – 131.500
C: 14.008 – 78.500
HN: 5.991 – 11.007 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
408
sparky, xeasy |
386
sparky, xeasy |
94.61 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×232 | N: 103.719 – 131.500
C: 14.008 – 78.500
HN: 5.991 – 10.500 |
600 |
14.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
259
sparky, xeasy |
247
sparky, xeasy |
95.37 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.986
C2: 13.617 – 33.986
H1: -3.670 – 9.653
H2: -0.459 – 6.484 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4177
sparky, xeasy |
3920
sparky, xeasy |
93.85 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×232 | N: 103.719 – 131.500
C: 13.656 – 73.188
HN: 5.985 – 10.494 |
600 |
14.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
407
sparky, xeasy |
388
sparky, xeasy |
95.33 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×232×128 | N: 103.749 – 131.530
HN: 5.985 – 10.494
H: 0.066 – 6.019 |
600 |
14.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
282
sparky, xeasy |
267
sparky, xeasy |
94.68 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×205×385 | C: 8.134 – 78.003
HC: -1.009 – 6.003
H: -0.998 – 6.498 |
600 |
162.42 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2609
sparky, xeasy |
2402
sparky, xeasy |
92.07 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×232 | N: 103.719 – 131.500
H: -0.669 – 6.277
HN: 5.985 – 10.494 |
600 |
14.50 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
587
sparky, xeasy |
562
sparky, xeasy |
95.74 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×258 | N: 103.719 – 131.500
C: 41.328 – 70.859
HN: 5.985 – 11.002 |
600 |
9.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
211
sparky, xeasy |
200
sparky, xeasy |
94.79 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×258 | N: 103.719 – 131.500
C: 165.766 – 182.500
HN: 5.991 – 11.007 |
600 |
9.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
133
sparky, xeasy |
98
sparky, xeasy |
73.68 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×308 | N: 102.664 – 131.627
H: 6.002 – 10.500 |
850 |
0.67 |
N–H: spectrum, spectrum with peaks |
161
sparky, xeasy |
133
sparky, xeasy |
82.61 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×308×512 | N: 102.842 – 131.635
HN: 6.002 – 10.500
H: -1.303 – 10.927 |
850 |
80.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2940
sparky, xeasy |
2590
sparky, xeasy |
88.10 |
2MK2 (109 residues, PDB,
BMRB, 2014)
Reference:
Yang, Y., Ramelot, T.A., Janjua, H., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of N-terminal domain (SH2 domain) of human Inositol polyphosphate phosphatase-like protein 1 (INPPL1) (fragment 20-117), Northeast Structural Genomics Consortium Target HR9134A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×440 | C: 3.439 – 88.327
H: -1.191 – 6.496 |
850 |
0.86 |
C–H: spectrum, spectrum with peaks |
449
sparky, xeasy |
415
sparky, xeasy |
92.43 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 110.150 – 140.037
H: 5.498 – 9.498 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
61
sparky, xeasy |
31
sparky, xeasy |
50.82 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×458×256 | C: 13.268 – 78.990
HC: -1.009 – 6.993
H: -1.189 – 10.768 |
850 |
119.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7543
sparky, xeasy |
6967
sparky, xeasy |
92.36 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274×256 | C: 111.315 – 141.202
HC: 5.498 – 9.498
H: -1.175 – 10.782 |
850 |
72.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
634
sparky, xeasy |
363
sparky, xeasy |
57.26 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 101.250 – 133.000
C: 14.008 – 78.500
HN: 5.491 – 11.493 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
400
sparky, xeasy |
364
sparky, xeasy |
91.00 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×370 | N: 101.250 – 133.000
C: 14.008 – 78.500
HN: 5.491 – 11.986 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
227
sparky, xeasy |
210
sparky, xeasy |
92.51 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×370 | N: 101.250 – 133.000
C: 11.274 – 81.000
HN: 5.497 – 11.993 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
340
sparky, xeasy |
320
sparky, xeasy |
94.12 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×314×256 | N: 101.125 – 133.000
HN: 5.490 – 10.986
H: 0.041 – 7.014 |
600 |
80.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
280
sparky, xeasy |
253
sparky, xeasy |
90.36 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×238×584 | C: 10.335 – 76.077
HC: -0.998 – 5.483
H: -2.007 – 7.484 |
600 |
142.24 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2165
sparky, xeasy |
2023
sparky, xeasy |
93.44 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×314 | N: 101.250 – 133.000
C: 39.125 – 68.656
HN: 5.495 – 10.998 |
600 |
10.97 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
209
sparky, xeasy |
190
sparky, xeasy |
90.91 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×370 | N: 101.125 – 133.000
C: 169.116 – 182.927
HN: 5.497 – 11.993 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
118
sparky, xeasy |
95
sparky, xeasy |
80.51 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×64×285 | N: 101.125 – 133.000
C: 41.469 – 71.000
HN: 5.989 – 10.988 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
104
sparky, xeasy |
95
sparky, xeasy |
91.35 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×445 | N: 101.031 – 133.000
H: 5.493 – 11.997 |
600 |
1.93 |
N–H: spectrum, spectrum with peaks |
171
sparky, xeasy |
115
sparky, xeasy |
67.25 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×286×256 | N: 101.318 – 133.072
HN: 6.006 – 10.997
H: -0.893 – 11.063 |
850 |
36.13 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2646
sparky, xeasy |
2087
sparky, xeasy |
78.87 |
2K50 (110 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Xiao, R., Acton, T.B., Montelione, G.T. Solution NMR Structure of the replication Factor A Related Protein from Methanobacterium thermoautotrophicum. Northeast Structural Genomics Target TR91A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×896 | C: 8.405 – 83.217
H: -0.970 – 6.032 |
800 |
1.75 |
C–H: spectrum, spectrum with peaks |
529
sparky, xeasy |
499
sparky, xeasy |
94.33 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×552×256 | C: 29.957 – 53.770
HC: -1.501 – 6.003
H: -0.652 – 10.305 |
800 |
72.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12692
sparky, xeasy |
11718
sparky, xeasy |
92.33 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×221×256 | C: 113.006 – 142.772
HC: 6.012 – 9.008
H: -0.652 – 10.305 |
800 |
27.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
692
sparky, xeasy |
658
sparky, xeasy |
95.09 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.351 – 132.117
C: 4.661 – 79.090
HN: 4.852 – 11.828 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
398
sparky, xeasy |
368
sparky, xeasy |
92.46 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 102.585 – 132.117
C: 4.844 – 79.258
HN: 4.850 – 11.826 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
210
sparky, xeasy |
196
sparky, xeasy |
93.33 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×513 | C1: 31.949 – 55.761
C2: 6.173 – 80.880
H1: -1.004 – 5.985 |
600 |
68.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1982
sparky, xeasy |
1836
sparky, xeasy |
92.63 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 103.585 – 133.117
HN: 4.847 – 11.823
H: 0.350 – 6.326 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
273
sparky, xeasy |
254
sparky, xeasy |
93.04 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×513 | C: 31.949 – 55.761
HC: -0.412 – 6.037
H: -1.008 – 5.981 |
600 |
34.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3007
sparky, xeasy |
2755
sparky, xeasy |
91.62 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.281 – 133.046
C: 40.977 – 72.789
HN: 4.847 – 11.823 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
209
sparky, xeasy |
194
sparky, xeasy |
92.82 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 104.460 – 134.226
C: 167.889 – 189.801
HN: 4.841 – 11.817 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
110
sparky, xeasy |
96
sparky, xeasy |
87.27 |
| 11 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 105.460 – 135.226
C: 167.889 – 189.801
HN: 4.843 – 11.819 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
209
sparky, xeasy |
190
sparky, xeasy |
90.91 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.351 – 133.117
C: 40.928 – 72.689
HN: 4.847 – 11.823 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
104
sparky, xeasy |
97
sparky, xeasy |
93.27 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 100.767 – 135.630
H: 4.818 – 14.821 |
800 |
1.00 |
N–H: spectrum, spectrum with peaks |
180
sparky, xeasy |
104
sparky, xeasy |
57.78 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
64×512×512 | N: 103.599 – 133.130
HN: 4.823 – 11.783
H: -2.657 – 12.314 |
800 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3692
sparky, xeasy |
2764
sparky, xeasy |
74.86 |
2KL5 (110 residues, PDB,
BMRB, 2009)
Reference:
Liu, G., Hamilton, K., Xiao, R., Ciccosanti, C., Ho, C., Everett, E.K., Nair, R., Acton, A.B., Rost, B., Montelione, G.T. Solution NMR Structure of protein yutD from B.subtilis, Northeast Structural Genomics Consortium Target Target SR232. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.692 – 76.552
H: -2.199 – 11.741 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
482
sparky, xeasy |
374
sparky, xeasy |
77.59 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×1024 | C: 112.777 – 142.668
H: 4.781 – 11.748 |
800 |
1.00 |
C–H: spectrum, spectrum with peaks |
96
sparky, xeasy |
47
sparky, xeasy |
48.96 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×524×512 | C: 34.853 – 74.541
HC: -1.104 – 6.019
H: -2.207 – 11.765 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5794
sparky, xeasy |
4614
sparky, xeasy |
79.63 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×304×256 | C: 113.102 – 142.633
HC: 4.873 – 8.429
H: -1.179 – 10.775 |
800 |
20.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
798
sparky, xeasy |
413
sparky, xeasy |
51.75 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 101.945 – 134.342
C: 13.817 – 83.274
HN: 4.777 – 11.434 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
422
sparky, xeasy |
264
sparky, xeasy |
62.56 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 101.945 – 134.342
C: 13.834 – 83.291
HN: 4.757 – 11.415 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
250
sparky, xeasy |
142
sparky, xeasy |
56.80 |
| 7 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 101.651 – 134.586
H: 4.770 – 11.737 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
172
sparky, xeasy |
74
sparky, xeasy |
43.02 |
| 8 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×503×463 | N: 104.370 – 135.037
HN: 4.831 – 11.669
H: -0.866 – 11.766 |
800 |
116.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1984
sparky, xeasy |
1129
sparky, xeasy |
56.91 |
2LTA (110 residues, PDB,
BMRB, 2012)
Reference:
Koga, N., Tatsumi-Koga, R., Liu, G., Xiao, R., Acton, T.B., Montelione, G.T., Baker, D. (2012). Principles for designing ideal protein structures. Nature 491: 222-227
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×448×409 | C: 19.906 – 89.359
HC: -0.358 – 5.730
H: -0.609 – 10.547 |
800 |
91.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7720
sparky, xeasy |
7242
sparky, xeasy |
93.81 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
63×101×234 | C: 113.114 – 142.176
HC: 6.377 – 7.739
H: -0.820 – 11.013 |
800 |
7.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
192
sparky, xeasy |
137
sparky, xeasy |
71.35 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.243 – 132.634
C: 13.792 – 83.255
HN: 4.799 – 11.457 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
426
sparky, xeasy |
386
sparky, xeasy |
90.61 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.243 – 132.634
C: 13.820 – 83.283
HN: 4.800 – 11.458 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
232
sparky, xeasy |
213
sparky, xeasy |
91.81 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 29.783 – 53.408
C2: 4.676 – 79.090
H1: -2.156 – 11.778 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2321
sparky, xeasy |
2240
sparky, xeasy |
96.51 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×512 | N: 103.460 – 132.620
C: 9.206 – 88.171
HN: 4.805 – 11.463 |
600 |
16.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
412
sparky, xeasy |
385
sparky, xeasy |
93.45 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 103.505 – 133.036
HN: 4.825 – 11.785
H: -0.412 – 6.561 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
298
sparky, xeasy |
269
sparky, xeasy |
90.27 |
| 8 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 103.484 – 132.643
C: 168.045 – 185.017
HN: 4.800 – 11.458 |
600 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
118
sparky, xeasy |
99
sparky, xeasy |
83.90 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.073 – 132.637
H: 4.799 – 11.464 |
600 |
2.00 |
N–H: spectrum, spectrum with peaks |
171
sparky, xeasy |
110
sparky, xeasy |
64.33 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×287×410 | N: 102.493 – 133.431
HN: 6.378 – 10.274
H: -0.631 – 10.553 |
800 |
58.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2244
sparky, xeasy |
1729
sparky, xeasy |
77.05 |
2KIW (111 residues, PDB,
BMRB, 2009)
Reference:
Yang, Y., Ramelot, T.A., Belote, R.L., Foote, E.L., Janjua, H., Nair, R., Rost, B., Swapna, G., Acton, T.B., Xiao, R., Everett, J.K., Montelio, G.T., Kennedy, M.A. Solution NMR structure of the domain N-terminal to the integrase domain of SH1003 from Staphylococcus haemolyticus. Northeast Structural Genomics Consortium Target ShR105F (64-166). To be published.
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×615 | C: 3.333 – 88.250
H: -1.999 – 6.998 |
850 |
2.52 |
C–H: spectrum, spectrum with peaks |
516
sparky, xeasy |
507
sparky, xeasy |
98.26 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×228 | C: 110.059 – 140.000
H: 5.997 – 9.993 |
600 |
0.45 |
C–H: spectrum, spectrum with peaks |
65
sparky, xeasy |
51
sparky, xeasy |
78.46 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×401×256 | C: 6.991 – 76.718
HC: -0.996 – 6.008
H: -1.036 – 10.682 |
850 |
106.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8665
sparky, xeasy |
8209
sparky, xeasy |
94.74 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×201×512 | C: 111.534 – 141.300
HC: 5.500 – 9.003
H: -1.059 – 10.682 |
850 |
51.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
782
sparky, xeasy |
638
sparky, xeasy |
81.59 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×400 | N: 103.109 – 131.000
C: 11.547 – 81.000
HN: 4.998 – 12.006 |
600 |
50.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
428
sparky, xeasy |
408
sparky, xeasy |
95.33 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×400 | N: 103.109 – 131.000
C: 11.547 – 81.000
HN: 4.993 – 12.001 |
600 |
50.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
253
sparky, xeasy |
243
sparky, xeasy |
96.05 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 8.434 – 78.168
C2: 8.438 – 78.164
H1: -0.996 – 6.504 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1900
sparky, xeasy |
1882
sparky, xeasy |
99.05 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.617 – 33.987
C2: 13.940 – 33.987
H1: -0.474 – 6.469
H2: -3.685 – 9.638 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
3988
sparky, xeasy |
3961
sparky, xeasy |
99.32 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×400 | N: 106.846 – 131.250
C: 16.469 – 76.000
HN: 4.998 – 12.006 |
600 |
50.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
391
sparky, xeasy |
380
sparky, xeasy |
97.19 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×258×128 | N: 106.846 – 131.250
HN: 6.013 – 10.526
H: -0.161 – 5.793 |
600 |
34.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
288
sparky, xeasy |
274
sparky, xeasy |
95.14 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×401 | C: 6.991 – 76.718
HC: -0.365 – 6.607
H: -0.944 – 6.061 |
850 |
106.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1958
sparky, xeasy |
1931
sparky, xeasy |
98.62 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×127×542 | C: 8.379 – 77.839
HC: -0.868 – 6.514
H: -1.973 – 7.528 |
600 |
36.43 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2914
sparky, xeasy |
2887
sparky, xeasy |
99.07 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×229 | N: 106.851 – 131.255
H: -0.868 – 6.573
HN: 6.013 – 10.017 |
600 |
29.75 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
574
sparky, xeasy |
559
sparky, xeasy |
97.39 |
| 14 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×400 | N: 103.109 – 131.000
C: 41.164 – 70.930
HN: 4.993 – 12.001 |
600 |
50.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
215
sparky, xeasy |
205
sparky, xeasy |
95.35 |
| 15 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×343 | N: 103.219 – 131.000
C: 167.578 – 180.629
HN: 4.993 – 10.999 |
600 |
11.81 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
127
sparky, xeasy |
121
sparky, xeasy |
95.28 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×400 | N: 103.109 – 131.000
C: 41.233 – 71.002
HN: 4.998 – 12.006 |
600 |
50.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
107
sparky, xeasy |
102
sparky, xeasy |
95.33 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×400 | N: 106.767 – 131.243
H: 4.993 – 12.007 |
600 |
1.56 |
N–H: spectrum, spectrum with peaks |
181
sparky, xeasy |
124
sparky, xeasy |
68.51 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×478×256 | N: 106.932 – 131.336
HN: 5.005 – 11.994
H: -1.279 – 10.927 |
850 |
123.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3173
sparky, xeasy |
2576
sparky, xeasy |
81.18 |
2LVB (112 residues, PDB,
BMRB, 2012)
Reference:
Koga, N., Tatsumi-Koga, R., Liu, G., Xiao, R., Acton, T.B., Montelione, G.T., Baker, D. (2012). Principles for designing ideal protein structures. Nature 491: 222-227
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×524×512 | C: 20.273 – 89.726
HC: -1.071 – 6.053
H: -2.172 – 11.801 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7107
sparky, xeasy |
6673
sparky, xeasy |
93.89 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×264×256 | C: 113.193 – 142.724
HC: 5.467 – 9.049
H: -1.649 – 11.300 |
800 |
20.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
396
sparky, xeasy |
333
sparky, xeasy |
84.09 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.026 – 133.542
C: 4.375 – 79.082
HN: 4.812 – 11.772 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
422
sparky, xeasy |
375
sparky, xeasy |
88.86 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.026 – 133.542
C: 4.454 – 79.161
HN: 4.811 – 11.771 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
258
sparky, xeasy |
235
sparky, xeasy |
91.09 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 30.146 – 53.771
C2: 4.893 – 79.307
H1: -2.160 – 11.774 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1790
sparky, xeasy |
1744
sparky, xeasy |
97.43 |
| 6 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 103.026 – 133.542
C: 167.954 – 189.610
HN: 4.813 – 11.773 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
132
sparky, xeasy |
95
sparky, xeasy |
71.97 |
| 7 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.129 – 133.071
H: 4.806 – 11.773 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
179
sparky, xeasy |
121
sparky, xeasy |
67.60 |
| 8 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×288×431 | N: 102.536 – 133.474
HN: 6.421 – 10.330
H: -1.136 – 10.622 |
800 |
60.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2339
sparky, xeasy |
1810
sparky, xeasy |
77.38 |
2LND (112 residues, PDB,
BMRB, 2011)
Reference:
Liu, G., Koga, N., Koga, R., Xiao, R., Lee, H., Janjua, H., Kohan, E., Acton, T.B., Everett, J.K., Baker, D., Montelione, G.T. Northeast Structural Genomics Consortium Target OR134. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 76.788 – 146.651
H: -2.169 – 11.772 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
499
sparky, xeasy |
478
sparky, xeasy |
95.79 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024 | C: 112.987 – 142.752
H: 4.812 – 11.779 |
800 |
0.50 |
C–H: spectrum, spectrum with peaks |
41
sparky, xeasy |
28
sparky, xeasy |
68.29 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×564×512 | C: 20.270 – 89.723
HC: -1.345 – 6.324
H: -2.174 – 11.798 |
800 |
144.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7248
sparky, xeasy |
6793
sparky, xeasy |
93.72 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×124×256 | C: 113.195 – 142.726
HC: 6.282 – 7.957
H: -1.650 – 11.300 |
800 |
8.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
393
sparky, xeasy |
326
sparky, xeasy |
82.95 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.053 – 132.599
C: 4.405 – 79.112
HN: 4.815 – 11.775 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
422
sparky, xeasy |
371
sparky, xeasy |
87.91 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.057 – 132.604
C: 4.467 – 79.174
HN: 4.814 – 11.774 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
258
sparky, xeasy |
233
sparky, xeasy |
90.31 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 30.108 – 53.733
C2: 4.866 – 79.280
H1: -2.161 – 11.773 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1781
sparky, xeasy |
1735
sparky, xeasy |
97.42 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 104.057 – 132.604
HN: 4.815 – 11.775
H: -0.420 – 6.553 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
289
sparky, xeasy |
251
sparky, xeasy |
86.85 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 104.053 – 132.599
C: 167.905 – 189.561
HN: 4.815 – 11.775 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
132
sparky, xeasy |
95
sparky, xeasy |
71.97 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.659 – 132.602
H: 4.804 – 11.771 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
179
sparky, xeasy |
120
sparky, xeasy |
67.04 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×295×437 | N: 102.741 – 133.679
HN: 6.403 – 10.407
H: -1.218 – 10.704 |
800 |
70.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2384
sparky, xeasy |
1831
sparky, xeasy |
76.80 |
1WQU (114 residues, PDB,
BMRB, 2004)
Reference:
Scott, A., Pantoja-Uceda, D., Koshiba, S., Inoue, M., Kigawa, T., Terada, T., Shirouzu, M., Tanaka, A., Sugano, S., Yokoyama, S., Guntert, P. (2005). Solution structure of the Src homology 2 domain from the human feline sarcoma oncogene Fes. J Biomol NMR 31: 357-361
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1322 | C: 5.925 – 45.351
H: -0.996 – 8.002 |
800 |
2.58 |
C–H: spectrum, spectrum with peaks |
556
sparky, xeasy |
529
sparky, xeasy |
95.14 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1322×800 | C: 6.142 – 45.336
HC: -0.996 – 8.003
H: -2.261 – 11.672 |
800 |
516.41 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12393
sparky, xeasy |
11726
sparky, xeasy |
94.62 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: -0.093 – 74.590
HN: 5.201 – 10.198 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
400
sparky, xeasy |
373
sparky, xeasy |
93.25 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 0.317 – 75.000
HN: 5.201 – 10.198 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
232
sparky, xeasy |
219
sparky, xeasy |
94.40 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 0.142 – 74.825
HN: 5.202 – 10.199 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
370
sparky, xeasy |
354
sparky, xeasy |
95.68 |
| 6 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×367×256 | N: 101.310 – 133.947
HN: 5.201 – 10.198
H: -2.239 – 11.688 |
600 |
45.88 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
288
sparky, xeasy |
268
sparky, xeasy |
93.06 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×276×550 | C: 0.522 – 74.913
HC: -1.010 – 6.499
H: -0.991 – 6.505 |
600 |
74.12 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1829
sparky, xeasy |
1782
sparky, xeasy |
97.43 |
| 8 |
HCCHCOSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×112×223 | C: 109.172 – 139.063
HC: 5.805 – 7.997
H: 5.810 – 8.002 |
600 |
12.20 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
97
sparky, xeasy |
75
sparky, xeasy |
77.32 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×276×550 | C: 0.464 – 74.854
HC: -1.013 – 6.497
H: -0.998 – 6.498 |
600 |
74.12 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2651
sparky, xeasy |
2596
sparky, xeasy |
97.93 |
| 10 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
H: -0.819 – 10.248
HN: 5.198 – 10.195 |
600 |
45.88 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
540
sparky, xeasy |
518
sparky, xeasy |
95.93 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 35.777 – 67.733
HN: 5.201 – 10.198 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
211
sparky, xeasy |
196
sparky, xeasy |
92.89 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 161.587 – 183.593
HN: 5.209 – 10.206 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
121
sparky, xeasy |
98
sparky, xeasy |
80.99 |
| 13 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 161.587 – 183.593
HN: 5.202 – 10.199 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
211
sparky, xeasy |
196
sparky, xeasy |
92.89 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×256×367 | N: 101.310 – 133.947
C: 35.790 – 67.745
HN: 5.201 – 10.198 |
600 |
45.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
105
sparky, xeasy |
98
sparky, xeasy |
93.33 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×742 | N: 101.111 – 133.941
H: 5.205 – 10.253 |
800 |
1.45 |
N–H: spectrum, spectrum with peaks |
159
sparky, xeasy |
119
sparky, xeasy |
74.84 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×735×800 | N: 101.310 – 133.947
HN: 5.204 – 10.204
H: -2.257 – 11.676 |
800 |
287.11 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3331
sparky, xeasy |
2815
sparky, xeasy |
84.51 |
2KL6 (114 residues, PDB,
BMRB, 2009)
Reference:
Aramini, J.M., Lee, D., Ciccosanti, C., Hamilton, K., Nair, R., Rost, B., Acton, T.B., Xiao, R., Swapna, G.V.T., Everett, J.K., Montelione, G.T. Solution NMR structure of the CARDB domain of PF1109 from Pyrococcus furiosus. Northeast Structural Genomics Consortium target PfR193A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.835 – 76.767
H: -2.164 – 11.777 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
487
sparky, xeasy |
468
sparky, xeasy |
96.10 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 107.291 – 142.257
H: -2.160 – 11.781 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
55
sparky, xeasy |
43
sparky, xeasy |
78.18 |
| 3 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
256×1024×512 | C: 29.830 – 53.737
HC: -2.163 – 11.771
H: -1.175 – 10.801 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12891
sparky, xeasy |
12561
sparky, xeasy |
97.44 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.920 – 142.802
HC: 4.814 – 11.774
H: -1.176 – 10.800 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
855
sparky, xeasy |
835
sparky, xeasy |
97.66 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.805 – 135.668
C: 4.320 – 79.189
HN: 4.822 – 11.798 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
420
sparky, xeasy |
386
sparky, xeasy |
91.90 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.764 – 135.627
C: 4.327 – 79.181
HN: 4.818 – 11.793 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
254
sparky, xeasy |
238
sparky, xeasy |
93.70 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C1: 31.819 – 55.772
C2: 6.418 – 81.272
H1: -1.503 – 6.497 |
600 |
594.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1708
sparky, xeasy |
1671
sparky, xeasy |
97.83 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×507×512 | N: 100.764 – 135.627
HN: 4.814 – 11.789
H: 0.319 – 6.307 |
600 |
255.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
285
sparky, xeasy |
261
sparky, xeasy |
91.58 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C: 31.805 – 55.758
HC: -0.428 – 6.558
H: -1.503 – 6.497 |
600 |
594.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1703
sparky, xeasy |
1648
sparky, xeasy |
96.77 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×587 | C: 31.819 – 55.772
HC: -0.428 – 6.558
H: -1.503 – 6.497 |
600 |
594.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2447
sparky, xeasy |
2392
sparky, xeasy |
97.75 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.805 – 135.668
C: 40.763 – 72.763
HN: 4.818 – 11.793 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
217
sparky, xeasy |
200
sparky, xeasy |
92.17 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.764 – 135.627
C: 167.770 – 189.812
HN: 4.818 – 11.793 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
130
sparky, xeasy |
118
sparky, xeasy |
90.77 |
| 13 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 100.846 – 135.709
C: 167.839 – 189.838
HN: 4.818 – 11.793 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
217
sparky, xeasy |
198
sparky, xeasy |
91.24 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.846 – 135.709
C: 40.808 – 72.756
HN: 4.822 – 11.798 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
108
sparky, xeasy |
100
sparky, xeasy |
92.59 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | N: 100.660 – 135.626
H: -2.162 – 11.779 |
800 |
8.00 |
N–H: spectrum, spectrum with peaks |
157
sparky, xeasy |
125
sparky, xeasy |
79.62 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 105.199 – 132.094
HN: 4.815 – 11.775
H: -1.175 – 10.801 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3429
sparky, xeasy |
3114
sparky, xeasy |
90.81 |
6GT7 (115 residues, PDB,
BMRB, 2018)
Reference:
Boudet, J., Devillier, J.C., Wiegand, T., Salmon, L., Meier, B.H., Lipps, G., Allain, F.H. (2019). A Small Helical Bundle Prepares Primer Synthesis by Binding Two Nucleotides that Enhance Sequence-Specific Recognition of the DNA Template. Cell 176: 154-166.e13
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
239×814 | C: 7.198 – 72.220
H: -1.160 – 5.201 |
750 |
1.00 |
C–H: spectrum, spectrum with peaks |
584
sparky, xeasy |
412
sparky, xeasy |
70.55 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 100.078 – 150.048
H: 4.707 – 12.688 |
900 |
4.00 |
C–H: spectrum, spectrum with peaks |
45
sparky, xeasy |
38
sparky, xeasy |
84.44 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×804×355 | C: 8.799 – 47.507
HC: -0.974 – 5.277
H: -0.770 – 10.301 |
700 |
149.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9301
sparky, xeasy |
6216
sparky, xeasy |
66.83 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024×512 | C: 110.987 – 136.824
HC: 4.706 – 12.687
H: -3.263 – 12.682 |
900 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
605
sparky, xeasy |
493
sparky, xeasy |
81.49 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 97.137 – 134.986
C: 12.253 – 73.944
HN: 4.703 – 12.707 |
750 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
432
sparky, xeasy |
364
sparky, xeasy |
84.26 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 97.137 – 134.986
C: 12.180 – 73.992
HN: 4.698 – 12.702 |
750 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
185
sparky, xeasy |
78.72 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 97.137 – 134.986
C: 5.199 – 71.009
HN: 4.692 – 12.688 |
750 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
401
sparky, xeasy |
319
sparky, xeasy |
79.55 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 97.137 – 134.986
C: 38.269 – 70.032
HN: 4.702 – 12.706 |
750 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
219
sparky, xeasy |
185
sparky, xeasy |
84.47 |
| 9 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 97.122 – 134.971
C: 38.269 – 70.032
HN: 4.701 – 12.704 |
750 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
109
sparky, xeasy |
94
sparky, xeasy |
86.24 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 96.970 – 134.923
H: 4.706 – 12.669 |
700 |
4.00 |
N–H: spectrum, spectrum with peaks |
168
sparky, xeasy |
102
sparky, xeasy |
60.71 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×512 | N: 97.211 – 134.912
HN: 4.692 – 12.696
H: -3.277 – 12.677 |
750 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2729
sparky, xeasy |
1785
sparky, xeasy |
65.41 |
2JN8 (115 residues, PDB,
BMRB, 2006)
Reference:
Aramini, J.M., Cort, J.R., Ho, C.K., Cunningham, K., Ma, L.-C., Xiao, R., Liu, J., Baran, M.C., Swapna, G.V.T., Acton, T.B., Rost, B., Montelione, G.T.. Solution NMR structure of Q8ZRJ2 from Salmonella typhimurium. Northeast Structural Genomics target StR65. (To be published)
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: -4.851 – 75.071
H: -4.160 – 13.837 |
500 |
8.00 |
C–H: spectrum, spectrum with peaks |
513
sparky, xeasy |
482
sparky, xeasy |
93.96 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×1024 | C: 110.193 – 140.134
H: -4.155 – 13.871 |
749 |
2.00 |
C–H: spectrum, spectrum with peaks |
58
sparky, xeasy |
44
sparky, xeasy |
75.86 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×398×512 | C: 31.239 – 55.145
HC: -0.972 – 6.023
H: -0.869 – 10.609 |
749 |
204.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8065
sparky, xeasy |
7709
sparky, xeasy |
95.59 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 110.233 – 140.117
HC: 4.862 – 13.866
H: -0.882 – 10.596 |
749 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
688
sparky, xeasy |
642
sparky, xeasy |
93.31 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.777 – 134.598
C: 4.567 – 79.381
HN: 4.890 – 12.368 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
240
sparky, xeasy |
214
sparky, xeasy |
89.17 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C1: 23.163 – 47.069
C2: -2.162 – 72.545
H1: -0.935 – 6.063 |
500 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1811
sparky, xeasy |
1742
sparky, xeasy |
96.19 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 99.923 – 136.049
C: 11.187 – 83.984
HN: 4.847 – 11.087 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
370
sparky, xeasy |
337
sparky, xeasy |
91.08 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.758 – 134.579
HN: 4.860 – 11.523
H: -0.756 – 6.728 |
600 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
290
sparky, xeasy |
251
sparky, xeasy |
86.55 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×616 | C: 2.826 – 82.236
HC: -1.374 – 11.108
H: -0.986 – 6.524 |
600 |
627.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1883
sparky, xeasy |
1784
sparky, xeasy |
94.74 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×399 | C: 31.152 – 55.058
HC: 0.065 – 8.050
H: -0.935 – 6.063 |
500 |
204.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2725
sparky, xeasy |
2618
sparky, xeasy |
96.07 |
| 11 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | C: 99.934 – 152.874
HC: -1.388 – 11.093
H: 4.842 – 10.666 |
600 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
174
sparky, xeasy |
160
sparky, xeasy |
91.95 |
| 12 |
HCcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.568 – 137.694
H: -0.560 – 10.256
HN: 4.851 – 11.091 |
600 |
512.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
543
sparky, xeasy |
490
sparky, xeasy |
90.24 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.547 – 137.673
C: 39.371 – 75.769
HN: 4.849 – 11.089 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
217
sparky, xeasy |
191
sparky, xeasy |
88.02 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 97.446 – 138.499
C: 167.181 – 183.724
HN: 4.857 – 11.514 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
124
sparky, xeasy |
96
sparky, xeasy |
77.42 |
| 15 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.981 – 131.191
C: 166.103 – 181.982
HN: 4.845 – 13.830 |
500 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
217
sparky, xeasy |
191
sparky, xeasy |
88.02 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 101.547 – 137.673
C: 39.350 – 75.748
HN: 4.854 – 11.095 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
108
sparky, xeasy |
95
sparky, xeasy |
87.96 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 104.898 – 131.186
H: 4.838 – 13.832 |
500 |
4.00 |
N–H: spectrum, spectrum with peaks |
155
sparky, xeasy |
116
sparky, xeasy |
74.84 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.173 – 132.056
HN: 4.851 – 13.856
H: -1.138 – 10.839 |
749 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2737
sparky, xeasy |
2361
sparky, xeasy |
86.26 |
2K5D (116 residues, PDB,
BMRB, 2008)
Reference:
Aramini, J.M., Rossi, P., Zhao, L., Foote, E.L., Jiang, M., Xiao, R., Sharma, S., Swapna, G.VT., Nair, R., Everett, J.K., Acton, T.B., Rost, B., Montelione, G.T. SOLUTION NMR STRUCTURE OF SAG0934 from Streptococcus agalactiae. NORTHEAST STRUCTURAL GENOMICS TARGET SaR32[1-108]. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 5.466 – 80.351
H: -2.134 – 11.807 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
511
sparky, xeasy |
490
sparky, xeasy |
95.89 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 112.840 – 142.819
H: 4.848 – 11.815 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
48
sparky, xeasy |
36
sparky, xeasy |
75.00 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×551×440 | C: 20.027 – 89.886
HC: -1.008 – 6.484
H: -1.010 – 10.989 |
800 |
484.30 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9376
sparky, xeasy |
8991
sparky, xeasy |
95.89 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.919 – 142.810
HC: 4.853 – 11.813
H: -0.886 – 10.588 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
506
sparky, xeasy |
490
sparky, xeasy |
96.84 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.272 – 131.162
C: 4.414 – 79.340
HN: 4.863 – 11.823 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
438
sparky, xeasy |
408
sparky, xeasy |
93.15 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.272 – 131.162
C: 4.558 – 79.371
HN: 4.854 – 11.814 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
250
sparky, xeasy |
236
sparky, xeasy |
94.40 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×552 | C1: 29.838 – 53.788
C2: 4.470 – 79.283
H1: -1.007 – 6.498 |
800 |
561.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1828
sparky, xeasy |
1789
sparky, xeasy |
97.87 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.240 – 131.131
HN: 4.850 – 11.810
H: 1.096 – 6.087 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
298
sparky, xeasy |
277
sparky, xeasy |
92.95 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×552 | C: 29.899 – 53.802
HC: 0.352 – 6.340
H: -1.007 – 6.498 |
800 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2665
sparky, xeasy |
2608
sparky, xeasy |
97.86 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.304 – 131.194
C: 41.866 – 71.800
HN: 4.854 – 11.814 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
225
sparky, xeasy |
210
sparky, xeasy |
93.33 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 104.304 – 131.194
C: 168.861 – 188.779
HN: 4.861 – 11.821 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
128
sparky, xeasy |
121
sparky, xeasy |
94.53 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 104.272 – 131.162
C: 168.908 – 188.826
HN: 4.853 – 11.813 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
225
sparky, xeasy |
210
sparky, xeasy |
93.33 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 103.178 – 133.145
H: 4.852 – 11.819 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
178
sparky, xeasy |
125
sparky, xeasy |
70.22 |
| 14 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×504×440 | N: 104.347 – 135.055
HN: 4.968 – 11.819
H: -1.002 – 10.997 |
800 |
221.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2895
sparky, xeasy |
2393
sparky, xeasy |
82.66 |
2KD1 (118 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Lee, H., Xiao, R., Acton, T.B., Prestegard, J.H., Montelione, G.T. Solution NMR Structure of the Integrase-Like Domain from Bacillus cereus Ordered Locus BC_1272. Northeast Structural Genomics Consortium Target BcR268F. To be published.
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×666 | C: 6.141 – 80.995
H: -0.490 – 6.013 |
800 |
1.46 |
C–H: spectrum, spectrum with peaks |
568
sparky, xeasy |
531
sparky, xeasy |
93.49 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×478×422 | C: 31.721 – 55.533
HC: -0.485 – 6.012
H: -0.505 – 11.006 |
800 |
106.40 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
13472
sparky, xeasy |
12544
sparky, xeasy |
93.11 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×192×512 | C: 112.993 – 142.758
HC: 6.003 – 8.605
H: -2.181 – 11.791 |
800 |
48.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
917
sparky, xeasy |
728
sparky, xeasy |
79.39 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.799 – 130.588
C: 4.456 – 78.885
HN: 4.789 – 11.765 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
446
sparky, xeasy |
414
sparky, xeasy |
92.83 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.799 – 130.588
C: 4.464 – 78.878
HN: 4.788 – 11.764 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
258
sparky, xeasy |
244
sparky, xeasy |
94.57 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×513 | C1: 31.695 – 55.507
C2: 6.262 – 80.969
H1: -0.986 – 6.003 |
600 |
68.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2190
sparky, xeasy |
2082
sparky, xeasy |
95.07 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 103.799 – 130.588
HN: 4.788 – 11.764
H: 0.327 – 6.281 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
310
sparky, xeasy |
287
sparky, xeasy |
92.58 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C: 31.882 – 55.507
HC: -0.346 – 6.103
H: -2.200 – 11.765 |
600 |
32.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2136
sparky, xeasy |
1991
sparky, xeasy |
93.21 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×513 | C: 31.695 – 55.507
HC: -0.361 – 6.088
H: -0.981 – 6.008 |
600 |
34.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3266
sparky, xeasy |
3077
sparky, xeasy |
94.21 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.799 – 130.588
C: 40.648 – 72.460
HN: 4.788 – 11.764 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
229
sparky, xeasy |
213
sparky, xeasy |
93.01 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.799 – 130.588
C: 167.497 – 189.410
HN: 4.792 – 11.768 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
132
sparky, xeasy |
107
sparky, xeasy |
81.06 |
| 12 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
616×512 | N: 79.971 – 140.029
H: 4.788 – 11.764 |
600 |
1.20 |
N–H: spectrum, spectrum with peaks |
182
sparky, xeasy |
132
sparky, xeasy |
72.53 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×512 | N: 103.799 – 130.588
HN: 4.792 – 11.768
H: -2.190 – 11.783 |
600 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4118
sparky, xeasy |
3408
sparky, xeasy |
82.76 |
2LTL (119 residues, PDB,
BMRB, 2012)
Reference:
Liu, G., Xiao, R., Hamilton, K., Janjua, H., Shastry, R., Kohan, E., Acton, T.B., Everett, J.K., Lee, H., Huang, Y.J., Montelione, G.T. Solution NMR Structure of NifU-like protein from Saccharomyces cerevisiae, Northeast Structural Genomics Consortium (NESG) Target YR313A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.654 – 76.517
H: -2.161 – 11.780 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
546
sparky, xeasy |
508
sparky, xeasy |
93.04 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×1024 | C: 112.890 – 142.656
H: 4.813 – 11.780 |
800 |
0.50 |
C–H: spectrum, spectrum with peaks |
44
sparky, xeasy |
25
sparky, xeasy |
56.82 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×564×412 | C: 20.050 – 89.504
HC: -0.794 – 6.874
H: -0.795 – 10.443 |
800 |
117.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6855
sparky, xeasy |
6343
sparky, xeasy |
92.53 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×174×256 | C: 113.242 – 142.773
HC: 6.018 – 8.375
H: -1.643 – 11.306 |
800 |
12.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
375
sparky, xeasy |
284
sparky, xeasy |
75.73 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.604 – 133.135
C: 4.421 – 79.128
HN: 4.824 – 11.784 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
450
sparky, xeasy |
404
sparky, xeasy |
89.78 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 103.604 – 133.135
C: 4.421 – 79.128
HN: 4.817 – 11.777 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
280
sparky, xeasy |
257
sparky, xeasy |
91.79 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C1: 29.770 – 53.395
C2: 4.563 – 78.977
H1: -2.161 – 11.773 |
800 |
32.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1998
sparky, xeasy |
1898
sparky, xeasy |
94.99 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 103.600 – 133.131
HN: 4.820 – 11.780
H: -0.417 – 6.556 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
313
sparky, xeasy |
279
sparky, xeasy |
89.14 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.048 – 132.989
H: 4.810 – 11.777 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
179
sparky, xeasy |
133
sparky, xeasy |
74.30 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×324×412 | N: 102.752 – 133.510
HN: 6.011 – 10.411
H: -0.797 – 10.436 |
800 |
71.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2158
sparky, xeasy |
1756
sparky, xeasy |
81.37 |
2KVO (120 residues, PDB,
BMRB, 2010)
Reference:
Yang, Y., Ramelot, T.A., Cort, J.R., Wang, D., Ciccosanti, C., Hamilton, K., Nair, R., Rost, B., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. (2011). Solution NMR structure of photosystem II reaction center protein Psb28 from Synechocystis sp. Strain PCC 6803. Proteins 79: 340-344
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×581 | C: 10.925 – 76.797
H: -0.984 – 7.514 |
850 |
1.27 |
C–H: spectrum, spectrum with peaks |
534
sparky, xeasy |
514
sparky, xeasy |
96.25 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
445×229 | C: 113.011 – 139.027
H: 5.502 – 9.507 |
600 |
0.60 |
C–H: spectrum, spectrum with peaks |
64
sparky, xeasy |
45
sparky, xeasy |
70.31 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×429×256 | C: 10.186 – 77.920
HC: -1.012 – 6.483
H: -1.416 – 11.035 |
850 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8654
sparky, xeasy |
8115
sparky, xeasy |
93.77 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×287×512 | C: 111.416 – 141.301
HC: 4.993 – 10.001
H: -1.177 – 10.800 |
850 |
144.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
701
sparky, xeasy |
489
sparky, xeasy |
69.76 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 106.232 – 132.029
C: 12.598 – 80.067
HN: 5.994 – 10.999 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
442
sparky, xeasy |
420
sparky, xeasy |
95.02 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 106.232 – 132.029
C: 12.598 – 80.067
HN: 5.989 – 10.994 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
248
sparky, xeasy |
238
sparky, xeasy |
95.97 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C1: 8.423 – 78.157
C2: 8.427 – 78.153
H1: -1.017 – 5.973 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1866
sparky, xeasy |
1809
sparky, xeasy |
96.95 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.617 – 33.987
C2: 13.940 – 33.987
H1: -0.474 – 6.469
H2: -3.685 – 9.638 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4164
sparky, xeasy |
4046
sparky, xeasy |
97.17 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×286 | N: 106.232 – 132.029
C: 10.496 – 78.230
HN: 5.989 – 10.994 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
381
sparky, xeasy |
368
sparky, xeasy |
96.59 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×308×128 | N: 106.182 – 132.081
HN: 6.034 – 11.034
H: -0.369 – 7.569 |
600 |
40.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
307
sparky, xeasy |
292
sparky, xeasy |
95.11 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×461 | C: 8.323 – 78.054
HC: -0.985 – 6.516
H: -0.973 – 6.518 |
600 |
118.54 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1960
sparky, xeasy |
1886
sparky, xeasy |
96.22 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×461 | C: 8.328 – 78.049
HC: -1.098 – 6.840
H: -0.973 – 6.518 |
600 |
59.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2802
sparky, xeasy |
2708
sparky, xeasy |
96.65 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×286 | N: 106.224 – 132.022
H: -0.677 – 6.296
HN: 5.989 – 10.994 |
600 |
36.13 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
559
sparky, xeasy |
538
sparky, xeasy |
96.24 |
| 14 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 106.232 – 132.029
C: 41.222 – 70.988
HN: 5.994 – 10.999 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
231
sparky, xeasy |
220
sparky, xeasy |
95.24 |
| 15 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 106.232 – 132.029
C: 169.667 – 182.717
HN: 5.994 – 10.999 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
129
sparky, xeasy |
118
sparky, xeasy |
91.47 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 106.232 – 132.029
C: 41.222 – 70.988
HN: 5.994 – 10.999 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
115
sparky, xeasy |
110
sparky, xeasy |
95.65 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×342 | N: 106.155 – 132.130
H: 6.002 – 10.998 |
850 |
1.48 |
N–H: spectrum, spectrum with peaks |
175
sparky, xeasy |
130
sparky, xeasy |
74.29 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×342×256 | N: 106.223 – 132.122
HN: 6.002 – 10.998
H: -0.657 – 10.300 |
850 |
89.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2853
sparky, xeasy |
2383
sparky, xeasy |
83.53 |
1T0Y (120 residues, PDB,
BMRB, 2004)
Reference:
Lytle, B.L., Peterson, F.C., Qiu, S.H., Luo, M., Zhao, Q., Markley, J.L., Volkman, B.F. (2004). Solution Structure of a Ubiquitin-like Domain from Tubulin-binding Cofactor B. J Biol Chem 279: 46787-46793
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 22.544 – 63.919
H: -3.535 – 13.119 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
545
sparky, xeasy |
490
sparky, xeasy |
89.91 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×1024 | C: 110.562 – 143.562
H: 4.791 – 13.114 |
600 |
1.00 |
C–H: spectrum, spectrum with peaks |
42
sparky, xeasy |
21
sparky, xeasy |
50.00 |
| 3 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | C: 22.830 – 63.922
HC: -3.532 – 13.114
H: -1.114 – 10.742 |
600 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4632
sparky, xeasy |
4086
sparky, xeasy |
88.21 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×97×227 | C: 111.050 – 143.358
HC: 6.116 – 7.678
H: -0.184 – 10.324 |
600 |
15.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
172
sparky, xeasy |
82
sparky, xeasy |
47.67 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.917 – 135.545
C: 1.727 – 83.911
HN: 4.803 – 13.118 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
450
sparky, xeasy |
450
sparky, xeasy |
100.00 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.915 – 135.543
C: 2.380 – 84.565
HN: 4.803 – 13.118 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
385
sparky, xeasy |
379
sparky, xeasy |
98.44 |
| 7 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | C: 22.836 – 63.928
HC: -2.091 – 8.283
H: -2.107 – 8.287 |
600 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2985
sparky, xeasy |
2464
sparky, xeasy |
82.55 |
| 8 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.917 – 135.545
C: 33.726 – 74.818
HN: 4.802 – 13.117 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
235
sparky, xeasy |
100.00 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.917 – 135.545
C: 168.514 – 181.662
HN: 4.804 – 13.119 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
127
sparky, xeasy |
117
sparky, xeasy |
92.13 |
| 10 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.920 – 135.548
C: 168.517 – 181.665
HN: 4.804 – 13.119 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
235
sparky, xeasy |
100.00 |
| 11 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.917 – 135.545
C: 33.729 – 74.821
HN: 4.802 – 13.117 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
117
sparky, xeasy |
117
sparky, xeasy |
100.00 |
| 12 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 102.657 – 135.510
H: 4.794 – 13.117 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
169
sparky, xeasy |
129
sparky, xeasy |
76.33 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 102.884 – 135.512
HN: 4.800 – 13.116
H: -1.124 – 10.732 |
600 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1617
sparky, xeasy |
1372
sparky, xeasy |
84.85 |
| 14 |
N15TOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 102.807 – 135.435
HN: 4.796 – 13.111
H: -1.126 – 10.729 |
600 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
747
sparky, xeasy |
552
sparky, xeasy |
73.90 |
2KCD (120 residues, PDB,
BMRB, 2008)
Reference:
Ramelot, T.A., Ding, K., Chen, C.X., Jiang, M., Ciccosanti, C., Xiao, R., Liu, J., Baran, M.C., Swapna, G., Acton, T.B., Rost, B., Montelione, G.T., Kennedy, M.A. Solution NMR structure of SSP0047 from Staphylococcus saprophyticus. Northeast Structural Genomics Consortium Target SyR6. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 5.689 – 85.577
H: -2.679 – 12.311 |
850 |
4.00 |
C–H: spectrum, spectrum with peaks |
542
sparky, xeasy |
518
sparky, xeasy |
95.57 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
909×240 | C: 112.937 – 139.542
H: 5.570 – 9.072 |
850 |
0.94 |
C–H: spectrum, spectrum with peaks |
81
sparky, xeasy |
60
sparky, xeasy |
74.07 |
| 3 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
256×1024×256 | C: 2.421 – 82.075
HC: -2.687 – 12.302
H: -1.402 – 11.050 |
850 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6022
sparky, xeasy |
5567
sparky, xeasy |
92.44 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×240×256 | C: 111.738 – 139.300
HC: 5.503 – 9.005
H: -1.401 – 11.050 |
850 |
15.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
792
sparky, xeasy |
598
sparky, xeasy |
75.51 |
| 5 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×1024×256 | C: 31.056 – 54.962
HC: -3.210 – 12.791
H: -1.172 – 10.781 |
749 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5513
sparky, xeasy |
5188
sparky, xeasy |
94.10 |
| 6 |
CBCACOcaHA
ucsf, pipe, .3D.16, .3D.param |
128×128×309 | C: 6.147 – 80.556
CO: 166.958 – 180.849
HA: 0.986 – 6.995 |
600 |
20.19 |
C–CO: projection, projection with peaks
C–HA: projection, projection with peaks
CO–HA: projection, projection with peaks |
248
sparky, xeasy |
212
sparky, xeasy |
85.48 |
| 7 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×376 | N: 105.604 – 134.510
C: 12.945 – 70.963
HN: 5.997 – 11.492 |
850 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
451
sparky, xeasy |
417
sparky, xeasy |
92.46 |
| 8 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×376 | N: 105.604 – 134.510
C: 13.356 – 71.375
HN: 6.002 – 11.496 |
850 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
281
sparky, xeasy |
261
sparky, xeasy |
92.88 |
| 9 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×385 | C1: 8.271 – 78.003
C2: 8.274 – 78.000
H1: -1.003 – 6.492 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1959
sparky, xeasy |
1907
sparky, xeasy |
97.35 |
| 10 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.673 – 34.050
C2: 13.997 – 34.050
H1: -0.446 – 6.500
H2: -3.652 – 9.665 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4034
sparky, xeasy |
3940
sparky, xeasy |
97.67 |
| 11 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×309 | N: 105.513 – 134.400
C: 15.391 – 74.922
HN: 4.989 – 11.002 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
434
sparky, xeasy |
407
sparky, xeasy |
93.78 |
| 12 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×376×128 | N: 105.785 – 134.578
HN: 5.997 – 11.492
H: 0.421 – 6.257 |
850 |
24.44 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
318
sparky, xeasy |
295
sparky, xeasy |
92.77 |
| 13 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×609 | C: 8.226 – 77.951
HC: -1.032 – 6.469
H: -2.028 – 7.483 |
749 |
150.02 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1938
sparky, xeasy |
1862
sparky, xeasy |
96.08 |
| 14 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | C: 2.423 – 82.077
HC: -1.170 – 6.801
H: -2.687 – 12.302 |
850 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2798
sparky, xeasy |
2718
sparky, xeasy |
97.14 |
| 15 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×376 | N: 105.604 – 134.510
C: 42.277 – 68.179
HN: 6.002 – 11.496 |
850 |
97.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
229
sparky, xeasy |
212
sparky, xeasy |
92.58 |
| 16 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×376 | N: 105.717 – 134.510
C: 170.365 – 181.875
HN: 6.002 – 11.496 |
850 |
11.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
142
sparky, xeasy |
130
sparky, xeasy |
91.55 |
| 17 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×308 | N: 105.811 – 134.266
C: 41.211 – 70.992
HN: 4.974 – 10.984 |
600 |
20.19 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
114
sparky, xeasy |
106
sparky, xeasy |
92.98 |
| 18 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×376 | N: 105.519 – 134.510
H: 6.002 – 11.496 |
850 |
1.47 |
N–H: spectrum, spectrum with peaks |
174
sparky, xeasy |
133
sparky, xeasy |
76.44 |
| 19 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×376×256 | N: 105.717 – 134.510
HN: 6.002 – 11.496
H: -1.402 – 11.050 |
850 |
48.88 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2948
sparky, xeasy |
2503
sparky, xeasy |
84.91 |
2KRT (121 residues, PDB,
BMRB, 2009)
Reference:
Mani, R., Swapna, G., Janjua, H., Ciccosanti, C., Huang, Y., Patel, D., Xiao, R., Acton, T., Everett, J., Montelione, G.T. NMR Solution Structure of a Conserved Hypothetical Membrane Lipoprotein obtained from Ureaplasma parvum : Northeast Structural Genomics Consortium Target UuR17A (139-239). To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×999 | C: -2.023 – 77.403
H: -0.509 – 5.992 |
600 |
2.18 |
C–H: spectrum, spectrum with peaks |
555
sparky, xeasy |
486
sparky, xeasy |
87.57 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×515×512 | C: 20.058 – 89.784
HC: -0.499 – 6.502
H: -2.173 – 11.800 |
800 |
264.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
6652
sparky, xeasy |
5439
sparky, xeasy |
81.76 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | C: 113.950 – 141.841
HC: 4.816 – 11.776
H: -2.143 – 11.802 |
800 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
710
sparky, xeasy |
415
sparky, xeasy |
58.45 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 101.587 – 134.369
C: 8.760 – 88.460
HN: 4.786 – 11.443 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
456
sparky, xeasy |
420
sparky, xeasy |
92.11 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 100.004 – 136.064
C: 12.357 – 85.020
HN: 4.793 – 11.437 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
315
sparky, xeasy |
254
sparky, xeasy |
80.63 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×269 | C1: 25.633 – 49.541
C2: 1.263 – 73.927
H1: -0.503 – 6.480 |
600 |
68.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2028
sparky, xeasy |
1738
sparky, xeasy |
85.70 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 100.004 – 136.064
C: 12.325 – 84.989
HN: 4.801 – 11.445 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
470
sparky, xeasy |
385
sparky, xeasy |
81.91 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 99.005 – 135.136
HN: 4.788 – 11.446
H: -0.222 – 9.764 |
600 |
512.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
325
sparky, xeasy |
301
sparky, xeasy |
92.62 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×269 | C: 33.625 – 57.533
HC: -1.846 – 11.442
H: -0.496 – 6.487 |
600 |
68.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3053
sparky, xeasy |
2378
sparky, xeasy |
77.89 |
| 10 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | N: 99.026 – 135.157
H: -0.225 – 9.761
HN: 4.790 – 11.448 |
600 |
512.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
703
sparky, xeasy |
540
sparky, xeasy |
76.81 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 101.639 – 134.421
C: 34.811 – 74.445
HN: 4.797 – 11.770 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
233
sparky, xeasy |
216
sparky, xeasy |
92.70 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×256 | N: 100.004 – 136.064
C: 167.986 – 185.159
HN: 4.799 – 11.443 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
160
sparky, xeasy |
99
sparky, xeasy |
61.88 |
| 13 |
HNHA
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 99.229 – 138.564
H: -2.163 – 11.783
HN: 4.781 – 11.767 |
500 |
128.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
366
sparky, xeasy |
267
sparky, xeasy |
72.95 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×512 | N: 101.242 – 135.109
H: 4.816 – 11.776 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
186
sparky, xeasy |
130
sparky, xeasy |
69.89 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×256 | N: 102.813 – 133.522
HN: 4.813 – 11.773
H: -2.147 – 11.798 |
800 |
128.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2214
sparky, xeasy |
1751
sparky, xeasy |
79.09 |
2LFI (122 residues, PDB,
BMRB, 2011)
Reference:
Feldmann, E.A., Ramelot, T.A., Yang, Y.A., Wang, H., Ciccosanti, C., Janjua, H., Nair, R., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of a MucBP domain (fragment 187-294) of the protein LBA1460 from Lactobacillus acidophilus, Northeast structural genomics consortium target LaR80A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×615 | C: 5.911 – 85.798
H: -2.005 – 6.992 |
850 |
2.52 |
C–H: spectrum, spectrum with peaks |
534
sparky, xeasy |
508
sparky, xeasy |
95.13 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×286 | C: 115.127 – 145.097
H: 4.997 – 10.002 |
600 |
1.23 |
C–H: spectrum, spectrum with peaks |
59
sparky, xeasy |
33
sparky, xeasy |
55.93 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×401×256 | C: 10.964 – 76.816
HC: -1.003 – 6.001
H: -1.155 – 10.802 |
850 |
204.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9700
sparky, xeasy |
8948
sparky, xeasy |
92.25 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×201×256 | C: 111.532 – 141.302
HC: 5.500 – 9.003
H: -0.659 – 10.302 |
850 |
25.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
431
sparky, xeasy |
230
sparky, xeasy |
53.36 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×258 | N: 105.623 – 134.509
C: 13.376 – 79.119
HN: 5.998 – 10.511 |
600 |
68.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
455
sparky, xeasy |
433
sparky, xeasy |
95.16 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 2.516 – 68.258
C2: 2.438 – 68.181
H1: -1.010 – 6.489 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1889
sparky, xeasy |
1793
sparky, xeasy |
94.92 |
| 7 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×542 | C: 10.277 – 76.148
HC: -0.173 – 5.803
H: -2.000 – 7.501 |
600 |
272.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1928
sparky, xeasy |
1826
sparky, xeasy |
94.71 |
| 8 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×542 | C: 10.277 – 76.148
HC: -0.173 – 5.803
H: -1.997 – 7.505 |
600 |
272.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2784
sparky, xeasy |
2646
sparky, xeasy |
95.04 |
| 9 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 105.623 – 134.509
C: 41.246 – 71.011
HN: 5.991 – 10.504 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
233
sparky, xeasy |
223
sparky, xeasy |
95.71 |
| 10 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×64×258 | N: 105.623 – 134.509
C: 168.300 – 183.960
HN: 5.991 – 10.504 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
138
sparky, xeasy |
124
sparky, xeasy |
89.86 |
| 11 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 105.623 – 134.509
C: 41.339 – 71.105
HN: 5.991 – 10.504 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
116
sparky, xeasy |
112
sparky, xeasy |
96.55 |
| 12 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×401 | N: 105.660 – 134.601
H: 4.993 – 11.997 |
850 |
0.88 |
N–H: spectrum, spectrum with peaks |
179
sparky, xeasy |
137
sparky, xeasy |
76.54 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×401×512 | N: 105.818 – 134.589
HN: 4.993 – 11.997
H: -1.178 – 10.802 |
850 |
106.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3246
sparky, xeasy |
2690
sparky, xeasy |
82.87 |
2JQN (122 residues, PDB,
BMRB, 2007)
Reference:
Aramini, J.M., Rossi, P., Moseley, H.N.B., Wang, D., Nwosu, C., Cunningham, K., Ma, L., Xiao, R., Liu, J., Baran, M.C., Swapna, G.V.T., Acton, T.B., Rost, B., Montelione, G.T.. Solution NMR structure of CC0527 from Caulobacter crescentus. (To be published)
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 1.859 – 81.787
H: -3.180 – 12.834 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
507
sparky, xeasy |
486
sparky, xeasy |
95.86 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×2048 | C: 107.963 – 147.662
H: -2.160 – 11.781 |
800 |
1.00 |
C–H: spectrum, spectrum with peaks |
61
sparky, xeasy |
42
sparky, xeasy |
68.85 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×552×512 | C: 33.834 – 57.737
HC: -1.012 – 6.493
H: -0.909 – 10.565 |
800 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
4978
sparky, xeasy |
4795
sparky, xeasy |
96.32 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.906 – 142.797
HC: 4.823 – 11.784
H: -0.916 – 10.558 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
351
sparky, xeasy |
289
sparky, xeasy |
82.34 |
| 5 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×256×550 | C: 31.801 – 55.755
HC: -3.381 – 7.576
H: -1.021 – 6.474 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2541
sparky, xeasy |
2474
sparky, xeasy |
97.36 |
| 6 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.821 – 135.678
C: 40.887 – 72.825
HN: 4.856 – 11.817 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
213
sparky, xeasy |
90.64 |
| 7 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 98.766 – 133.622
C: 167.832 – 189.830
HN: 4.821 – 11.781 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
129
sparky, xeasy |
119
sparky, xeasy |
92.25 |
| 8 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×512 | N: 98.779 – 133.636
C: 167.814 – 189.813
HN: 4.822 – 11.782 |
800 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
214
sparky, xeasy |
91.06 |
| 9 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 100.821 – 135.678
C: 40.837 – 72.775
HN: 4.851 – 11.811 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
117
sparky, xeasy |
106
sparky, xeasy |
90.60 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 98.662 – 133.631
H: 4.823 – 11.790 |
800 |
4.00 |
N–H: spectrum, spectrum with peaks |
181
sparky, xeasy |
128
sparky, xeasy |
70.72 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 102.278 – 137.144
HN: 4.862 – 11.822
H: -2.117 – 11.850 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1899
sparky, xeasy |
1548
sparky, xeasy |
81.52 |
2L7Q (124 residues, PDB,
BMRB, 2010)
Reference:
Ramelot, T.A., Yang, Y., Xiao, R., Acton, T.B., Everett, J.K., Montelione, G.T., Kennedy, M.A. (2012). Solution NMR structure of BT_0084, a conjugative transposon lipoprotein from Bacteroides thetaiotamicron. Proteins 80: 667-670
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×385 | C: 2.180 – 82.102
H: -1.013 – 6.488 |
600 |
1.69 |
C–H: spectrum, spectrum with peaks |
1090
sparky, xeasy |
525
sparky, xeasy |
48.17 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×481×256 | C: 9.265 – 77.001
HC: -1.005 – 6.505
H: -1.357 – 11.005 |
749 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8156
sparky, xeasy |
7732
sparky, xeasy |
94.80 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×224×256 | C: 110.234 – 140.000
HC: 5.004 – 8.498
H: -1.357 – 11.005 |
749 |
28.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
891
sparky, xeasy |
638
sparky, xeasy |
71.60 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×563 | N: 101.711 – 134.572
C: 11.547 – 81.000
HN: 5.487 – 10.992 |
600 |
74.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
918
sparky, xeasy |
436
sparky, xeasy |
47.49 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×563 | N: 101.711 – 134.572
C: 11.547 – 81.000
HN: 5.487 – 10.992 |
600 |
74.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
570
sparky, xeasy |
270
sparky, xeasy |
47.37 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×385 | C1: 38.238 – 62.049
C2: 8.438 – 78.164
H1: -1.013 – 6.488 |
600 |
51.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
3768
sparky, xeasy |
1827
sparky, xeasy |
48.49 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×128 | N: 101.711 – 134.572
HN: 5.989 – 10.985
H: -1.156 – 6.781 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
651
sparky, xeasy |
309
sparky, xeasy |
47.47 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×487 | C: 8.357 – 78.080
HC: -1.013 – 6.488
H: -1.997 – 7.495 |
600 |
127.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3966
sparky, xeasy |
1917
sparky, xeasy |
48.34 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×241×486 | C: 8.113 – 77.833
HC: -1.031 – 6.469
H: -2.016 – 7.486 |
600 |
127.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
5602
sparky, xeasy |
2721
sparky, xeasy |
48.57 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.794 – 134.568
C: 41.164 – 70.930
HN: 5.994 – 10.999 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
475
sparky, xeasy |
226
sparky, xeasy |
47.58 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×256 | N: 101.711 – 134.572
C: 165.821 – 182.308
HN: 5.983 – 10.979 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
293
sparky, xeasy |
137
sparky, xeasy |
46.76 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 105.794 – 134.568
C: 41.164 – 70.930
HN: 6.000 – 11.005 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
237
sparky, xeasy |
113
sparky, xeasy |
47.68 |
| 13 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×347×256 | N: 101.673 – 134.455
HN: 5.509 – 11.012
H: -1.337 – 11.015 |
800 |
89.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2687
sparky, xeasy |
2307
sparky, xeasy |
85.86 |
2KFP (125 residues, PDB,
BMRB, 2009)
Reference:
Feldmann, E.A., Seetharaman, J., Ramelot, T.A., Lew, S., Zhao, L., Hamilton, K., Ciccosanti, C., Xiao, R., Acton, T.B., Everett, J.K., Tong, L., Montelione, G.T., Kennedy, M.A. (2012). Solution NMR and X-ray crystal structures of Pseudomonas syringae Pspto_3016 from protein domain family PF04237 (DUF419) adopt a "double wing" DNA binding motif. J Struct Funct Genomics 13: 155-162
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×547 | C: 4.112 – 83.800
H: -1.007 – 6.993 |
850 |
0.60 |
C–H: spectrum, spectrum with peaks |
586
sparky, xeasy |
567
sparky, xeasy |
96.76 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×231 | C: 110.059 – 140.000
H: 5.503 – 9.997 |
600 |
0.56 |
C–H: spectrum, spectrum with peaks |
81
sparky, xeasy |
50
sparky, xeasy |
61.73 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×547×256 | C: 9.672 – 78.197
HC: -1.002 – 6.998
H: -1.036 – 10.682 |
850 |
140.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
11314
sparky, xeasy |
10557
sparky, xeasy |
93.31 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×240×256 | C: 112.514 – 140.305
HC: 5.503 – 9.005
H: -1.036 – 10.682 |
850 |
30.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
799
sparky, xeasy |
542
sparky, xeasy |
67.83 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×258 | N: 102.734 – 132.500
C: 14.008 – 78.500
HN: 5.997 – 11.013 |
600 |
18.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
455
sparky, xeasy |
413
sparky, xeasy |
90.77 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×119×258 | N: 102.617 – 132.500
C: 15.023 – 74.945
HN: 5.997 – 11.013 |
600 |
31.61 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
267
sparky, xeasy |
247
sparky, xeasy |
92.51 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×385 | C1: 3.596 – 83.278
C2: 3.500 – 83.187
H1: -1.003 – 6.492 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2155
sparky, xeasy |
2107
sparky, xeasy |
97.77 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.986
C2: 13.617 – 33.986
H1: -3.670 – 9.653
H2: -0.459 – 6.484 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
5244
sparky, xeasy |
5091
sparky, xeasy |
97.08 |
| 9 |
CcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 102.617 – 132.500
C: 14.008 – 78.500
HN: 5.991 – 11.007 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
419
sparky, xeasy |
389
sparky, xeasy |
92.84 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×308×128 | N: 102.764 – 132.756
HN: 5.508 – 10.006
H: 0.435 – 6.271 |
850 |
20.19 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
320
sparky, xeasy |
293
sparky, xeasy |
91.56 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×102×385 | C: 8.262 – 78.121
HC: -0.975 – 5.969
H: -0.998 – 6.498 |
600 |
81.28 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2212
sparky, xeasy |
2139
sparky, xeasy |
96.70 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×212×385 | C: 8.216 – 78.085
HC: -1.011 – 5.995
H: -0.998 – 6.498 |
600 |
167.06 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3274
sparky, xeasy |
3185
sparky, xeasy |
97.28 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 102.617 – 132.500
C: 41.094 – 70.859
HN: 5.985 – 11.002 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
233
sparky, xeasy |
212
sparky, xeasy |
90.99 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 102.617 – 132.500
C: 165.633 – 182.500
HN: 5.991 – 11.007 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
136
sparky, xeasy |
123
sparky, xeasy |
90.44 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 102.617 – 132.500
C: 41.234 – 71.000
HN: 5.997 – 11.013 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
116
sparky, xeasy |
106
sparky, xeasy |
91.38 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×342 | N: 102.682 – 132.636
H: 6.002 – 10.998 |
850 |
0.42 |
N–H: spectrum, spectrum with peaks |
188
sparky, xeasy |
134
sparky, xeasy |
71.28 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×308×256 | N: 102.682 – 132.636
HN: 6.006 – 10.504
H: -1.036 – 10.682 |
850 |
80.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3425
sparky, xeasy |
2730
sparky, xeasy |
79.71 |
1SE9 (126 residues, PDB,
BMRB, 2004)
Reference:
Vinarov, D.A., Lytle, B.L., Peterson, F.C., Tyler, E.M., Volkman, B.F., Markley, J.L. (2004). Cell-free protein production and labeling protocol for NMR-based structural proteomics., Nat Methods 1: 149-153
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×1024 | C: 110.694 – 143.694
H: 4.781 – 13.104 |
600 |
1.00 |
C–H: spectrum, spectrum with peaks |
35
sparky, xeasy |
13
sparky, xeasy |
37.14 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | C: 22.800 – 63.892
HC: -3.511 – 13.136
H: -0.938 – 10.588 |
600 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
5373
sparky, xeasy |
4075
sparky, xeasy |
75.84 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | C: 110.812 – 143.685
HC: 4.808 – 13.123
H: -0.942 – 10.584 |
600 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
251
sparky, xeasy |
158
sparky, xeasy |
62.95 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.933 – 135.561
C: 1.778 – 83.963
HN: 4.809 – 13.124 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
458
sparky, xeasy |
418
sparky, xeasy |
91.27 |
| 5 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.951 – 135.579
C: 2.426 – 84.610
HN: 4.810 – 13.126 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
418
sparky, xeasy |
381
sparky, xeasy |
91.15 |
| 6 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | C: 22.810 – 63.902
HC: -2.070 – 8.303
H: -2.093 – 8.301 |
600 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3369
sparky, xeasy |
1851
sparky, xeasy |
54.94 |
| 7 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.927 – 135.556
C: 33.817 – 74.908
HN: 4.808 – 13.123 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
213
sparky, xeasy |
90.64 |
| 8 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.940 – 135.568
C: 168.503 – 181.650
HN: 4.809 – 13.124 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
131
sparky, xeasy |
114
sparky, xeasy |
87.02 |
| 9 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.951 – 135.579
C: 168.537 – 181.685
HN: 4.809 – 13.124 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
235
sparky, xeasy |
213
sparky, xeasy |
90.64 |
| 10 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.907 – 135.535
C: 33.826 – 74.918
HN: 4.809 – 13.124 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
117
sparky, xeasy |
106
sparky, xeasy |
90.60 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 102.714 – 135.566
H: 4.799 – 13.123 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
172
sparky, xeasy |
123
sparky, xeasy |
71.51 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 102.884 – 135.512
HN: 4.808 – 13.123
H: -0.944 – 10.582 |
600 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
1642
sparky, xeasy |
1318
sparky, xeasy |
80.27 |
2L3G (126 residues, PDB,
BMRB, 2010)
Reference:
Liu, G., Xiao, R., Janjua, H., Ciccosanti, C., Shastry, R., Acton, T.B., Everett, J., Montelione, G.T. Northeast Structural Genomics Consortium Target HR4495E, To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×2048 | C: 112.657 – 142.540
H: -1.912 – 11.423 |
600 |
2.00 |
C–H: spectrum, spectrum with peaks |
47
sparky, xeasy |
29
sparky, xeasy |
61.70 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
112×415×414 | C: 20.014 – 80.717
HC: -0.259 – 5.380
H: -0.531 – 10.762 |
800 |
73.94 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8707
sparky, xeasy |
8265
sparky, xeasy |
94.92 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×99×443 | C: 113.210 – 142.741
HC: 6.490 – 7.825
H: -0.482 – 10.741 |
800 |
14.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
585
sparky, xeasy |
413
sparky, xeasy |
70.60 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.340 – 133.361
C: 13.816 – 83.275
HN: 4.765 – 11.423 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
464
sparky, xeasy |
425
sparky, xeasy |
91.59 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.462 – 133.483
C: 13.816 – 83.275
HN: 4.765 – 11.423 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
271
sparky, xeasy |
252
sparky, xeasy |
92.99 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | C1: 25.451 – 49.267
C2: 1.071 – 73.737
H1: -1.912 – 11.416 |
600 |
128.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2012
sparky, xeasy |
1953
sparky, xeasy |
97.07 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.462 – 133.484
C: 9.065 – 88.026
HN: 4.765 – 11.423 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
424
sparky, xeasy |
401
sparky, xeasy |
94.58 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 102.340 – 133.361
HN: 4.766 – 11.839
H: -0.173 – 9.755 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
325
sparky, xeasy |
297
sparky, xeasy |
91.38 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 102.706 – 133.483
C: 168.050 – 185.022
HN: 4.765 – 11.423 |
600 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
140
sparky, xeasy |
111
sparky, xeasy |
79.29 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 102.248 – 133.453
H: 4.759 – 11.756 |
600 |
2.00 |
N–H: spectrum, spectrum with peaks |
185
sparky, xeasy |
138
sparky, xeasy |
74.59 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×385×414 | N: 102.822 – 133.381
HN: 5.257 – 10.488
H: -0.545 – 10.748 |
800 |
84.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2632
sparky, xeasy |
2213
sparky, xeasy |
84.08 |
2L3B (130 residues, PDB,
BMRB, 2010)
Reference:
Ramelot, T.A., Yang, Y., Xiao, R., Acton, T.B., Everett, J.K., Montelione, G.T., Kennedy, M.A. (2012). Proteins 867-870
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×401 | C: 0.745 – 80.633
H: -0.503 – 6.501 |
850 |
1.76 |
C–H: spectrum, spectrum with peaks |
564
sparky, xeasy |
529
sparky, xeasy |
93.79 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×429×256 | C: 8.895 – 78.651
HC: -0.994 – 6.501
H: -1.175 – 10.782 |
850 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9215
sparky, xeasy |
8442
sparky, xeasy |
91.61 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×201×512 | C: 111.392 – 141.161
HC: 5.487 – 8.990
H: -1.204 – 10.773 |
850 |
51.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1067
sparky, xeasy |
623
sparky, xeasy |
58.39 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×286 | N: 103.012 – 132.894
C: 16.234 – 76.000
HN: 5.992 – 10.997 |
600 |
72.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
476
sparky, xeasy |
440
sparky, xeasy |
92.44 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×286 | N: 103.012 – 132.894
C: 16.469 – 76.000
HN: 5.992 – 10.997 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
293
sparky, xeasy |
259
sparky, xeasy |
88.40 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 8.270 – 78.004
C2: 8.273 – 78.000
H1: -1.003 – 6.496 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1904
sparky, xeasy |
1825
sparky, xeasy |
95.85 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4190
sparky, xeasy |
4043
sparky, xeasy |
96.49 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×286×128 | N: 103.012 – 132.894
HN: 5.992 – 10.997
H: -0.175 – 5.778 |
600 |
36.13 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
337
sparky, xeasy |
302
sparky, xeasy |
89.61 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×371 | C: 8.192 – 77.917
HC: -0.175 – 5.802
H: -0.496 – 6.002 |
600 |
97.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2054
sparky, xeasy |
1939
sparky, xeasy |
94.40 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C: 8.188 – 77.922
HC: -0.182 – 5.795
H: -0.987 – 6.002 |
600 |
102.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2850
sparky, xeasy |
2727
sparky, xeasy |
95.68 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×286 | N: 103.047 – 132.930
C: 41.164 – 70.930
HN: 5.992 – 10.997 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
245
sparky, xeasy |
227
sparky, xeasy |
92.65 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×64×286 | N: 103.047 – 132.930
C: 168.251 – 183.911
HN: 5.992 – 10.997 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
150
sparky, xeasy |
133
sparky, xeasy |
88.67 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×286 | N: 103.047 – 132.930
C: 41.164 – 70.930
HN: 5.992 – 10.997 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
122
sparky, xeasy |
113
sparky, xeasy |
92.62 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×286 | N: 103.038 – 133.009
H: 6.006 – 10.997 |
850 |
1.23 |
N–H: spectrum, spectrum with peaks |
189
sparky, xeasy |
138
sparky, xeasy |
73.02 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×286×512 | N: 103.117 – 133.000
HN: 6.006 – 10.997
H: -1.197 – 10.780 |
850 |
144.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2974
sparky, xeasy |
2404
sparky, xeasy |
80.83 |
2LRH (134 residues, PDB,
BMRB, 2012)
Reference:
Liu, G., Koga, N., Koga, R., Xiao, R., Lee, H., Janjua, H., Kohan, E., Acton, T.B., Everett, J.K., Baker, D., Montelione, G.T. Solution NMR structure of de novo designed protein, p-loop ntpase fold, Northeast Structural Genomics Consortium target or137. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×2048 | C: 6.707 – 76.571
H: -2.163 – 11.777 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
687
sparky, xeasy |
671
sparky, xeasy |
97.67 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×248 | C: 112.899 – 142.665
H: 6.010 – 7.692 |
800 |
0.13 |
C–H: spectrum, spectrum with peaks |
44
sparky, xeasy |
31
sparky, xeasy |
70.45 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×524×512 | C: 20.079 – 89.532
HC: -0.797 – 6.327
H: -2.170 – 11.803 |
800 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9780
sparky, xeasy |
9382
sparky, xeasy |
95.93 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×124×256 | C: 113.124 – 142.656
HC: 6.016 – 7.692
H: -1.641 – 11.309 |
800 |
8.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
479
sparky, xeasy |
405
sparky, xeasy |
84.55 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.022 – 132.569
C: 4.390 – 79.097
HN: 4.821 – 11.781 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
526
sparky, xeasy |
494
sparky, xeasy |
93.92 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×256×512 | N: 104.045 – 132.592
C: 4.431 – 79.138
HN: 4.816 – 11.776 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
322
sparky, xeasy |
306
sparky, xeasy |
95.03 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×1024 | C1: 29.751 – 53.564
C2: 4.721 – 79.135
H1: -2.163 – 11.771 |
800 |
64.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2666
sparky, xeasy |
2633
sparky, xeasy |
98.76 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 104.008 – 132.555
HN: 4.816 – 11.776
H: -0.424 – 6.549 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
373
sparky, xeasy |
352
sparky, xeasy |
94.37 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
64×64×512 | N: 104.008 – 132.555
C: 167.924 – 189.581
HN: 4.816 – 11.776 |
800 |
8.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
163
sparky, xeasy |
126
sparky, xeasy |
77.30 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.609 – 132.552
H: 4.811 – 11.778 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
210
sparky, xeasy |
156
sparky, xeasy |
74.29 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×286×382 | N: 102.544 – 133.483
HN: 6.051 – 9.933
H: -0.204 – 10.214 |
800 |
54.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2844
sparky, xeasy |
2368
sparky, xeasy |
83.26 |
1VEE (134 residues, PDB,
BMRB, 2004)
Reference:
Pantoja-Uceda, D., Lopez-Mendez, B., Koshiba, S., Inoue, M., Kigawa, T., Terada, T., Shirouzu, M., Tanaka, A., Seki, M., Shinozaki, K., Yokoyama, S., Guntert, P. (2005). Solution structure of the rhodanese homology domain At4g01050(175-295) from Arabidopsis thaliana. Protein Sci 14: 224-230
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×1029 | C: -0.195 – 74.493
H: -1.038 – 5.961 |
800 |
2.01 |
C–H: spectrum, spectrum with peaks |
583
sparky, xeasy |
573
sparky, xeasy |
98.28 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×1029×800 | C: 8.908 – 46.716
HC: -1.036 – 5.963
H: -2.289 – 11.638 |
800 |
401.95 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12604
sparky, xeasy |
12093
sparky, xeasy |
95.95 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×368×800 | C: 109.663 – 134.998
HC: 5.467 – 7.966
H: -2.289 – 11.638 |
800 |
143.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1131
sparky, xeasy |
735
sparky, xeasy |
64.99 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.575 – 135.199
C: 0.047 – 74.699
HN: 6.295 – 10.198 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
477
sparky, xeasy |
476
sparky, xeasy |
99.79 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.575 – 135.199
C: 0.369 – 75.021
HN: 6.296 – 10.199 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
279
sparky, xeasy |
279
sparky, xeasy |
100.00 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×661 | N: 102.575 – 135.199
C: 0.200 – 74.852
HN: 6.293 – 10.797 |
600 |
82.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
423
sparky, xeasy |
422
sparky, xeasy |
99.76 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×661×256 | N: 102.600 – 135.224
HN: 6.297 – 10.801
H: -1.552 – 10.981 |
600 |
82.63 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
337
sparky, xeasy |
335
sparky, xeasy |
99.41 |
| 8 |
HCCHCOSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×286×571 | C: 109.750 – 135.071
HC: 5.495 – 7.993
H: 5.496 – 7.994 |
600 |
79.74 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
119
sparky, xeasy |
67
sparky, xeasy |
56.30 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×514×1027 | C: 0.720 – 75.080
HC: -1.012 – 5.990
H: -1.006 – 5.996 |
600 |
257.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3227
sparky, xeasy |
3121
sparky, xeasy |
96.72 |
| 10 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×661 | N: 102.575 – 135.199
H: -1.552 – 10.981
HN: 6.296 – 10.800 |
600 |
82.63 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
619
sparky, xeasy |
615
sparky, xeasy |
99.35 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.575 – 135.199
C: 38.091 – 70.033
HN: 6.297 – 10.200 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
253
sparky, xeasy |
252
sparky, xeasy |
99.60 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.575 – 135.199
C: 162.039 – 184.036
HN: 6.297 – 10.200 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
146
sparky, xeasy |
125
sparky, xeasy |
85.62 |
| 13 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.600 – 135.224
C: 162.056 – 184.054
HN: 6.296 – 10.199 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
253
sparky, xeasy |
251
sparky, xeasy |
99.21 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 102.575 – 135.199
C: 38.091 – 70.033
HN: 6.295 – 10.199 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
126
sparky, xeasy |
126
sparky, xeasy |
100.00 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×574 | N: 102.375 – 135.193
H: 6.283 – 10.184 |
800 |
1.12 |
N–H: spectrum, spectrum with peaks |
179
sparky, xeasy |
153
sparky, xeasy |
85.47 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×662×800 | N: 102.574 – 135.199
HN: 6.283 – 10.784
H: -2.275 – 11.652 |
800 |
258.59 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3981
sparky, xeasy |
3610
sparky, xeasy |
90.68 |
2K1G (136 residues, PDB,
BMRB, 2008)
Reference:
Aramini, J.M., Rossi, P., Huang, Y.J., Zhao, L., Jiang, M., Maglaqui, M., Xiao, R., Locke, J., Nair, R., Rost, B., Acton, T.B., Inouye, M., Montelione, G.T. (2008). Biochemistry 47: 9715-9717
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 5.421 – 80.307
H: -2.185 – 11.749 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
587
sparky, xeasy |
566
sparky, xeasy |
96.42 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×512 | C: 112.785 – 142.764
H: 4.795 – 11.756 |
800 |
2.00 |
C–H: spectrum, spectrum with peaks |
77
sparky, xeasy |
57
sparky, xeasy |
74.03 |
| 3 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
512×1024×440 | C: 16.001 – 85.860
HC: -2.177 – 11.756
H: -1.012 – 10.987 |
800 |
884.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
14042
sparky, xeasy |
13184
sparky, xeasy |
93.89 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | C: 112.923 – 142.814
HC: 4.768 – 11.728
H: -0.973 – 10.501 |
800 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1381
sparky, xeasy |
1212
sparky, xeasy |
87.76 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.225 – 133.111
C: 4.403 – 79.329
HN: 4.803 – 11.764 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
508
sparky, xeasy |
456
sparky, xeasy |
89.76 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 101.678 – 134.458
C: 15.586 – 81.769
HN: 4.807 – 11.793 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
301
sparky, xeasy |
277
sparky, xeasy |
92.03 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×576 | C1: 25.662 – 49.573
C2: 4.505 – 70.689
H1: -0.997 – 6.493 |
600 |
288.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1992
sparky, xeasy |
1950
sparky, xeasy |
97.89 |
| 8 |
CCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | C1: 112.829 – 142.720
C2: 112.970 – 142.861
H1: -2.184 – 11.750 |
800 |
256.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
225
sparky, xeasy |
187
sparky, xeasy |
83.11 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 101.639 – 134.420
C: 15.547 – 81.730
HN: 4.803 – 11.784 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
447
sparky, xeasy |
421
sparky, xeasy |
94.18 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.225 – 133.111
HN: 4.799 – 11.759
H: 1.044 – 6.035 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
360
sparky, xeasy |
323
sparky, xeasy |
89.72 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×552 | C: 29.816 – 53.719
HC: 0.292 – 6.280
H: -1.005 – 6.500 |
800 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2135
sparky, xeasy |
2072
sparky, xeasy |
97.05 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×550 | C: 25.607 – 49.518
HC: -0.185 – 9.800
H: -0.994 – 6.506 |
600 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3007
sparky, xeasy |
2944
sparky, xeasy |
97.90 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 101.678 – 134.458
C: 43.650 – 73.595
HN: 4.811 – 11.797 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
267
sparky, xeasy |
240
sparky, xeasy |
89.89 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.260 – 133.147
C: 168.790 – 188.747
HN: 4.807 – 11.767 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
157
sparky, xeasy |
140
sparky, xeasy |
89.17 |
| 15 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.225 – 133.111
C: 168.790 – 188.747
HN: 4.798 – 11.758 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
267
sparky, xeasy |
239
sparky, xeasy |
89.51 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | N: 103.140 – 133.108
H: -2.178 – 11.762 |
800 |
8.00 |
N–H: spectrum, spectrum with peaks |
246
sparky, xeasy |
147
sparky, xeasy |
59.76 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 103.263 – 133.143
HN: 4.804 – 11.764
H: -0.936 – 10.539 |
800 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4412
sparky, xeasy |
3406
sparky, xeasy |
77.20 |
2KKZ (140 residues, PDB,
BMRB, 2009)
Reference:
Aramini, J.M., Ma, L., Lee, H., Zhao, L., Cunningham, K., Ciccosanti, C., Janjua, H., Fang, Y., Xiao, R., Krug, R.M., Montelione, G.T. Solution NMR structure of the monomeric W187R mutant of A/Udorn NS1 effector domain. Northeast Structural Genomics target OR8C[W187R]. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 4.327 – 79.254
H: -2.178 – 11.794 |
600 |
8.00 |
C–H: spectrum, spectrum with peaks |
642
sparky, xeasy |
612
sparky, xeasy |
95.33 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 112.807 – 142.778
H: 4.823 – 11.789 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
58
sparky, xeasy |
44
sparky, xeasy |
75.86 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×551×440 | C: 19.914 – 89.778
HC: -0.999 – 6.492
H: -1.004 – 11.000 |
800 |
484.30 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
13793
sparky, xeasy |
13145
sparky, xeasy |
95.30 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×512 | C: 112.837 – 142.778
HC: 4.820 – 11.780
H: -0.668 – 10.311 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
700
sparky, xeasy |
658
sparky, xeasy |
94.00 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.246 – 132.136
C: 4.246 – 79.100
HN: 4.824 – 11.784 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
509
sparky, xeasy |
471
sparky, xeasy |
92.53 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 101.269 – 135.136
C: 4.466 – 79.319
HN: 4.822 – 11.782 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
294
sparky, xeasy |
276
sparky, xeasy |
93.88 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | C1: 31.848 – 55.754
C2: 9.109 – 78.836
H1: -2.176 – 11.789 |
600 |
256.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2326
sparky, xeasy |
2240
sparky, xeasy |
96.30 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | C: 29.897 – 53.804
HC: -0.798 – 6.685
H: -2.149 – 11.784 |
800 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2338
sparky, xeasy |
2220
sparky, xeasy |
94.95 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | C: 31.848 – 55.754
HC: -0.061 – 6.427
H: -2.178 – 11.787 |
600 |
512.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3396
sparky, xeasy |
3260
sparky, xeasy |
96.00 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.278 – 132.169
C: 40.807 – 72.807
HN: 4.824 – 11.784 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
263
sparky, xeasy |
246
sparky, xeasy |
93.54 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.246 – 132.136
C: 167.832 – 189.789
HN: 4.824 – 11.784 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
151
sparky, xeasy |
141
sparky, xeasy |
93.38 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.246 – 132.136
C: 167.806 – 189.763
HN: 4.824 – 11.784 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
263
sparky, xeasy |
242
sparky, xeasy |
92.02 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×512×512 | N: 104.246 – 132.136
C: 40.833 – 72.781
HN: 4.878 – 11.838 |
800 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
131
sparky, xeasy |
123
sparky, xeasy |
93.89 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | N: 103.174 – 133.145
H: -2.171 – 11.801 |
600 |
8.00 |
N–H: spectrum, spectrum with peaks |
212
sparky, xeasy |
147
sparky, xeasy |
69.34 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×512×440 | N: 104.342 – 135.051
HN: 4.834 – 11.794
H: -1.004 – 11.000 |
800 |
221.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4174
sparky, xeasy |
3494
sparky, xeasy |
83.71 |
1VDY (140 residues, PDB,
BMRB, 2004)
Reference:
Lopez-Mendez, B., Pantoja-Uceda, D., Tomizawa, T., Koshiba, S., Kigawa, T., Shirouzu, M., Terada, T., Inoue, M., Yabuki, T., Aoki, M., Seki, E., Matsuda, T., Hirota, H., Yoshida, M., Tanaka, A., Osanai, T., Seki, M., Shinozaki, K., Yokoyama, S., Guntert, P. Solution structure of the hypothetical ENTH-VHS domain AT3G16270 from arabidopsis thaliana. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1322 | C: 3.315 – 46.456
H: -0.998 – 8.000 |
800 |
2.58 |
C–H: spectrum, spectrum with peaks |
685
sparky, xeasy |
646
sparky, xeasy |
94.31 |
| 2 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1248×800 | C: 3.568 – 46.456
HC: -0.498 – 7.996
H: -0.786 – 10.200 |
800 |
487.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
14979
sparky, xeasy |
13765
sparky, xeasy |
91.90 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×572 | N: 106.440 – 128.439
C: -0.093 – 74.590
HN: 6.295 – 10.193 |
600 |
71.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
520
sparky, xeasy |
471
sparky, xeasy |
90.58 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 106.440 – 128.439
C: 0.229 – 74.913
HN: 6.293 – 10.198 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
288
sparky, xeasy |
260
sparky, xeasy |
90.28 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1026 | C1: 3.606 – 46.492
C2: -20.798 – 70.845
H1: -0.996 – 6.002 |
600 |
128.25 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2267
sparky, xeasy |
2176
sparky, xeasy |
95.99 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 106.440 – 128.440
C: 0.142 – 74.825
HN: 6.288 – 10.193 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
451
sparky, xeasy |
418
sparky, xeasy |
92.68 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×572×256 | N: 106.440 – 128.439
HN: 6.295 – 10.193
H: -0.958 – 10.397 |
600 |
71.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
365
sparky, xeasy |
327
sparky, xeasy |
89.59 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×629×1105 | C: 3.572 – 46.458
HC: -0.991 – 6.000
H: -0.998 – 5.999 |
600 |
339.38 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2353
sparky, xeasy |
2221
sparky, xeasy |
94.39 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×629×1105 | C: 3.572 – 46.458
HC: -0.981 – 6.010
H: -0.990 – 6.007 |
600 |
339.38 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3443
sparky, xeasy |
3279
sparky, xeasy |
95.24 |
| 10 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×210×405 | C: 111.479 – 137.829
HC: 6.311 – 8.012
H: 6.312 – 8.010 |
600 |
41.53 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
182
sparky, xeasy |
161
sparky, xeasy |
88.46 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 106.440 – 128.439
H: -0.960 – 10.395
HN: 6.285 – 10.190 |
600 |
71.63 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
664
sparky, xeasy |
608
sparky, xeasy |
91.57 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×572 | N: 106.440 – 128.439
C: 35.765 – 67.720
HN: 6.297 – 10.195 |
600 |
71.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
269
sparky, xeasy |
241
sparky, xeasy |
89.59 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×256×573 | N: 106.457 – 128.457
C: 161.595 – 183.602
HN: 6.291 – 10.196 |
600 |
71.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
148
sparky, xeasy |
118
sparky, xeasy |
79.73 |
| 14 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×256×572 | N: 106.423 – 128.422
C: 161.595 – 183.602
HN: 6.292 – 10.190 |
600 |
71.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
269
sparky, xeasy |
236
sparky, xeasy |
87.73 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×256×572 | N: 106.423 – 128.422
C: 35.777 – 67.733
HN: 6.292 – 10.190 |
600 |
71.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
134
sparky, xeasy |
120
sparky, xeasy |
89.55 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×574 | N: 106.310 – 128.439
H: 6.298 – 10.201 |
800 |
1.12 |
N–H: spectrum, spectrum with peaks |
216
sparky, xeasy |
135
sparky, xeasy |
62.50 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×574×800 | N: 106.440 – 128.439
HN: 6.298 – 10.201
H: -1.583 – 11.002 |
800 |
224.22 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4492
sparky, xeasy |
3476
sparky, xeasy |
77.38 |
2KKL (140 residues, PDB,
BMRB, 2009)
Reference:
Yang, Y., Ramelot, T.A., Wang, D., Foote, E.L., Jiang, M., Nair, R., Rost, B., Swapna, G., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of FHA domain of Mb1858 from Mycobacterium bovis. Northeast Structural Genomics Consortium Target MbR243C (24-155). To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
481×513 | C: 0.000 – 75.000
H: -1.991 – 7.001 |
600 |
1.19 |
C–H: spectrum, spectrum with peaks |
570
sparky, xeasy |
561
sparky, xeasy |
98.42 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×478 | C: 111.394 – 141.335
H: 5.005 – 11.994 |
850 |
1.04 |
C–H: spectrum, spectrum with peaks |
62
sparky, xeasy |
44
sparky, xeasy |
70.97 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×486×512 | C: 9.073 – 78.800
HC: -0.996 – 7.497
H: -2.173 – 11.800 |
850 |
247.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8762
sparky, xeasy |
8407
sparky, xeasy |
95.95 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×124×227 | C: 115.503 – 141.300
HC: 6.429 – 8.582
H: -0.942 – 11.417 |
850 |
15.47 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
430
sparky, xeasy |
325
sparky, xeasy |
75.58 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×343 | N: 104.164 – 133.930
C: 11.547 – 81.000
HN: 6.000 – 12.006 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
509
sparky, xeasy |
487
sparky, xeasy |
95.68 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×400 | N: 104.164 – 133.930
C: 11.547 – 81.000
HN: 4.998 – 12.006 |
600 |
25.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
298
sparky, xeasy |
284
sparky, xeasy |
95.30 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 8.282 – 78.016
C2: 8.203 – 77.930
H1: -1.001 – 6.498 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1934
sparky, xeasy |
1916
sparky, xeasy |
99.07 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.940 – 33.987
C2: 13.940 – 33.987
H1: -3.666 – 9.658
H2: -0.447 – 6.496 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4102
sparky, xeasy |
4075
sparky, xeasy |
99.34 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×314 | N: 104.047 – 133.930
C: 11.547 – 81.000
HN: 5.502 – 10.999 |
600 |
40.38 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
442
sparky, xeasy |
424
sparky, xeasy |
95.93 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×371×256 | N: 104.164 – 133.930
HN: 5.508 – 12.006
H: -0.169 – 5.808 |
600 |
48.88 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
353
sparky, xeasy |
339
sparky, xeasy |
96.03 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×428 | C: 8.357 – 78.081
HC: -0.669 – 6.277
H: -0.990 – 6.509 |
600 |
55.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1974
sparky, xeasy |
1947
sparky, xeasy |
98.63 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×542 | C: 8.352 – 78.086
HC: -0.669 – 6.304
H: -1.991 – 7.510 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2766
sparky, xeasy |
2739
sparky, xeasy |
99.02 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 104.047 – 133.930
H: -0.884 – 6.558
HN: 5.502 – 12.001 |
600 |
48.88 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
624
sparky, xeasy |
598
sparky, xeasy |
95.83 |
| 14 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×400 | N: 104.164 – 133.930
C: 41.467 – 71.002
HN: 4.998 – 12.006 |
600 |
12.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
267
sparky, xeasy |
256
sparky, xeasy |
95.88 |
| 15 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×400 | N: 104.164 – 133.930
C: 165.766 – 182.500
HN: 4.993 – 12.001 |
600 |
12.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
155
sparky, xeasy |
147
sparky, xeasy |
94.84 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×400 | N: 104.164 – 133.930
C: 41.467 – 71.002
HN: 4.998 – 12.006 |
600 |
12.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
133
sparky, xeasy |
128
sparky, xeasy |
96.24 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×401 | N: 104.152 – 134.035
H: 4.993 – 11.997 |
850 |
0.49 |
N–H: spectrum, spectrum with peaks |
213
sparky, xeasy |
156
sparky, xeasy |
73.24 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×444×256 | N: 104.305 – 134.070
HN: 5.503 – 11.994
H: -1.401 – 11.050 |
850 |
57.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3074
sparky, xeasy |
2490
sparky, xeasy |
81.00 |
2N4B (142 residues, PDB,
BMRB, 2015)
Reference:
Tang, Y., Huang, Y.J., Hopf, T.A., Sander, C., Marks, D.S., Montelione, G.T. (2015). Protein structure determination by combining sparse NMR data with evolutionary couplings. Nat Methods 12: 751-754
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×547 | C: 6.019 – 85.706
H: -1.696 – 6.304 |
850 |
0.60 |
C–H: spectrum, spectrum with peaks |
575
sparky, xeasy |
560
sparky, xeasy |
97.39 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×228 | C: 108.033 – 142.000
H: 5.008 – 8.995 |
600 |
0.98 |
C–H: spectrum, spectrum with peaks |
89
sparky, xeasy |
74
sparky, xeasy |
83.15 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×444×256 | C: 11.975 – 75.725
HC: -0.495 – 5.996
H: -0.975 – 10.580 |
850 |
114.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
10581
sparky, xeasy |
10211
sparky, xeasy |
96.50 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×206×256 | C: 111.534 – 141.300
HC: 5.498 – 8.502
H: -1.024 – 10.630 |
850 |
27.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
872
sparky, xeasy |
813
sparky, xeasy |
93.23 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×428 | N: 105.511 – 132.300
C: 14.250 – 78.000
HN: 3.001 – 10.500 |
600 |
55.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
532
sparky, xeasy |
512
sparky, xeasy |
96.24 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×428 | N: 105.511 – 132.300
C: 14.500 – 78.000
HN: 3.001 – 10.500 |
600 |
27.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
313
sparky, xeasy |
305
sparky, xeasy |
97.44 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×853 | C1: 10.327 – 76.070
C2: 10.327 – 76.070
H1: -1.009 – 6.491 |
600 |
214.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1882
sparky, xeasy |
1852
sparky, xeasy |
98.41 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4753
sparky, xeasy |
4740
sparky, xeasy |
99.73 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | N: 105.406 – 132.300
C: 13.258 – 79.000
HN: 3.001 – 10.500 |
600 |
110.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
457
sparky, xeasy |
449
sparky, xeasy |
98.25 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×428×256 | N: 105.406 – 132.300
HN: 3.001 – 10.500
H: 0.397 – 6.374 |
600 |
110.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
359
sparky, xeasy |
347
sparky, xeasy |
96.66 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×542 | C: 10.267 – 77.998
HC: -0.681 – 6.292
H: -1.994 – 7.507 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2787
sparky, xeasy |
2742
sparky, xeasy |
98.39 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×428 | N: 105.511 – 132.300
C: 166.294 – 181.955
HN: 3.001 – 10.500 |
600 |
14.91 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
161
sparky, xeasy |
157
sparky, xeasy |
97.52 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×428 | N: 105.511 – 132.300
C: 41.164 – 70.930
HN: 3.001 – 10.500 |
600 |
27.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
137
sparky, xeasy |
133
sparky, xeasy |
97.08 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×512 | N: 105.429 – 132.403
H: 2.998 – 10.486 |
850 |
2.00 |
N–H: spectrum, spectrum with peaks |
217
sparky, xeasy |
168
sparky, xeasy |
77.42 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×481×256 | N: 105.637 – 132.427
HN: 2.996 – 10.488
H: -1.173 – 10.780 |
850 |
63.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3917
sparky, xeasy |
3468
sparky, xeasy |
88.54 |
2L8V (143 residues, PDB,
BMRB, 2011)
Reference:
Ramelot, T.A., Yang, Y., Cort, J.R., Lee, D., Ciccosanti, C., Hamilton, K., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the phycobilisome linker polypeptide domain of CpcC (20-153) from Thermosynechococcus elongatus, Northeast Structural Genomics Consortium Target TeR219A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×401 | C: 10.164 – 76.035
H: -0.999 – 6.006 |
850 |
0.88 |
C–H: spectrum, spectrum with peaks |
615
sparky, xeasy |
494
sparky, xeasy |
80.33 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×429×256 | C: 10.690 – 76.413
HC: -0.994 – 6.501
H: -1.175 – 10.782 |
850 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
10300
sparky, xeasy |
8562
sparky, xeasy |
83.13 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×151×454 | C: 112.209 – 141.979
HC: 6.198 – 8.825
H: -0.073 – 10.547 |
850 |
36.56 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
666
sparky, xeasy |
377
sparky, xeasy |
56.61 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 104.704 – 131.493
C: 15.502 – 77.018
HN: 5.495 – 10.500 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
540
sparky, xeasy |
401
sparky, xeasy |
74.26 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 104.704 – 131.493
C: 15.502 – 77.018
HN: 5.495 – 10.500 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
305
sparky, xeasy |
222
sparky, xeasy |
72.79 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×839 | C1: 8.436 – 78.166
C2: 8.438 – 78.164
H1: -1.007 – 6.493 |
600 |
214.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2121
sparky, xeasy |
1716
sparky, xeasy |
80.91 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.612 – 33.991
C2: 13.936 – 33.991
H1: -0.487 – 6.462
H2: -3.716 – 9.649 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4654
sparky, xeasy |
3996
sparky, xeasy |
85.86 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×314×256 | N: 104.704 – 131.493
HN: 5.484 – 10.981
H: 0.561 – 6.538 |
600 |
40.38 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
378
sparky, xeasy |
276
sparky, xeasy |
73.02 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C: 8.357 – 78.081
HC: -0.182 – 5.795
H: -0.998 – 6.501 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2195
sparky, xeasy |
1722
sparky, xeasy |
78.45 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×542 | C: 8.374 – 78.108
HC: -0.182 – 5.795
H: -1.994 – 7.507 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3085
sparky, xeasy |
2438
sparky, xeasy |
79.03 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 104.704 – 131.493
C: 41.243 – 71.009
HN: 5.495 – 10.500 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
277
sparky, xeasy |
207
sparky, xeasy |
74.73 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×280 | N: 104.704 – 131.493
C: 168.251 – 183.911
HN: 5.595 – 10.495 |
600 |
8.75 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
156
sparky, xeasy |
110
sparky, xeasy |
70.51 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 104.704 – 131.493
C: 41.243 – 71.009
HN: 5.495 – 10.500 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
138
sparky, xeasy |
103
sparky, xeasy |
74.64 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×315 | N: 104.613 – 131.587
H: 5.487 – 10.986 |
850 |
1.37 |
N–H: spectrum, spectrum with peaks |
222
sparky, xeasy |
119
sparky, xeasy |
53.60 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×377×256 | N: 104.700 – 131.595
HN: 5.489 – 10.999
H: -0.658 – 11.296 |
850 |
97.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3789
sparky, xeasy |
2628
sparky, xeasy |
69.36 |
2LGH (144 residues, PDB,
BMRB, 2011)
Reference:
Ramelot, T.A., Yang, Y., Cort, J.R., Wang, D., Ciccosanti, C., Janjua, H., Rajesh, N., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the AHSA1-like protein AHA_2358 from Aeromonas hydrophila refined with NH RDCs. Northeast Structural Genomics Consortium Target AhR99. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×581 | C: 2.894 – 82.581
H: -0.993 – 7.505 |
850 |
0.63 |
C–H: spectrum, spectrum with peaks |
551
sparky, xeasy |
534
sparky, xeasy |
96.91 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×386 | C: 110.081 – 139.966
H: 4.999 – 11.008 |
850 |
0.47 |
C–H: spectrum, spectrum with peaks |
101
sparky, xeasy |
66
sparky, xeasy |
65.35 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×512×256 | C: 11.812 – 75.688
HC: -0.993 – 6.494
H: -1.421 – 11.030 |
850 |
256.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
10771
sparky, xeasy |
10071
sparky, xeasy |
93.50 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×342×256 | C: 111.380 – 141.267
HC: 5.000 – 9.996
H: -1.422 – 11.030 |
850 |
89.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1612
sparky, xeasy |
1138
sparky, xeasy |
70.60 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 104.851 – 132.235
C: 14.500 – 78.000
HN: 5.014 – 11.002 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
534
sparky, xeasy |
512
sparky, xeasy |
95.88 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 104.851 – 132.235
C: 14.500 – 78.000
HN: 5.014 – 11.002 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
306
sparky, xeasy |
294
sparky, xeasy |
96.08 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C1: 4.684 – 70.426
C2: 4.684 – 70.426
H1: -1.009 – 5.981 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1705
sparky, xeasy |
1647
sparky, xeasy |
96.60 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
4427
sparky, xeasy |
4312
sparky, xeasy |
97.40 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×342 | N: 104.851 – 132.235
C: 13.232 – 78.974
HN: 5.014 – 11.002 |
600 |
44.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
430
sparky, xeasy |
416
sparky, xeasy |
96.74 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×342×128 | N: 104.851 – 132.235
HN: 5.014 – 11.002
H: 0.561 – 6.514 |
600 |
22.31 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
365
sparky, xeasy |
351
sparky, xeasy |
96.16 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C: 10.258 – 76.000
HC: -0.681 – 6.292
H: -0.993 – 6.506 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1883
sparky, xeasy |
1815
sparky, xeasy |
96.39 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C: 10.267 – 77.998
HC: -0.672 – 6.300
H: -0.993 – 6.506 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2491
sparky, xeasy |
2415
sparky, xeasy |
96.95 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 104.851 – 132.235
C: 41.164 – 70.930
HN: 5.014 – 11.002 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
279
sparky, xeasy |
268
sparky, xeasy |
96.06 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 104.851 – 132.235
C: 168.126 – 183.911
HN: 5.014 – 11.002 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
159
sparky, xeasy |
148
sparky, xeasy |
93.08 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×342 | N: 104.851 – 132.235
C: 41.164 – 70.930
HN: 5.014 – 11.002 |
600 |
22.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
139
sparky, xeasy |
134
sparky, xeasy |
96.40 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×385 | N: 103.082 – 132.964
H: 5.004 – 11.012 |
600 |
0.47 |
N–H: spectrum, spectrum with peaks |
216
sparky, xeasy |
168
sparky, xeasy |
77.78 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×343×512 | N: 104.841 – 132.331
HN: 5.008 – 10.997
H: -1.446 – 11.030 |
850 |
175.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4016
sparky, xeasy |
3455
sparky, xeasy |
86.03 |
2K1S (149 residues, PDB,
BMRB, 2008)
Reference:
Ramelot, T.A., Zhao, L., Hamilton, K., Maglaqui, M., Xiao, R., Liu, J., Baran, M.C., Swapna, G., Acton, T.B., Rost, B., Montelione, G.T., Kennedy, M.A., Solution NMR structure of the folded C-terminal fragment of YiaD from Escherichia coli. Northeast Structural Genomics Consortium target ER553. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×400 | C: 0.203 – 80.047
H: -0.525 – 6.489 |
600 |
0.78 |
C–H: spectrum, spectrum with peaks |
622
sparky, xeasy |
613
sparky, xeasy |
98.55 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×286 | C: 110.059 – 140.000
H: 4.993 – 10.003 |
600 |
0.62 |
C–H: spectrum, spectrum with peaks |
35
sparky, xeasy |
19
sparky, xeasy |
54.29 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×439×256 | C: 31.066 – 54.972
HC: -1.493 – 6.206
H: -0.657 – 10.300 |
600 |
114.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12059
sparky, xeasy |
11542
sparky, xeasy |
95.71 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×225×256 | C: 115.078 – 135.000
HC: 4.997 – 9.009
H: -1.650 – 11.301 |
600 |
59.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
347
sparky, xeasy |
214
sparky, xeasy |
61.67 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×286 | N: 97.165 – 138.999
C: 11.547 – 81.000
HN: 4.999 – 10.009 |
600 |
36.13 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
337
sparky, xeasy |
321
sparky, xeasy |
95.25 |
| 6 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×32×128×1024 | C1: 13.617 – 33.986
C2: 13.940 – 33.986
H1: -0.449 – 6.494
H2: -3.660 – 9.663 |
600 |
1024.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
5354
sparky, xeasy |
5327
sparky, xeasy |
99.50 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×343 | N: 97.165 – 138.999
C: 15.531 – 75.063
HN: 5.004 – 11.016 |
600 |
44.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
501
sparky, xeasy |
483
sparky, xeasy |
96.41 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×343×256 | N: 97.165 – 138.999
HN: 4.993 – 11.005
H: 0.323 – 6.300 |
600 |
89.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
370
sparky, xeasy |
358
sparky, xeasy |
96.76 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×428 | C: 31.122 – 55.028
HC: -0.669 – 6.277
H: -1.001 – 6.505 |
600 |
55.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2178
sparky, xeasy |
2151
sparky, xeasy |
98.76 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×428 | C: 31.122 – 55.028
HC: -0.669 – 6.277
H: -1.001 – 6.505 |
600 |
55.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3094
sparky, xeasy |
3067
sparky, xeasy |
99.13 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×400 | N: 97.329 – 138.999
H: -0.669 – 6.277
HN: 4.993 – 12.007 |
600 |
25.00 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
709
sparky, xeasy |
681
sparky, xeasy |
96.05 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 97.329 – 138.999
C: 41.328 – 70.859
HN: 4.999 – 10.009 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
285
sparky, xeasy |
276
sparky, xeasy |
96.84 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×256×343 | N: 97.164 – 139.000
C: 165.586 – 182.520
HN: 4.993 – 11.005 |
600 |
89.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
174
sparky, xeasy |
136
sparky, xeasy |
78.16 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 97.329 – 138.999
C: 41.469 – 71.000
HN: 4.993 – 10.003 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
142
sparky, xeasy |
138
sparky, xeasy |
97.18 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×496 | N: 97.164 – 139.000
H: 4.999 – 10.800 |
600 |
0.48 |
N–H: spectrum, spectrum with peaks |
233
sparky, xeasy |
175
sparky, xeasy |
75.11 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×285×256 | N: 97.165 – 138.999
HN: 5.498 – 10.490
H: -0.657 – 10.300 |
600 |
72.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4206
sparky, xeasy |
3537
sparky, xeasy |
84.09 |
2M4F (151 residues, PDB,
BMRB, 2013)
Reference:
Bhattacharjee, A., Oeemig, J.S., Kolodziejczyk, R., Meri, T., Kajander, T., Lehtinen, M.J., Iwai, H., Jokiranta, T.S., Goldman, A. (2013). Structural Basis for Complement Evasion by Lyme Disease Pathogen Borrelia burgdorferi. J Biol Chem 288: 18685-18695
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1024×2048 | C: 6.096 – 78.119
H: -1.175 – 10.696 |
800 |
8.00 |
C–H: spectrum, spectrum with peaks |
687
sparky, xeasy |
633
sparky, xeasy |
92.14 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | C: 106.374 – 156.045
H: 4.779 – 10.712 |
800 |
4.00 |
C–H: spectrum, spectrum with peaks |
68
sparky, xeasy |
35
sparky, xeasy |
51.47 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×2048×1024 | C: 3.415 – 83.101
HC: -1.489 – 11.031
H: -1.472 – 11.018 |
800 |
2048.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9908
sparky, xeasy |
8944
sparky, xeasy |
90.27 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 96.652 – 136.004
C: 13.174 – 92.858
HN: 4.775 – 11.442 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
574
sparky, xeasy |
572
sparky, xeasy |
99.65 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 95.866 – 136.859
C: 8.371 – 78.097
HN: 4.767 – 11.433 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
338
sparky, xeasy |
330
sparky, xeasy |
97.63 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 96.635 – 135.988
C: 3.314 – 83.158
HN: 4.770 – 11.436 |
600 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
523
sparky, xeasy |
510
sparky, xeasy |
97.51 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×1024×256 | N: 96.620 – 135.972
HN: 4.768 – 11.434
H: -2.685 – 12.270 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
399
sparky, xeasy |
388
sparky, xeasy |
97.24 |
| 8 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×2048 | C: -4.554 – 75.133
HC: -1.461 – 11.017
H: -1.482 – 11.015 |
800 |
1024.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2559
sparky, xeasy |
2239
sparky, xeasy |
87.50 |
| 9 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×368×1472 | C: -4.586 – 75.102
HC: -1.471 – 7.491
H: -1.480 – 7.500 |
800 |
537.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3867
sparky, xeasy |
3315
sparky, xeasy |
85.73 |
| 10 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 95.625 – 136.618
C: 40.221 – 70.103
HN: 4.762 – 11.429 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
301
sparky, xeasy |
300
sparky, xeasy |
99.67 |
| 11 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | N: 96.806 – 136.003
C: 161.685 – 186.595
HN: 4.766 – 11.432 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
176
sparky, xeasy |
150
sparky, xeasy |
85.23 |
| 12 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
256×256×1024 | N: 96.636 – 135.988
C: 161.684 – 186.597
HN: 4.769 – 11.435 |
600 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
301
sparky, xeasy |
300
sparky, xeasy |
99.67 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×1024 | N: 96.620 – 135.972
C: 41.363 – 71.128
HN: 4.768 – 11.434 |
600 |
128.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
150
sparky, xeasy |
150
sparky, xeasy |
100.00 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 97.657 – 138.769
H: 4.758 – 12.257 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
207
sparky, xeasy |
174
sparky, xeasy |
84.06 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
256×1024×2048 | N: 96.452 – 135.776
HN: 4.770 – 11.015
H: -2.741 – 12.279 |
800 |
2048.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3052
sparky, xeasy |
2698
sparky, xeasy |
88.40 |
| 16 |
N15TOCSY
ucsf, pipe, .3D.16, .3D.param |
256×1024×256 | N: 96.682 – 136.034
HN: 4.770 – 11.436
H: -2.692 – 12.265 |
600 |
256.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
945
sparky, xeasy |
743
sparky, xeasy |
78.62 |
2JXP (155 residues, PDB,
BMRB, 2007)
Reference:
Rossi, P., Xiao, R., Acton, T.B., Montelione, G.T. Solution NMR structure of uncharacterized lipoprotein B from Nitrosomonas europaea. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×479 | C: 8.356 – 83.169
H: -0.499 – 6.012 |
800 |
1.04 |
C–H: spectrum, spectrum with peaks |
708
sparky, xeasy |
651
sparky, xeasy |
91.95 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×512 | C: 112.794 – 142.685
H: 4.750 – 11.710 |
800 |
0.50 |
C–H: spectrum, spectrum with peaks |
55
sparky, xeasy |
31
sparky, xeasy |
56.36 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×474×385 | C: 19.953 – 89.675
HC: -0.256 – 6.187
H: -0.506 – 9.990 |
800 |
185.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8711
sparky, xeasy |
7864
sparky, xeasy |
90.28 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 106.242 – 132.044
C: 4.716 – 79.201
HN: 4.727 – 11.687 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
594
sparky, xeasy |
553
sparky, xeasy |
93.10 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 106.255 – 132.052
C: 4.517 – 79.185
HN: 4.726 – 11.701 |
600 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
336
sparky, xeasy |
312
sparky, xeasy |
92.86 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×479 | C1: 29.859 – 53.668
C2: 4.449 – 79.115
H1: -0.510 – 6.000 |
800 |
61.63 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2604
sparky, xeasy |
2383
sparky, xeasy |
91.51 |
| 7 |
CCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×224 | C1: 112.909 – 142.683
C2: 112.949 – 142.723
H1: 5.757 – 7.937 |
800 |
16.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
167
sparky, xeasy |
91
sparky, xeasy |
54.49 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×512×128 | N: 106.136 – 132.040
HN: 4.740 – 11.700
H: 1.011 – 5.973 |
800 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
402
sparky, xeasy |
372
sparky, xeasy |
92.54 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×478 | C: 33.891 – 57.701
HC: -0.194 – 5.782
H: -0.492 – 6.005 |
800 |
61.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2592
sparky, xeasy |
2337
sparky, xeasy |
90.16 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×478 | C: 29.853 – 53.663
HC: -0.198 – 5.755
H: -0.499 – 5.998 |
800 |
30.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3786
sparky, xeasy |
3403
sparky, xeasy |
89.88 |
| 11 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×75×224 | C: 112.948 – 142.722
HC: 6.084 – 8.975
H: 5.748 – 7.929 |
800 |
9.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
167
sparky, xeasy |
91
sparky, xeasy |
54.49 |
| 12 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 106.244 – 132.046
C: 41.782 – 71.657
HN: 4.737 – 11.697 |
800 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
303
sparky, xeasy |
285
sparky, xeasy |
94.06 |
| 13 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 106.254 – 132.056
C: 168.847 – 188.687
HN: 4.732 – 11.692 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
171
sparky, xeasy |
142
sparky, xeasy |
83.04 |
| 14 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 106.250 – 132.052
C: 168.847 – 188.687
HN: 4.738 – 11.698 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
303
sparky, xeasy |
284
sparky, xeasy |
93.73 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×324 | N: 106.252 – 132.054
C: 41.878 – 71.636
HN: 5.936 – 10.335 |
800 |
24.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
151
sparky, xeasy |
142
sparky, xeasy |
94.04 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×512 | N: 106.151 – 132.049
H: 4.735 – 11.695 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
254
sparky, xeasy |
162
sparky, xeasy |
63.78 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×385 | N: 104.268 – 135.026
HN: 4.724 – 11.684
H: -0.509 – 9.987 |
800 |
102.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3007
sparky, xeasy |
2240
sparky, xeasy |
74.49 |
2L06 (155 residues, PDB,
BMRB, 2010)
Reference:
Ramelot, T.A., Yang, Y., Cort, J.R., Hamilton, K., Ciccosanti, C., Lee, D., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the PBS linker polypeptide domain of phycobilisome linker protein apcE from Synechocystis sp. Northeast Structural Genomics Consortium Target SgR209C. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×578 | C: 3.909 – 83.753
H: -2.005 – 7.001 |
850 |
1.27 |
C–H: spectrum, spectrum with peaks |
695
sparky, xeasy |
646
sparky, xeasy |
92.95 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×450×256 | C: 9.954 – 74.700
HC: -1.006 – 6.002
H: -0.558 – 10.200 |
850 |
119.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12328
sparky, xeasy |
11326
sparky, xeasy |
91.87 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×240×256 | C: 116.267 – 138.908
HC: 5.508 – 9.010
H: -0.644 – 10.313 |
850 |
15.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1069
sparky, xeasy |
716
sparky, xeasy |
66.98 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×285 | N: 102.426 – 131.805
C: 9.086 – 83.500
HN: 5.503 – 10.497 |
500 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
577
sparky, xeasy |
529
sparky, xeasy |
91.68 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×285 | N: 102.426 – 131.805
C: 9.086 – 83.500
HN: 5.498 – 10.492 |
500 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
337
sparky, xeasy |
305
sparky, xeasy |
90.50 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C1: 8.470 – 78.204
C2: 8.456 – 78.182
H1: -1.000 – 6.499 |
600 |
110.50 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2466
sparky, xeasy |
2331
sparky, xeasy |
94.53 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×399 | N: 102.426 – 131.805
C: 9.086 – 83.500
HN: 4.983 – 11.981 |
500 |
25.50 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
515
sparky, xeasy |
475
sparky, xeasy |
92.23 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×285×256 | N: 102.426 – 131.805
HN: 5.498 – 10.492
H: -1.197 – 6.772 |
500 |
36.13 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
405
sparky, xeasy |
368
sparky, xeasy |
90.86 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×243×371 | C: 8.507 – 78.231
HC: -0.179 – 5.493
H: -1.006 – 5.492 |
600 |
97.37 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2597
sparky, xeasy |
2410
sparky, xeasy |
92.80 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×542 | C: 8.452 – 78.186
HC: -0.179 – 5.798
H: -2.007 – 7.495 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3737
sparky, xeasy |
3506
sparky, xeasy |
93.82 |
| 11 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×285 | N: 102.310 – 131.805
H: -1.206 – 6.763
HN: 5.488 – 10.481 |
500 |
72.25 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
765
sparky, xeasy |
690
sparky, xeasy |
90.20 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×367 | N: 101.455 – 132.792
C: 166.294 – 181.955
HN: 5.493 – 10.497 |
500 |
12.66 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
172
sparky, xeasy |
148
sparky, xeasy |
86.05 |
| 13 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×285 | N: 102.426 – 131.805
C: 41.233 – 71.002
HN: 5.493 – 10.487 |
500 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
148
sparky, xeasy |
136
sparky, xeasy |
91.89 |
| 14 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×367 | N: 87.621 – 146.610
H: 5.489 – 10.495 |
500 |
0.44 |
N–H: spectrum, spectrum with peaks |
249
sparky, xeasy |
166
sparky, xeasy |
66.67 |
| 15 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×321×256 | N: 102.531 – 131.900
HN: 5.512 – 10.506
H: -0.644 – 10.313 |
850 |
42.50 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4335
sparky, xeasy |
3410
sparky, xeasy |
78.66 |
2LAH (160 residues, PDB,
BMRB, 2011)
Reference:
Liu, G., Shastry, R., Ciccosanti, C., Hamilton, K., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T. Northeast Structural Genomics Consortium Target HR5460A. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×491×470 | C: 20.261 – 88.522
HC: -0.763 – 5.912
H: -1.028 – 11.796 |
800 |
120.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
10687
sparky, xeasy |
10019
sparky, xeasy |
93.75 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×173×486 | C: 112.639 – 142.886
HC: 5.840 – 8.183
H: -1.009 – 11.305 |
800 |
24.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1375
sparky, xeasy |
1221
sparky, xeasy |
88.80 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 104.834 – 130.958
C: 13.761 – 83.221
HN: 4.790 – 10.782 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
598
sparky, xeasy |
523
sparky, xeasy |
87.46 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 104.834 – 130.958
C: 13.821 – 83.281
HN: 4.792 – 10.783 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
382
sparky, xeasy |
342
sparky, xeasy |
89.53 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | C1: 29.701 – 53.513
C2: 4.297 – 79.004
H1: -2.168 – 11.766 |
800 |
128.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2417
sparky, xeasy |
2319
sparky, xeasy |
95.95 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 104.834 – 130.958
C: 9.270 – 88.232
HN: 4.792 – 11.866 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
572
sparky, xeasy |
522
sparky, xeasy |
91.26 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 104.834 – 130.958
HN: 4.792 – 11.866
H: -0.164 – 9.764 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
430
sparky, xeasy |
375
sparky, xeasy |
87.21 |
| 8 |
HCCHTOCSY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
64×128×1024 | C: 112.098 – 143.598
HC: 3.095 – 10.040
H: -2.161 – 11.773 |
800 |
32.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
376
sparky, xeasy |
349
sparky, xeasy |
92.82 |
| 9 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1024 | N: 103.063 – 132.007
H: 4.803 – 11.770 |
800 |
2.00 |
N–H: spectrum, spectrum with peaks |
250
sparky, xeasy |
176
sparky, xeasy |
70.40 |
| 10 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×496×451 | N: 102.933 – 133.240
HN: 4.251 – 10.993
H: -1.029 – 11.276 |
800 |
116.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3657
sparky, xeasy |
2960
sparky, xeasy |
80.94 |
2LAK (160 residues, PDB,
BMRB, 2011)
Reference:
Yang, Y., Ramelot, T.A., Cort, J.R., Wang, D., Ciccosanti, C., Janjua, H., Nair, R., Rost, B., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the AHSA1-like protein RHE_CH02687 (1-152) from Rhizobium etli, Northeast Structural Genomics Consortium Target ReR242. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×492 | C: 6.130 – 85.783
H: -0.993 – 6.201 |
850 |
0.48 |
C–H: spectrum, spectrum with peaks |
675
sparky, xeasy |
632
sparky, xeasy |
93.63 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×478×256 | C: 12.053 – 75.797
HC: -0.993 – 5.996
H: -1.422 – 11.030 |
850 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
10771
sparky, xeasy |
9998
sparky, xeasy |
92.82 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×342×256 | C: 111.416 – 141.301
HC: 5.000 – 9.996
H: -1.421 – 11.030 |
850 |
89.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
769
sparky, xeasy |
542
sparky, xeasy |
70.48 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.045 – 132.932
C: 11.711 – 81.164
HN: 6.002 – 11.020 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
551
sparky, xeasy |
502
sparky, xeasy |
91.11 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.045 – 132.932
C: 11.711 – 81.164
HN: 5.996 – 11.014 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
287
sparky, xeasy |
259
sparky, xeasy |
90.24 |
| 6 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C1: 4.838 – 70.581
C2: 4.838 – 70.581
H1: -1.003 – 5.987 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2275
sparky, xeasy |
2134
sparky, xeasy |
93.80 |
| 7 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×64×1024×128 | C1: 13.617 – 33.987
C2: 13.617 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
2048.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
5167
sparky, xeasy |
4924
sparky, xeasy |
95.30 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×513 | N: 103.162 – 132.932
C: 6.814 – 86.186
HN: 6.006 – 11.004 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
442
sparky, xeasy |
398
sparky, xeasy |
90.05 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×343×128 | N: 103.162 – 132.932
HN: 5.996 – 11.004
H: 0.561 – 6.514 |
600 |
22.31 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
386
sparky, xeasy |
351
sparky, xeasy |
90.93 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×513 | C: 8.340 – 78.070
HC: -0.680 – 6.292
H: -1.000 – 6.498 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2421
sparky, xeasy |
2256
sparky, xeasy |
93.18 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×513 | C: 8.272 – 78.002
HC: -0.672 – 6.300
H: -0.996 – 6.502 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3363
sparky, xeasy |
3144
sparky, xeasy |
93.49 |
| 12 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×343 | N: 103.162 – 132.932
H: -1.179 – 6.789
HN: 6.000 – 11.009 |
600 |
44.63 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
638
sparky, xeasy |
572
sparky, xeasy |
89.66 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.045 – 132.932
C: 41.165 – 70.929
HN: 5.996 – 11.014 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
293
sparky, xeasy |
268
sparky, xeasy |
91.47 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.045 – 132.932
C: 166.236 – 185.956
HN: 6.002 – 11.020 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
152
sparky, xeasy |
134
sparky, xeasy |
88.16 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×258 | N: 103.045 – 132.932
C: 41.235 – 70.999
HN: 5.996 – 11.014 |
600 |
34.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
146
sparky, xeasy |
134
sparky, xeasy |
91.78 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×386 | N: 103.023 – 133.036
H: 4.999 – 11.008 |
850 |
0.84 |
N–H: spectrum, spectrum with peaks |
229
sparky, xeasy |
146
sparky, xeasy |
63.76 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×386×256 | N: 103.234 – 133.001
HN: 5.003 – 11.012
H: -1.422 – 11.030 |
850 |
51.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3610
sparky, xeasy |
2733
sparky, xeasy |
75.71 |
2L82 (162 residues, PDB,
BMRB, 2010)
Reference:
Liu, G., Koga, N., Koga, R., Xiao, R., Hamilton, K., Janjua, H., Tong, S., Acton, T.B., Everett, J., Baker, D., Montelione, G.T. Northeast Structural Genomics Consortium Target OR32. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×584×472 | C: 19.953 – 89.406
HC: -2.251 – 5.689
H: -1.724 – 11.155 |
800 |
142.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
11465
sparky, xeasy |
10921
sparky, xeasy |
95.26 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
44×224×512 | C: 113.149 – 133.305
HC: 5.111 – 8.148
H: -1.759 – 11.216 |
800 |
22.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
945
sparky, xeasy |
892
sparky, xeasy |
94.39 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.568 – 132.958
C: 13.701 – 83.161
HN: 4.700 – 11.358 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
628
sparky, xeasy |
602
sparky, xeasy |
95.86 |
| 4 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.568 – 132.958
C: 13.701 – 83.161
HN: 4.700 – 11.358 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
357
sparky, xeasy |
345
sparky, xeasy |
96.64 |
| 5 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | C1: 25.338 – 49.151
C2: 0.956 – 73.623
H1: -2.398 – 11.763 |
600 |
128.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2826
sparky, xeasy |
2786
sparky, xeasy |
98.58 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 103.568 – 132.958
C: 8.950 – 87.912
HN: 4.703 – 11.777 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
585
sparky, xeasy |
570
sparky, xeasy |
97.44 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 103.568 – 132.958
HN: 4.703 – 11.777
H: -0.238 – 9.690 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
433
sparky, xeasy |
415
sparky, xeasy |
95.84 |
| 8 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×1024 | N: 101.820 – 134.603
H: 4.699 – 12.030 |
600 |
1.00 |
N–H: spectrum, spectrum with peaks |
297
sparky, xeasy |
184
sparky, xeasy |
61.95 |
| 9 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×324×512 | N: 102.363 – 133.617
HN: 6.187 – 10.586
H: -2.271 – 11.702 |
800 |
88.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3914
sparky, xeasy |
2968
sparky, xeasy |
75.83 |
2M47 (163 residues, PDB,
BMRB, 2013)
Reference:
Yang, Y., Ramelot, T.A., Lee, D., Ciccosanti, C., Sapin, A., Janjua, H., Nair, R., Rost, B., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the Polyketide_cyc-like protein Cgl2372 from Corynebacterium glutamicum, Northeast Structural Genomics Consortium Target CgR160. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×547 | C: 6.112 – 85.800
H: -1.696 – 6.304 |
850 |
0.60 |
C–H: spectrum, spectrum with peaks |
712
sparky, xeasy |
657
sparky, xeasy |
92.28 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 108.161 – 142.028
H: 5.499 – 9.499 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
94
sparky, xeasy |
32
sparky, xeasy |
34.04 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×547×256 | C: 10.076 – 77.811
HC: -1.697 – 6.303
H: -1.672 – 11.277 |
850 |
140.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
7701
sparky, xeasy |
6844
sparky, xeasy |
88.87 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
205×111×256 | C: 111.536 – 135.445
HC: 6.219 – 8.145
H: -1.169 – 10.787 |
850 |
24.17 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
573
sparky, xeasy |
164
sparky, xeasy |
28.62 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×128×342 | N: 102.816 – 131.703
C: 14.600 – 78.100
HN: 5.006 – 10.995 |
600 |
44.63 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
595
sparky, xeasy |
548
sparky, xeasy |
92.10 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 102.934 – 131.707
C: 14.600 – 78.100
HN: 5.995 – 11.000 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
329
sparky, xeasy |
294
sparky, xeasy |
89.36 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×910 | C1: 11.444 – 77.186
C2: 11.420 – 77.163
H1: -1.710 – 6.291 |
600 |
231.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2476
sparky, xeasy |
2240
sparky, xeasy |
90.47 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×286 | N: 102.789 – 131.675
C: 13.348 – 79.090
HN: 5.996 – 11.001 |
600 |
72.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
509
sparky, xeasy |
451
sparky, xeasy |
88.61 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×286×256 | N: 102.787 – 131.674
HN: 5.995 – 11.000
H: 0.311 – 6.287 |
600 |
72.25 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
408
sparky, xeasy |
376
sparky, xeasy |
92.16 |
| 10 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×428 | C: 10.461 – 76.203
HC: -0.701 – 6.272
H: -1.010 – 6.489 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2582
sparky, xeasy |
2344
sparky, xeasy |
90.78 |
| 11 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×542 | C: 10.366 – 78.097
HC: -0.333 – 5.942
H: -1.990 – 7.511 |
600 |
136.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3650
sparky, xeasy |
3277
sparky, xeasy |
89.78 |
| 12 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 102.934 – 131.707
H: -0.692 – 6.253
HN: 5.990 – 10.995 |
600 |
18.06 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
733
sparky, xeasy |
644
sparky, xeasy |
87.86 |
| 13 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×377 | N: 105.697 – 134.489
C: 40.155 – 69.920
HN: 5.499 – 11.008 |
850 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
307
sparky, xeasy |
283
sparky, xeasy |
92.18 |
| 14 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×286 | N: 102.934 – 131.707
C: 166.301 – 181.962
HN: 5.995 – 11.000 |
600 |
9.84 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
141
sparky, xeasy |
83.43 |
| 15 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×286 | N: 102.934 – 131.707
C: 41.293 – 71.059
HN: 5.992 – 10.998 |
600 |
18.06 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
153
sparky, xeasy |
141
sparky, xeasy |
92.16 |
| 16 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×343 | N: 102.816 – 131.788
H: 5.995 – 11.006 |
850 |
1.48 |
N–H: spectrum, spectrum with peaks |
237
sparky, xeasy |
159
sparky, xeasy |
67.09 |
| 17 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×386×256 | N: 103.024 – 131.798
HN: 4.999 – 11.008
H: -1.670 – 11.279 |
850 |
51.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2761
sparky, xeasy |
2113
sparky, xeasy |
76.53 |
2K3A (163 residues, PDB,
BMRB, 2008)
Reference:
Rossi, P., Aramini, J.M., Xiao, R., Chen, C.X., Nwosu, C., Owens, L.A., Maglaqui, M., Nair, R., Fischer, M., Acton, T.B., Honig, B., Rost, B., Montelione, G.T. (2008). Structural elucidation of the Cys-His-Glu-Asn proteolytic relay in the secreted CHAP domain enzyme from the human pathogen Staphylococcus saprophyticus. Proteins 74: 515-519
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×478 | C: 4.522 – 79.335
H: -0.509 – 5.988 |
800 |
1.04 |
C–H: spectrum, spectrum with peaks |
571
sparky, xeasy |
540
sparky, xeasy |
94.57 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
512×512 | C: 107.796 – 147.729
H: 4.765 – 11.725 |
800 |
1.00 |
C–H: spectrum, spectrum with peaks |
74
sparky, xeasy |
54
sparky, xeasy |
72.97 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×478×256 | C: 33.968 – 57.778
HC: -0.509 – 5.988
H: -0.970 – 10.482 |
800 |
61.63 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9571
sparky, xeasy |
9126
sparky, xeasy |
95.35 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | C: 112.963 – 142.718
HC: 4.753 – 11.713
H: -0.956 – 10.496 |
800 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1050
sparky, xeasy |
938
sparky, xeasy |
89.33 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 105.775 – 130.583
C: 4.478 – 79.257
HN: 4.774 – 11.734 |
800 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
601
sparky, xeasy |
557
sparky, xeasy |
92.68 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | N: 105.834 – 130.642
C: 4.390 – 79.169
HN: 4.770 – 11.730 |
800 |
64.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
384
sparky, xeasy |
359
sparky, xeasy |
93.49 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×478 | C1: 31.912 – 55.722
C2: 6.392 – 81.171
H1: -0.503 – 5.994 |
800 |
61.63 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
1691
sparky, xeasy |
1613
sparky, xeasy |
95.39 |
| 8 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 105.775 – 130.583
HN: 4.770 – 11.730
H: -0.440 – 6.507 |
800 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
408
sparky, xeasy |
379
sparky, xeasy |
92.89 |
| 9 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×478 | C: 31.912 – 55.722
HC: -0.440 – 6.507
H: -0.508 – 5.990 |
800 |
30.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
1811
sparky, xeasy |
1710
sparky, xeasy |
94.42 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×478 | C: 31.856 – 55.665
HC: -0.442 – 6.505
H: -0.507 – 5.990 |
800 |
30.81 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2355
sparky, xeasy |
2242
sparky, xeasy |
95.20 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 105.834 – 130.642
C: 40.971 – 72.721
HN: 4.768 – 11.728 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
319
sparky, xeasy |
297
sparky, xeasy |
93.10 |
| 12 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 105.775 – 130.583
C: 167.852 – 189.764
HN: 4.770 – 11.730 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
201
sparky, xeasy |
150
sparky, xeasy |
74.63 |
| 13 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 105.775 – 130.583
C: 167.852 – 189.764
HN: 4.770 – 11.730 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
319
sparky, xeasy |
300
sparky, xeasy |
94.04 |
| 14 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 105.775 – 130.583
C: 40.971 – 72.721
HN: 4.768 – 11.728 |
800 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
159
sparky, xeasy |
149
sparky, xeasy |
93.71 |
| 15 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×512 | N: 105.622 – 130.522
H: 4.766 – 11.726 |
800 |
0.50 |
N–H: spectrum, spectrum with peaks |
222
sparky, xeasy |
194
sparky, xeasy |
87.39 |
| 16 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 105.719 – 130.522
HN: 4.771 – 11.731
H: -0.947 – 10.505 |
800 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3509
sparky, xeasy |
3212
sparky, xeasy |
91.54 |
| 17 |
N15TOCSY
ucsf, pipe, .3D.16, .3D.param |
64×512×256 | N: 106.048 – 130.657
HN: 4.777 – 11.753
H: -0.689 – 10.267 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
818
sparky, xeasy |
716
sparky, xeasy |
87.53 |
2M7U (165 residues, PDB,
BMRB, 2013)
Reference:
Cornilescu, C.C. Structural and Flexibility Variations Between the Ground and Photoactivated States of a Blue/Green Light-Absorbing Cyanobacteriochrome. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×1364 | C: 1.763 – 81.611
H: -0.997 – 9.004 |
800 |
2.82 |
C–H: spectrum, spectrum with peaks |
721
sparky, xeasy |
570
sparky, xeasy |
79.06 |
| 2 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×875×197 | C: 10.302 – 79.372
HC: -0.995 – 6.499
H: -0.502 – 10.986 |
800 |
91.44 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
17831
sparky, xeasy |
13437
sparky, xeasy |
75.36 |
| 3 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×468×512 | C: 111.187 – 140.783
HC: 4.996 – 9.000
H: -1.205 – 13.769 |
800 |
123.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
1706
sparky, xeasy |
773
sparky, xeasy |
45.31 |
| 4 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×1797 | N: 101.537 – 135.267
C: 12.649 – 82.381
HN: 5.799 – 13.110 |
600 |
231.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
624
sparky, xeasy |
563
sparky, xeasy |
90.22 |
| 5 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×1797 | N: 101.537 – 135.267
C: 12.649 – 82.381
HN: 5.800 – 13.112 |
600 |
231.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
375
sparky, xeasy |
333
sparky, xeasy |
88.80 |
| 6 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
64×256×861 | N: 101.802 – 135.267
C: 7.691 – 87.378
HN: 5.799 – 12.801 |
600 |
56.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
590
sparky, xeasy |
506
sparky, xeasy |
85.76 |
| 7 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
64×861×256 | N: 101.802 – 135.267
HN: 5.796 – 12.799
H: 0.296 – 6.273 |
600 |
56.31 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
422
sparky, xeasy |
358
sparky, xeasy |
84.83 |
| 8 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×1721 | N: 101.537 – 135.267
H: -0.712 – 6.278
HN: 5.800 – 12.802 |
600 |
437.25 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
839
sparky, xeasy |
664
sparky, xeasy |
79.14 |
| 9 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×860 | N: 101.537 – 135.267
C: 167.989 – 182.870
HN: 6.002 – 12.996 |
600 |
56.31 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
191
sparky, xeasy |
142
sparky, xeasy |
74.35 |
| 10 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
512×1657 | N: 98.476 – 138.398
H: 5.803 – 13.904 |
800 |
3.42 |
N–H: spectrum, spectrum with peaks |
262
sparky, xeasy |
185
sparky, xeasy |
70.61 |
| 11 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1533×778 | N: 102.194 – 135.930
HN: 6.007 – 12.804
H: -0.989 – 12.800 |
800 |
599.80 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
6167
sparky, xeasy |
4455
sparky, xeasy |
72.24 |
2B3W (168 residues, PDB,
BMRB, 2005)
Reference:
Ramelot, T.A., Cort, J.R., Xiao, R., Shih, L.Y., Acton, T.B., Montelione, G.T., Kennedy, M.A.. NMR structure of the E.coli protein YbiA, Northeast Structural Genomics target ET24. To be published.
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×385 | C: -2.168 – 82.500
H: -1.004 – 6.003 |
750 |
0.47 |
C–H: spectrum, spectrum with peaks |
768
sparky, xeasy |
728
sparky, xeasy |
94.79 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
439×275 | C: 110.063 – 140.005
H: 4.997 – 9.997 |
750 |
0.71 |
C–H: spectrum, spectrum with peaks |
96
sparky, xeasy |
85
sparky, xeasy |
88.54 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×483×256 | C: 31.082 – 54.989
HC: -2.000 – 7.010
H: -1.839 – 11.451 |
600 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8901
sparky, xeasy |
8226
sparky, xeasy |
92.42 |
| 4 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×486×256 | C: 31.268 – 55.081
HC: -1.996 – 7.004
H: -1.916 – 11.532 |
800 |
63.75 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
8901
sparky, xeasy |
8226
sparky, xeasy |
92.42 |
| 5 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×275×256 | C: 110.212 – 139.979
HC: 5.000 – 10.000
H: -1.839 – 11.451 |
750 |
36.13 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
801
sparky, xeasy |
727
sparky, xeasy |
90.76 |
| 6 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.371 – 134.659
C: 15.518 – 77.034
HN: 5.007 – 11.998 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
628
sparky, xeasy |
568
sparky, xeasy |
90.45 |
| 7 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.379 – 134.667
C: 15.446 – 76.961
HN: 5.006 – 11.997 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
365
sparky, xeasy |
336
sparky, xeasy |
92.05 |
| 8 |
CBHDaro
ucsf, pipe, .3D.16, .3D.param |
256×342 | C: 20.114 – 50.003
H: 5.000 – 9.998 |
600 |
0.42 |
C–H: spectrum, spectrum with peaks |
54
sparky, xeasy |
36
sparky, xeasy |
66.67 |
| 9 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×1024 | C1: 31.162 – 54.981
C2: 5.814 – 80.520
H1: -4.783 – 14.339 |
600 |
128.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2725
sparky, xeasy |
2600
sparky, xeasy |
95.41 |
| 10 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.897 – 33.950
C2: 13.897 – 33.950
H1: -3.651 – 9.664
H2: -0.445 – 6.500 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
6435
sparky, xeasy |
6191
sparky, xeasy |
96.21 |
| 11 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.379 – 134.667
C: 12.074 – 73.590
HN: 5.008 – 11.999 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
566
sparky, xeasy |
527
sparky, xeasy |
93.11 |
| 12 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×241×1024 | C: 31.206 – 55.019
HC: -0.988 – 6.513
H: -4.762 – 14.361 |
600 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2898
sparky, xeasy |
2748
sparky, xeasy |
94.82 |
| 13 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×241×1024 | C: 31.214 – 55.026
HC: -0.999 – 6.501
H: -4.774 – 14.348 |
600 |
127.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
4178
sparky, xeasy |
3984
sparky, xeasy |
95.36 |
| 14 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.371 – 134.659
H: -1.396 – 7.038
HN: 5.001 – 11.992 |
600 |
24.44 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
844
sparky, xeasy |
786
sparky, xeasy |
93.13 |
| 15 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.371 – 134.659
C: 41.293 – 71.059
HN: 5.010 – 12.001 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
323
sparky, xeasy |
292
sparky, xeasy |
90.40 |
| 16 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×64×375 | N: 100.372 – 134.659
C: 167.259 – 180.967
HN: 5.004 – 11.995 |
600 |
12.94 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
187
sparky, xeasy |
153
sparky, xeasy |
81.82 |
| 17 |
HNHA
ucsf, pipe, .3D.16, .3D.param |
128×256×375 | N: 100.181 – 136.101
H: 2.533 – 10.838
HN: 5.004 – 11.995 |
600 |
48.88 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
462
sparky, xeasy |
376
sparky, xeasy |
81.39 |
| 18 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×375 | N: 100.360 – 134.648
C: 42.200 – 71.966
HN: 5.006 – 11.997 |
600 |
24.44 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
161
sparky, xeasy |
146
sparky, xeasy |
90.68 |
| 19 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
256×385 | N: 100.004 – 136.067
H: 5.002 – 12.009 |
750 |
0.47 |
N–H: spectrum, spectrum with peaks |
286
sparky, xeasy |
182
sparky, xeasy |
63.64 |
| 20 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×385×512 | N: 100.191 – 136.115
HN: 5.002 – 12.009
H: -1.859 – 11.456 |
750 |
102.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3362
sparky, xeasy |
2479
sparky, xeasy |
73.74 |
KRAS4B (169 residues)
Reference:
Not available
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
1002×2206 | C: 4.309 – 72.737
H: -1.148 – 6.391 |
700 |
9.00 |
C–H: spectrum, spectrum with peaks |
752
sparky, xeasy |
586
sparky, xeasy |
77.93 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
313×578 | C: 109.459 – 134.674
H: 5.713 – 7.687 |
600 |
0.94 |
C–H: spectrum, spectrum with peaks |
70
sparky, xeasy |
55
sparky, xeasy |
78.57 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×1046×430 | C: 0.487 – 75.193
HC: -0.867 – 6.421
H: -0.881 – 10.849 |
700 |
457.54 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
13120
sparky, xeasy |
9489
sparky, xeasy |
72.32 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×272×392 | C: 0.678 – 75.385
HC: 6.174 – 8.064
H: -0.885 – 9.806 |
700 |
125.15 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
893
sparky, xeasy |
704
sparky, xeasy |
78.84 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×256×2048 | N: 99.028 – 134.751
C: 5.001 – 74.728
HN: 4.693 – 11.691 |
700 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
636
sparky, xeasy |
624
sparky, xeasy |
98.11 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×256×2048 | N: 99.041 – 134.764
C: 4.670 – 74.396
HN: 4.699 – 11.697 |
700 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
369
sparky, xeasy |
354
sparky, xeasy |
95.93 |
| 7 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 98.833 – 134.693
C: 2.833 – 74.692
HN: 4.692 – 11.687 |
700 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
574
sparky, xeasy |
543
sparky, xeasy |
94.60 |
| 8 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×512×1024 | N: 99.143 – 135.002
C: 3.142 – 75.001
HN: 4.707 – 11.702 |
700 |
512.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
574
sparky, xeasy |
543
sparky, xeasy |
94.60 |
| 9 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×723×519 | N: 98.870 – 134.729
HN: 6.151 – 10.992
H: -0.509 – 6.573 |
700 |
391.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
436
sparky, xeasy |
388
sparky, xeasy |
88.99 |
| 10 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×307×1060 | C: -0.528 – 74.179
HC: -1.485 – 6.882
H: -0.793 – 6.448 |
700 |
340.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
3964
sparky, xeasy |
2463
sparky, xeasy |
62.13 |
| 11 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×256×2048 | N: 99.012 – 134.731
C: 37.827 – 69.702
HN: 4.698 – 11.696 |
700 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
329
sparky, xeasy |
326
sparky, xeasy |
99.09 |
| 12 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×256×2048 | N: 99.029 – 134.748
C: 37.827 – 69.702
HN: 4.698 – 11.696 |
700 |
256.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
164
sparky, xeasy |
163
sparky, xeasy |
99.39 |
| 13 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
988×1425 | N: 99.197 – 133.896
H: 6.085 – 10.953 |
700 |
6.00 |
N–H: spectrum, spectrum with peaks |
257
sparky, xeasy |
185
sparky, xeasy |
71.98 |
| 14 |
N15NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×342×419 | N: 97.126 – 136.463
HN: 6.071 – 10.827
H: -0.638 – 10.792 |
700 |
156.52 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
3975
sparky, xeasy |
3056
sparky, xeasy |
76.88 |
2G0Q (173 residues, PDB,
BMRB, 2006)
Reference:
Lytle, B.L., Peterson, F.C., Tyler, E.M., Newman, C.L., Vinarov, D.A., Markley, J.L., Volkman, B.F. (2006). Solution structure of Arabidopsis thaliana protein At5g39720.1, a member of the AIG2-like protein family. Acta Crystallogr Sect F Struct Biol Cryst Commun 62: 490-493.
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13NOESY
ucsf, pipe, .3D.16, .3D.param |
128×1024×256 | C: 22.859 – 63.969
HC: -3.526 – 13.128
H: -2.096 – 11.741 |
600 |
128.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
9482
sparky, xeasy |
7026
sparky, xeasy |
74.10 |
| 2 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | C: 110.702 – 143.589
HC: 4.811 – 13.129
H: -2.099 – 11.738 |
600 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
700
sparky, xeasy |
317
sparky, xeasy |
45.29 |
| 3 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.638 – 135.280
C: 1.728 – 83.948
HN: 4.825 – 13.144 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
638
sparky, xeasy |
546
sparky, xeasy |
85.58 |
| 4 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.900 – 135.542
C: 2.557 – 84.777
HN: 4.825 – 13.144 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
576
sparky, xeasy |
466
sparky, xeasy |
80.90 |
| 5 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
128×512×128 | N: 102.635 – 135.277
HN: 4.823 – 13.142
H: -1.022 – 7.248 |
600 |
32.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
452
sparky, xeasy |
355
sparky, xeasy |
78.54 |
| 6 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
128×256×512 | C: 22.885 – 63.995
HC: -1.060 – 7.242
H: -1.075 – 7.244 |
600 |
64.00 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
4272
sparky, xeasy |
2697
sparky, xeasy |
63.13 |
| 7 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.640 – 135.282
C: 33.892 – 75.001
HN: 4.824 – 13.143 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
331
sparky, xeasy |
282
sparky, xeasy |
85.20 |
| 8 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.638 – 135.280
C: 169.532 – 182.685
HN: 4.826 – 13.145 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
193
sparky, xeasy |
142
sparky, xeasy |
73.58 |
| 9 |
HNcaCO
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.635 – 135.277
C: 169.534 – 182.688
HN: 4.825 – 13.144 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
331
sparky, xeasy |
283
sparky, xeasy |
85.50 |
| 10 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
128×128×512 | N: 102.638 – 135.280
C: 33.863 – 74.972
HN: 4.822 – 13.141 |
600 |
32.00 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
165
sparky, xeasy |
142
sparky, xeasy |
86.06 |
| 11 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×1024 | N: 102.686 – 135.553
H: 4.816 – 13.143 |
600 |
4.00 |
N–H: spectrum, spectrum with peaks |
262
sparky, xeasy |
171
sparky, xeasy |
65.27 |
| 12 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×512×256 | N: 102.921 – 135.563
HN: 4.825 – 13.144
H: -2.086 – 11.751 |
600 |
64.00 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
2854
sparky, xeasy |
2167
sparky, xeasy |
75.93 |
2LF2 (175 residues, PDB,
BMRB, 2011)
Reference:
Yang, Y., Ramelot, T.A., Lee, D., Ciccosanti, C., Acton, T.B., Xiao, R., Everett, J.K., Montelione, G.T., Kennedy, M.A. Solution NMR structure of the AHSA1-like protein CHU_1110 from Cytophaga hutchinsonii, Northeast Structural Genomics Consortium Target ChR152. To be published
Experimental data:
- Deposited structure
- Deposited chemical shifts
|
Experimentally derived data:
- ARTINA structure (based on experimental data)
- ARTINA chemical shifts (based on experimental data)
|
In-silico data:
- AlphaFold structure
- UCBShift chemical shift predictions (based on AlphaFold structure)
|
| # | Experiment type | Size | PPM range | Spectrometer
frequency [MHz] | File size [MB] |
Visualizations | Back-calculated cross-peaks
[?]
Expected peak lists are not experimental peak lists (which are not available from BMRB or PDB depositions for most spectra) but lists of peaks expected based on sequence, experiment type and deposited protein structure.
Assigned peaks are the subset of expected peaks for which deposited chemical shifts are available. Visualizations show these assigned back-calculated cross-peaks.
% assigned fraction of expected peak list present in assigned peak list
|
|---|
| Expected | Assigned | % assigned |
|---|
| 1 |
C13HSQC (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×527 | C: 6.112 – 85.800
H: -1.506 – 6.201 |
850 |
0.57 |
C–H: spectrum, spectrum with peaks |
780
sparky, xeasy |
744
sparky, xeasy |
95.38 |
| 2 |
C13HSQC (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274 | C: 108.131 – 142.001
H: 5.498 – 9.498 |
850 |
0.33 |
C–H: spectrum, spectrum with peaks |
107
sparky, xeasy |
63
sparky, xeasy |
58.88 |
| 3 |
C13NOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
512×547×256 | C: 11.925 – 75.800
HC: -1.506 – 6.494
H: -1.421 – 11.030 |
850 |
280.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
12403
sparky, xeasy |
11590
sparky, xeasy |
93.45 |
| 4 |
C13NOESY (aromatic)
ucsf, pipe, .3D.16, .3D.param |
256×274×256 | C: 111.381 – 141.266
HC: 5.498 – 9.498
H: -1.421 – 11.030 |
850 |
72.25 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
H–HC: projection, projection with peaks |
996
sparky, xeasy |
582
sparky, xeasy |
58.43 |
| 5 |
CBCANH
ucsf, pipe, .3D.16, .3D.param |
256×256×342 | N: 103.047 – 132.930
C: 14.250 – 78.000
HN: 5.502 – 11.505 |
600 |
89.25 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
657
sparky, xeasy |
635
sparky, xeasy |
96.65 |
| 6 |
CBCAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×128×370 | N: 103.047 – 132.930
C: 14.008 – 78.500
HN: 5.502 – 11.998 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
368
sparky, xeasy |
358
sparky, xeasy |
97.28 |
| 7 |
CCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×399 | C1: 4.838 – 70.581
C2: 4.839 – 70.581
H1: -1.009 – 5.981 |
600 |
102.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C2–H1: projection, projection with peaks |
2754
sparky, xeasy |
2650
sparky, xeasy |
96.22 |
| 8 |
CCNOESY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
32×32×1024×128 | C1: 13.940 – 33.987
C2: 13.940 – 33.987
H1: -3.685 – 9.638
H2: -0.474 – 6.469 |
600 |
512.00 |
C1–C2: projection, projection with peaks
C1–H1: projection, projection with peaks
C1–H2: projection, projection with peaks
C2–H1: projection, projection with peaks
H2–C2: projection, projection with peaks
H2–H1: projection, projection with peaks |
5908
sparky, xeasy |
5674
sparky, xeasy |
96.04 |
| 9 |
CcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×128×370 | N: 103.047 – 132.930
C: 14.500 – 78.000
HN: 5.502 – 11.998 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
562
sparky, xeasy |
549
sparky, xeasy |
97.69 |
| 10 |
HBHAcoNH
ucsf, pipe, .3D.16, .3D.param |
256×370×256 | N: 103.047 – 132.930
HN: 5.502 – 11.998
H: 0.050 – 7.022 |
600 |
97.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
HN–H: projection, projection with peaks |
452
sparky, xeasy |
434
sparky, xeasy |
96.02 |
| 11 |
HCCHCOSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×427 | C: 8.357 – 78.081
HC: -0.681 – 6.292
H: -0.989 – 6.511 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
2870
sparky, xeasy |
2753
sparky, xeasy |
95.92 |
| 12 |
HCCHTOCSY (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×427 | C: 8.352 – 78.086
HC: -0.681 – 6.292
H: -0.994 – 6.505 |
600 |
110.50 |
C–HC: projection, projection with peaks
C–H: projection, projection with peaks
HC–H: projection, projection with peaks |
4152
sparky, xeasy |
3997
sparky, xeasy |
96.27 |
| 13 |
HCcoNH (aliphatic)
ucsf, pipe, .3D.16, .3D.param |
256×256×370 | N: 103.047 – 132.930
H: -0.689 – 6.284
HN: 5.502 – 11.998 |
600 |
97.75 |
N–H: projection, projection with peaks
N–HN: projection, projection with peaks
H–HN: projection, projection with peaks |
818
sparky, xeasy |
795
sparky, xeasy |
97.19 |
| 14 |
HNCA
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.047 – 132.930
C: 41.305 – 71.070
HN: 5.501 – 12.005 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
339
sparky, xeasy |
328
sparky, xeasy |
96.76 |
| 15 |
HNCO
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.047 – 132.930
C: 168.093 – 183.968
HN: 5.500 – 11.998 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
189
sparky, xeasy |
184
sparky, xeasy |
97.35 |
| 16 |
HNcoCA
ucsf, pipe, .3D.16, .3D.param |
256×128×371 | N: 103.047 – 132.930
C: 41.234 – 71.000
HN: 5.501 – 12.005 |
600 |
48.88 |
N–C: projection, projection with peaks
N–HN: projection, projection with peaks
C–HN: projection, projection with peaks |
169
sparky, xeasy |
164
sparky, xeasy |
97.04 |
| 17 |
N15HSQC
ucsf, pipe, .3D.16, .3D.param |
1024×370 | N: 104.945 – 132.918
H: 5.502 – 11.998 |
600 |
1.62 |
N–H: spectrum, spectrum with peaks |
255
sparky, xeasy |
192
sparky, xeasy |
75.29 |
| 18 |
N15NOESY
ucsf, pipe, .3D.16, .3D.param |
128×372×512 | N: 104.219 – 132.000
HN: 5.498 – 11.995
H: -1.446 – 11.030 |
850 |
97.75 |
N–HN: projection, projection with peaks
N–H: projection, projection with peaks
H–HN: projection, projection with peaks |
4445
sparky, xeasy |
3726
sparky, xeasy |
83.82 |
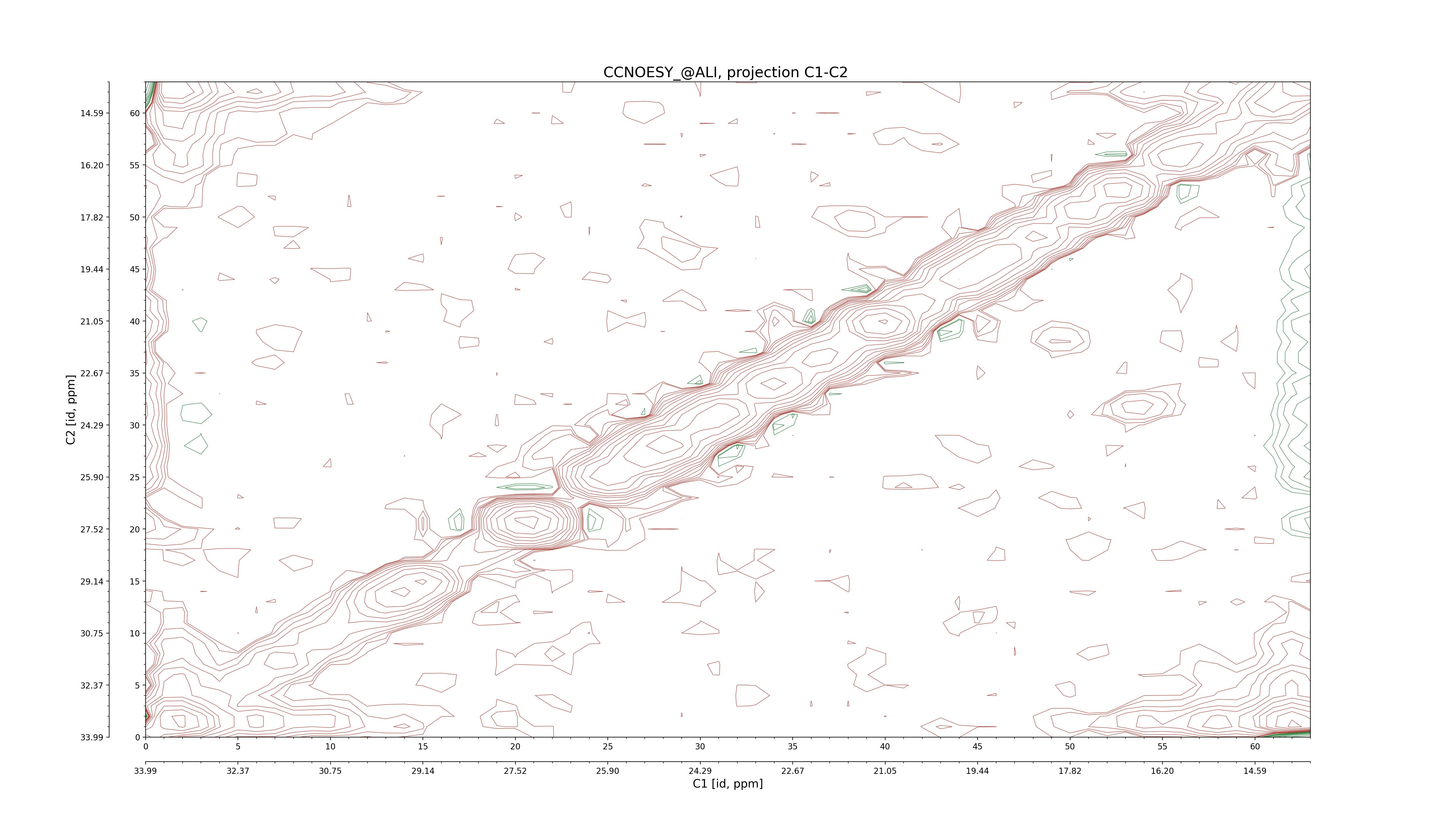{kind=link}
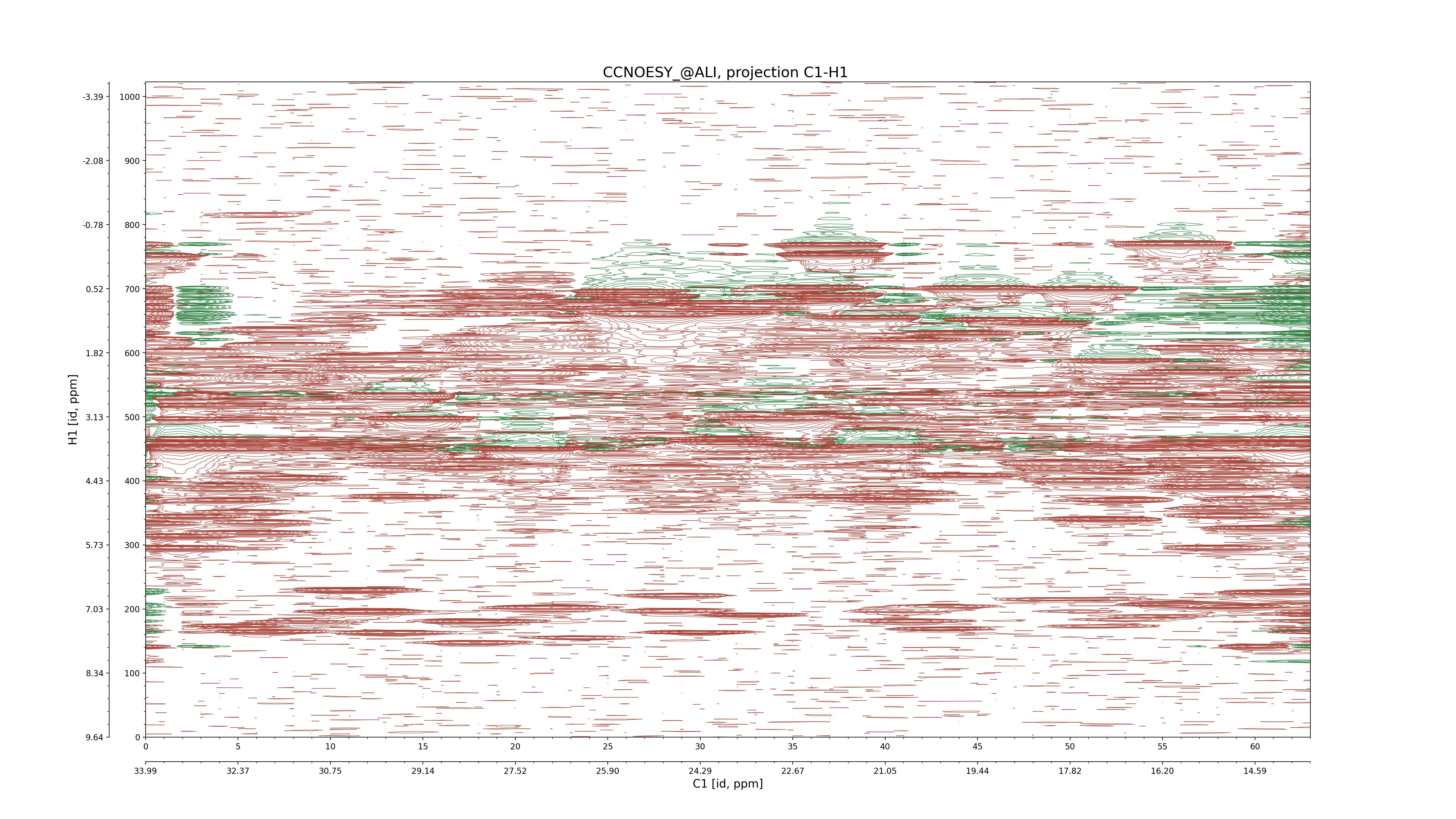{kind=link}
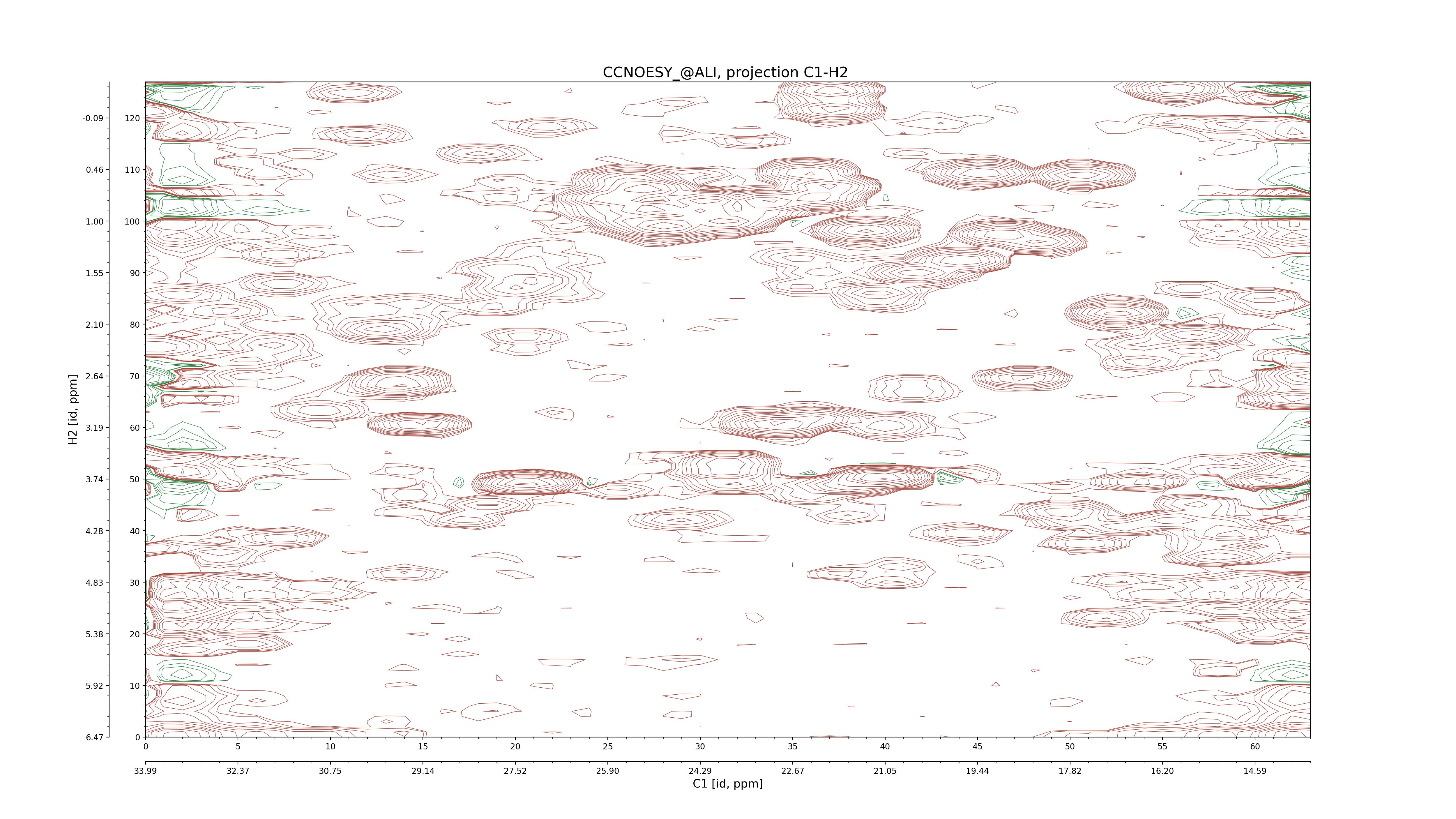{kind=link}
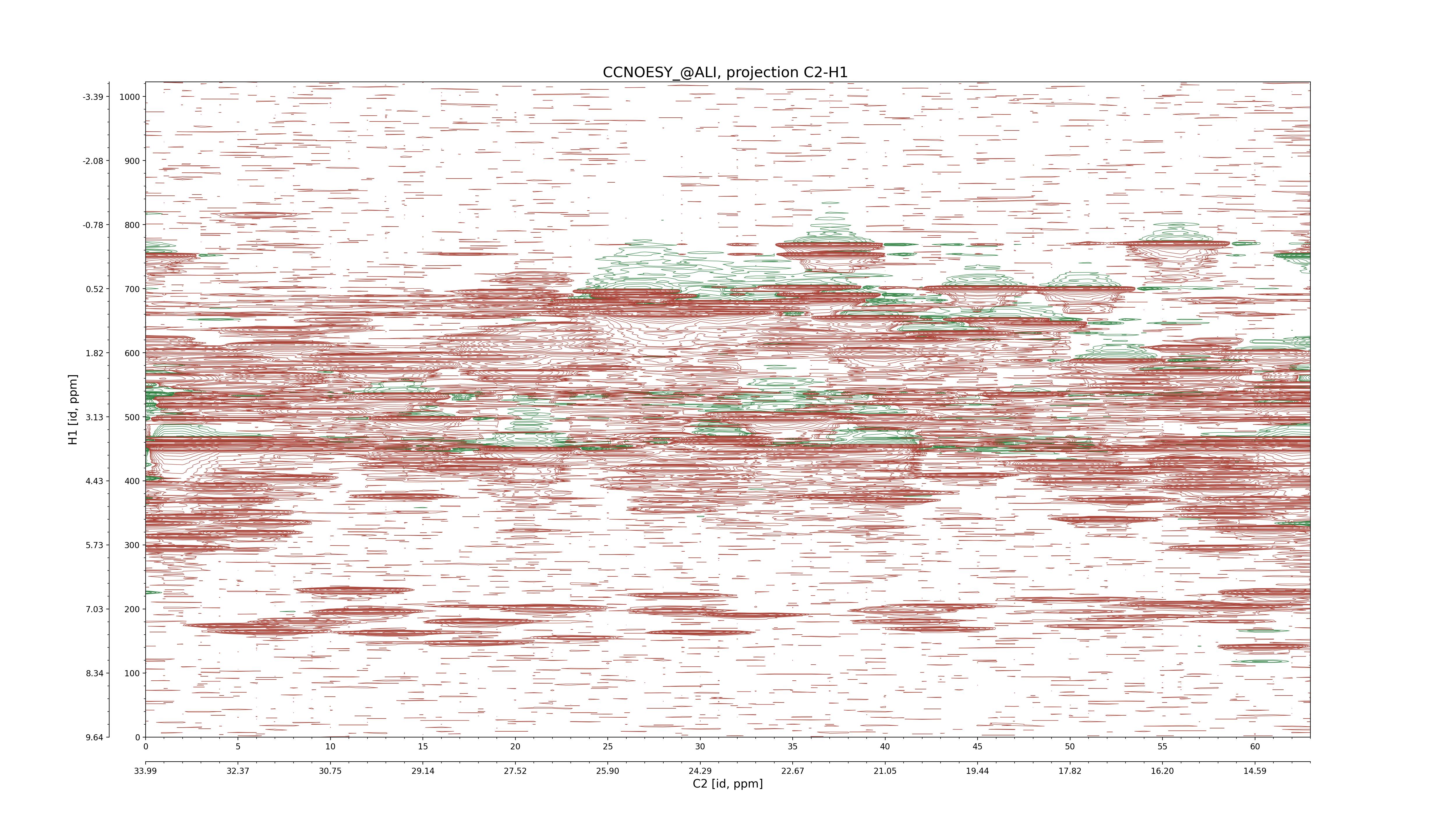{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
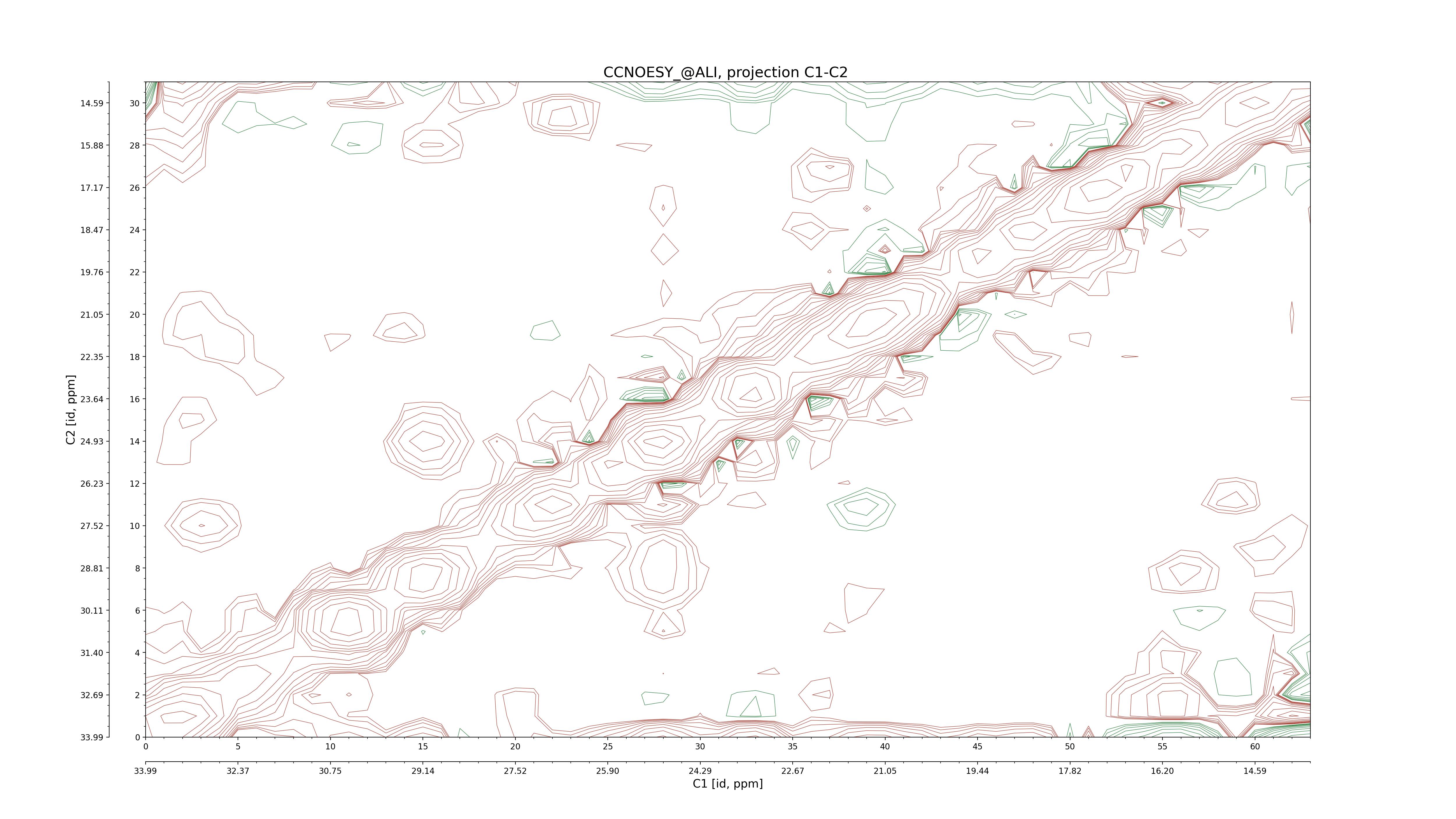{kind=link}
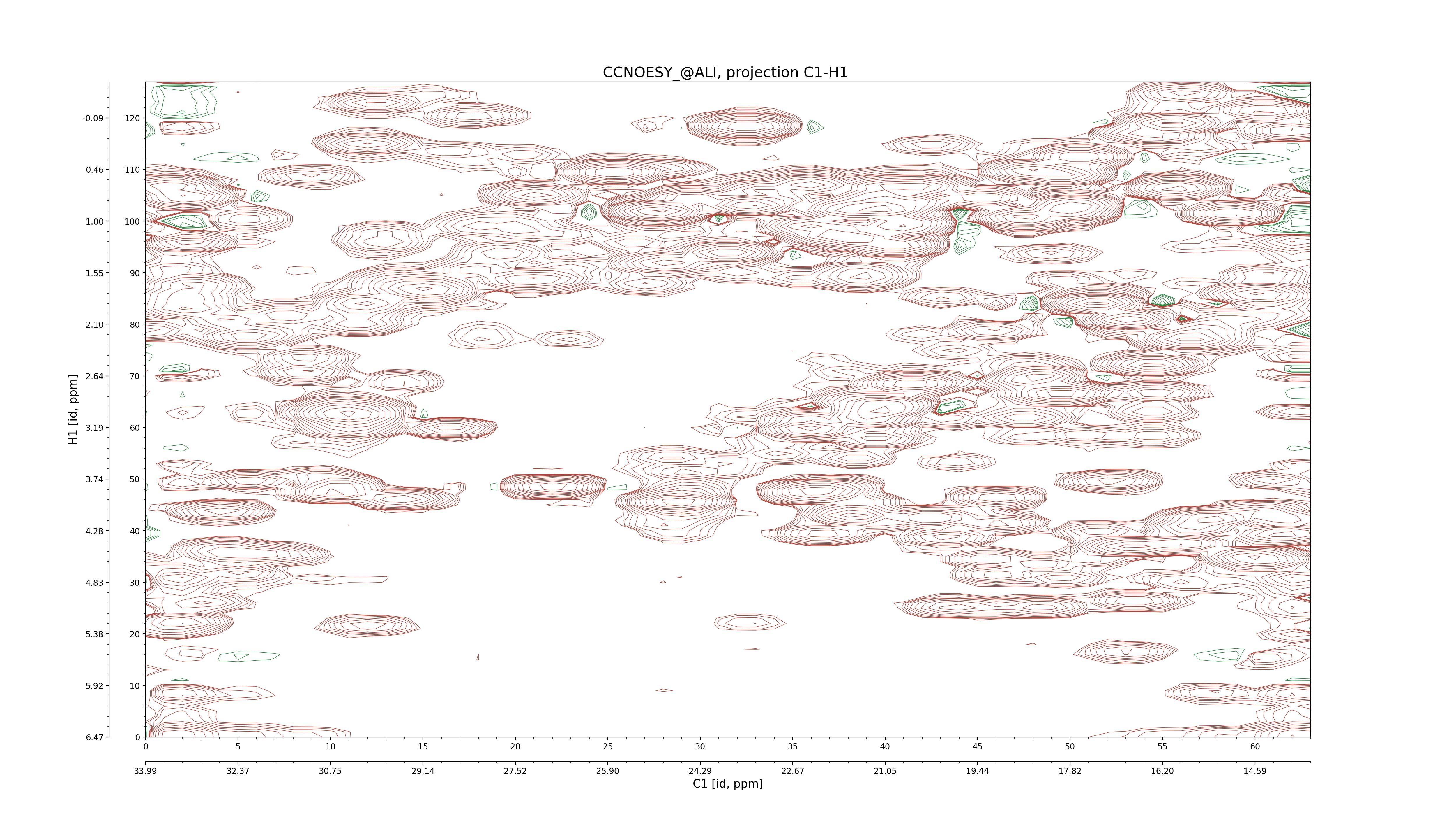{kind=link}
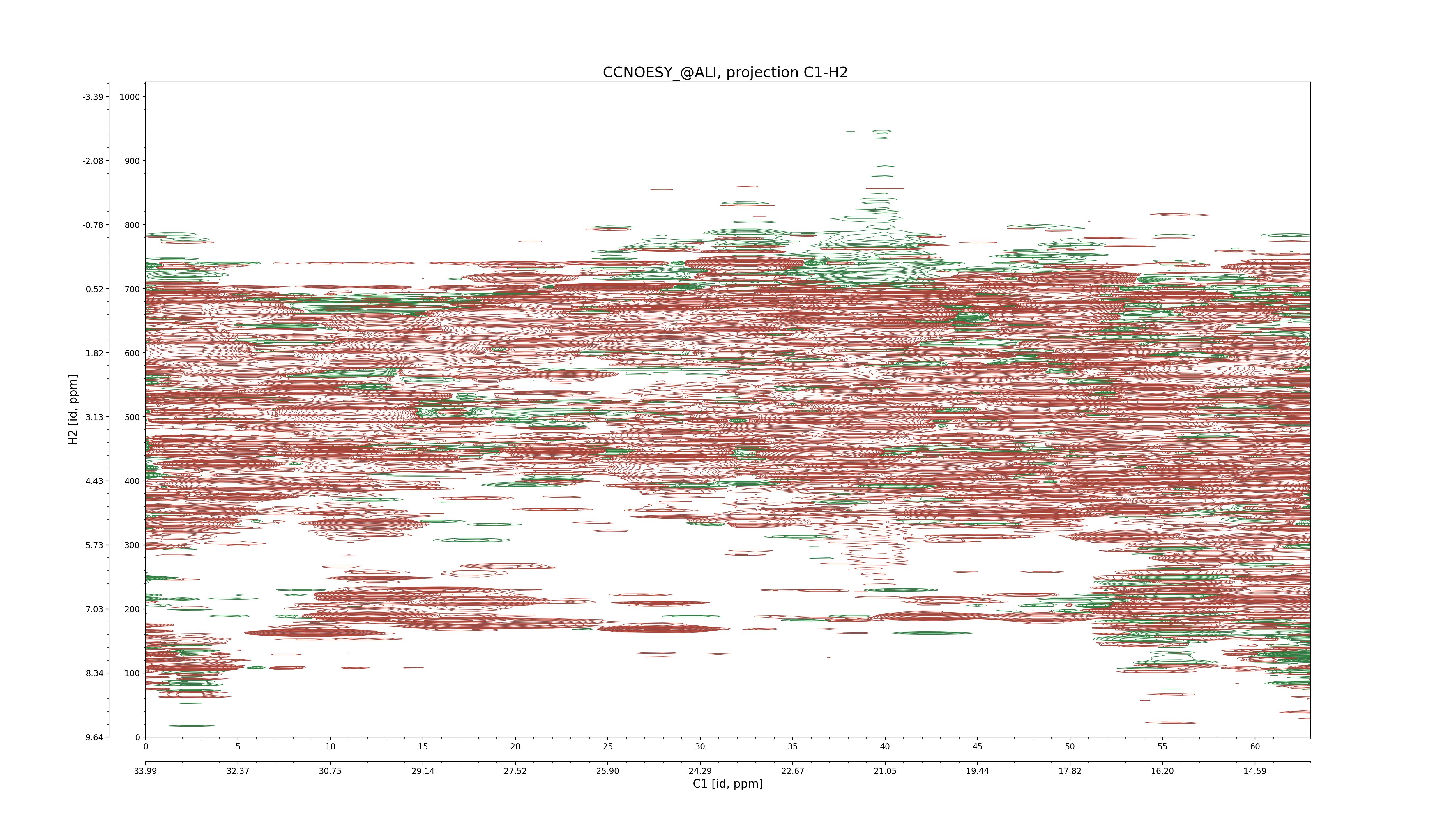{kind=link}
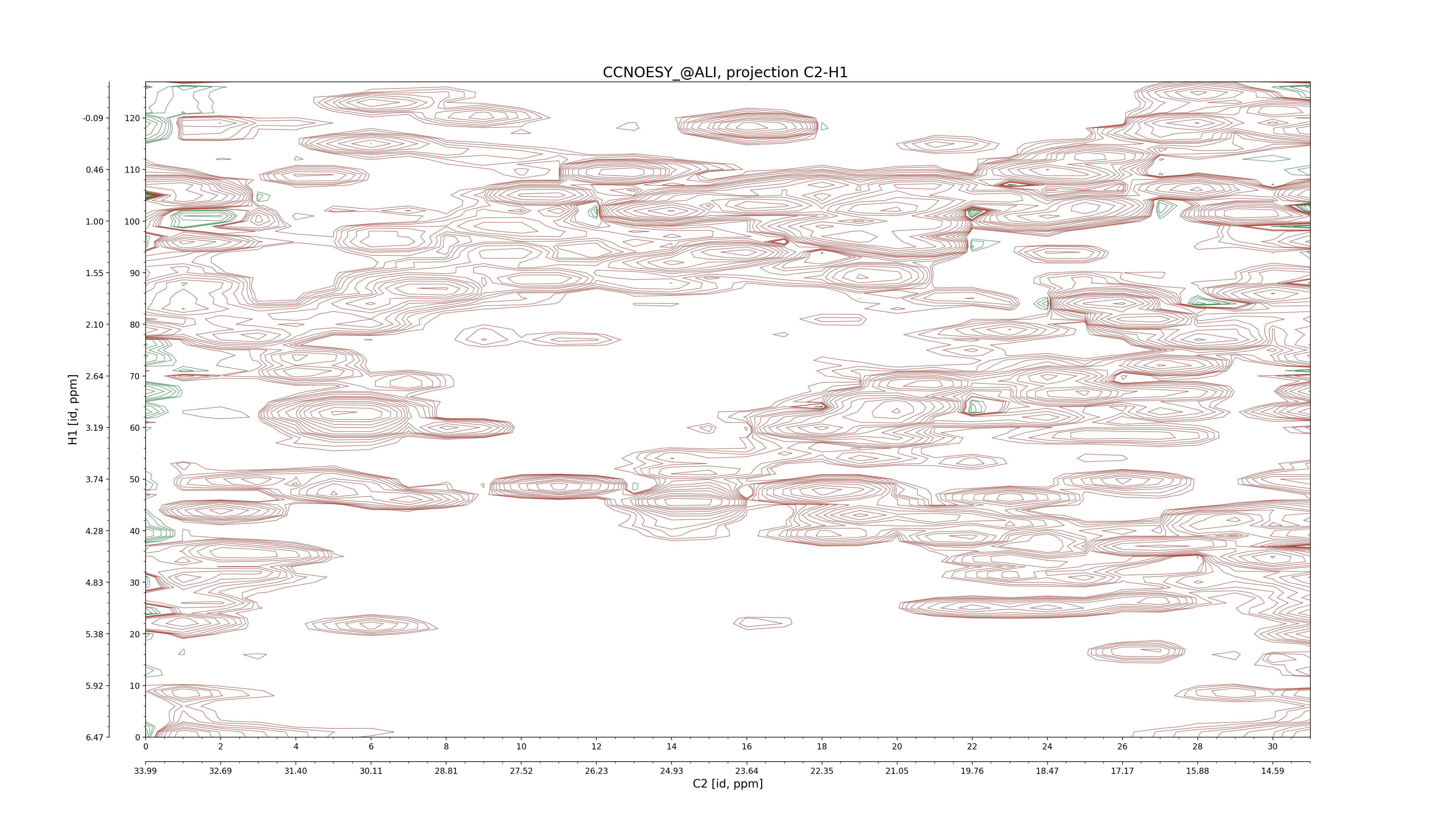{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
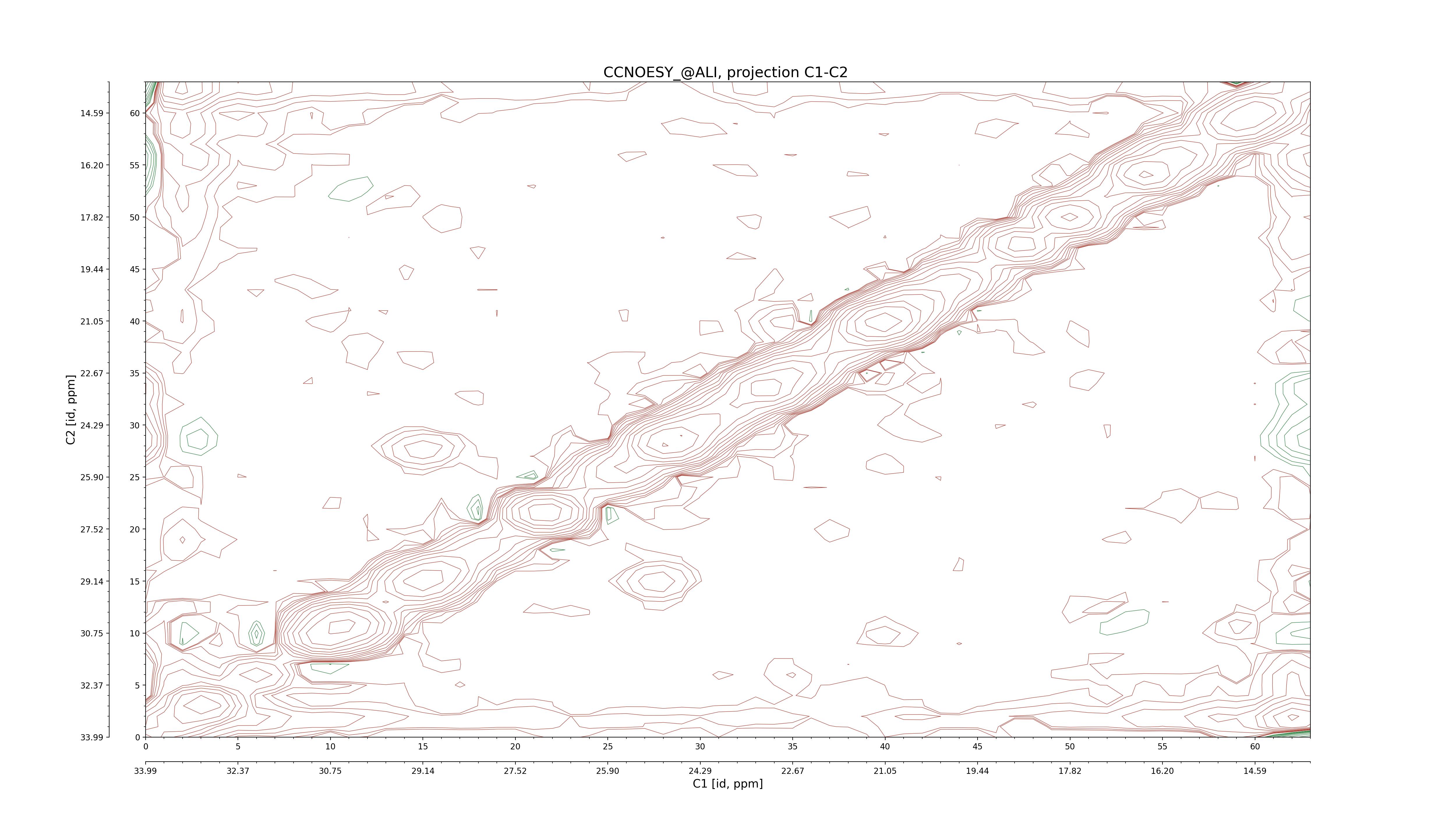{kind=link}
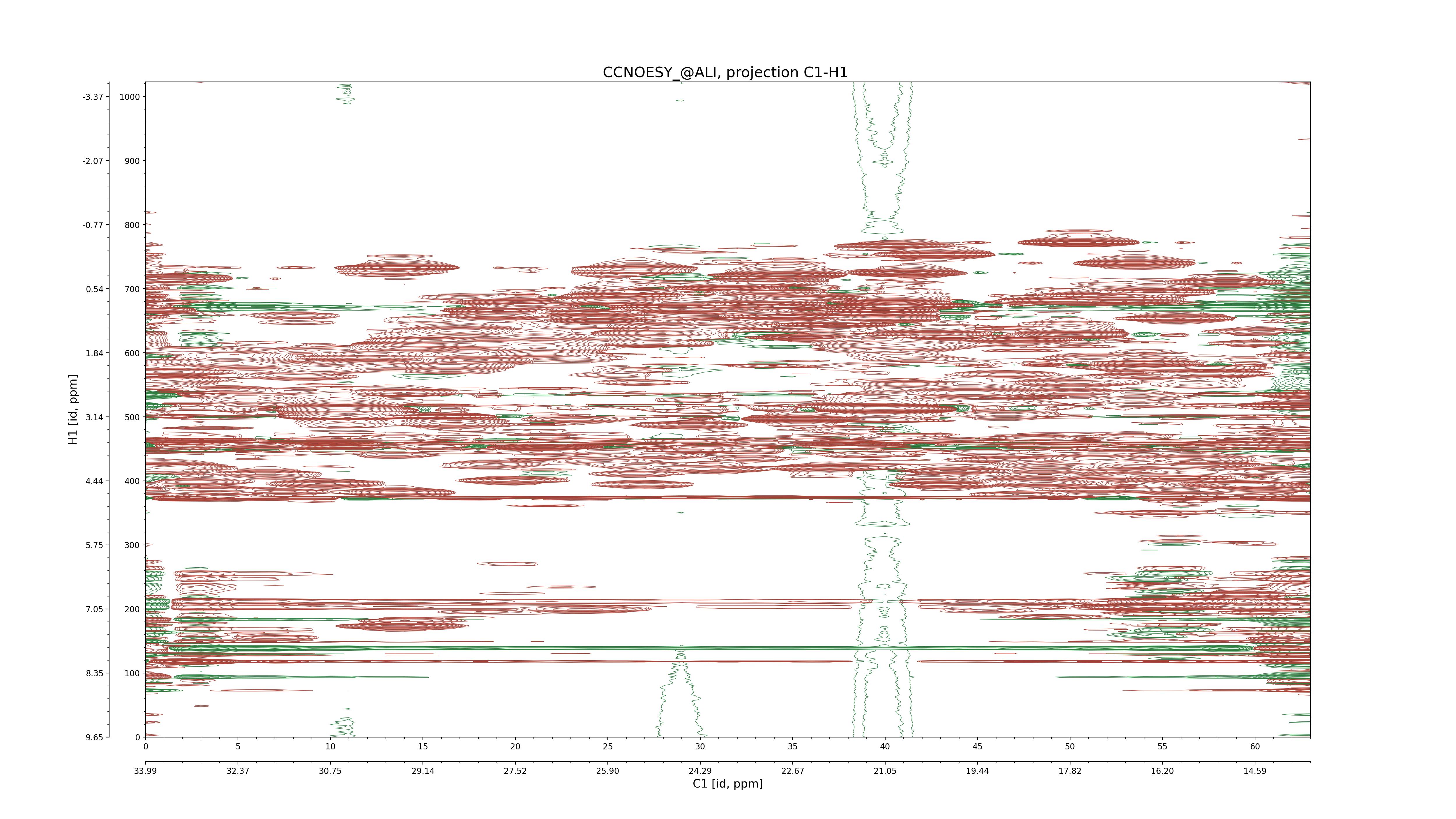{kind=link}
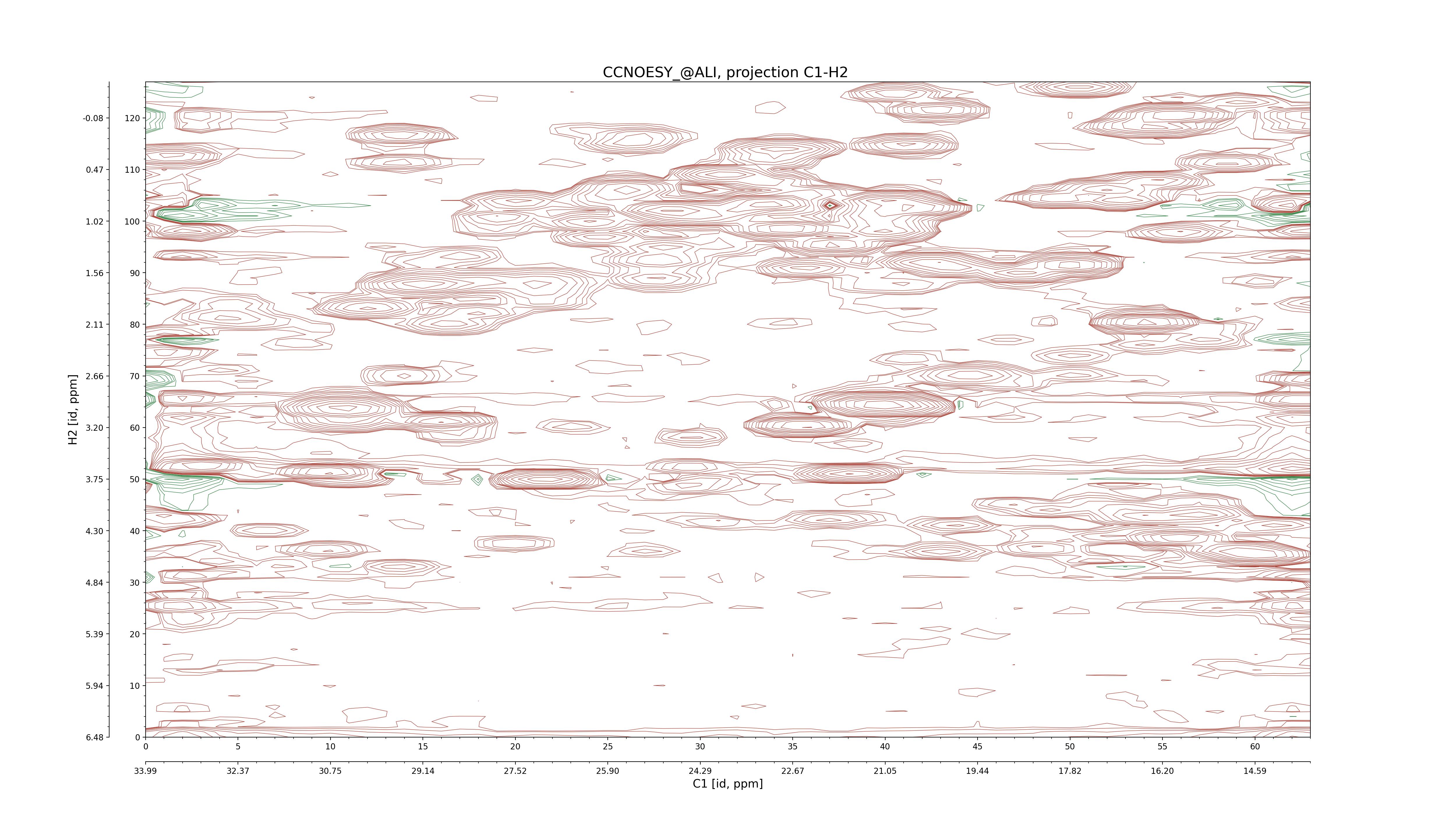{kind=link}
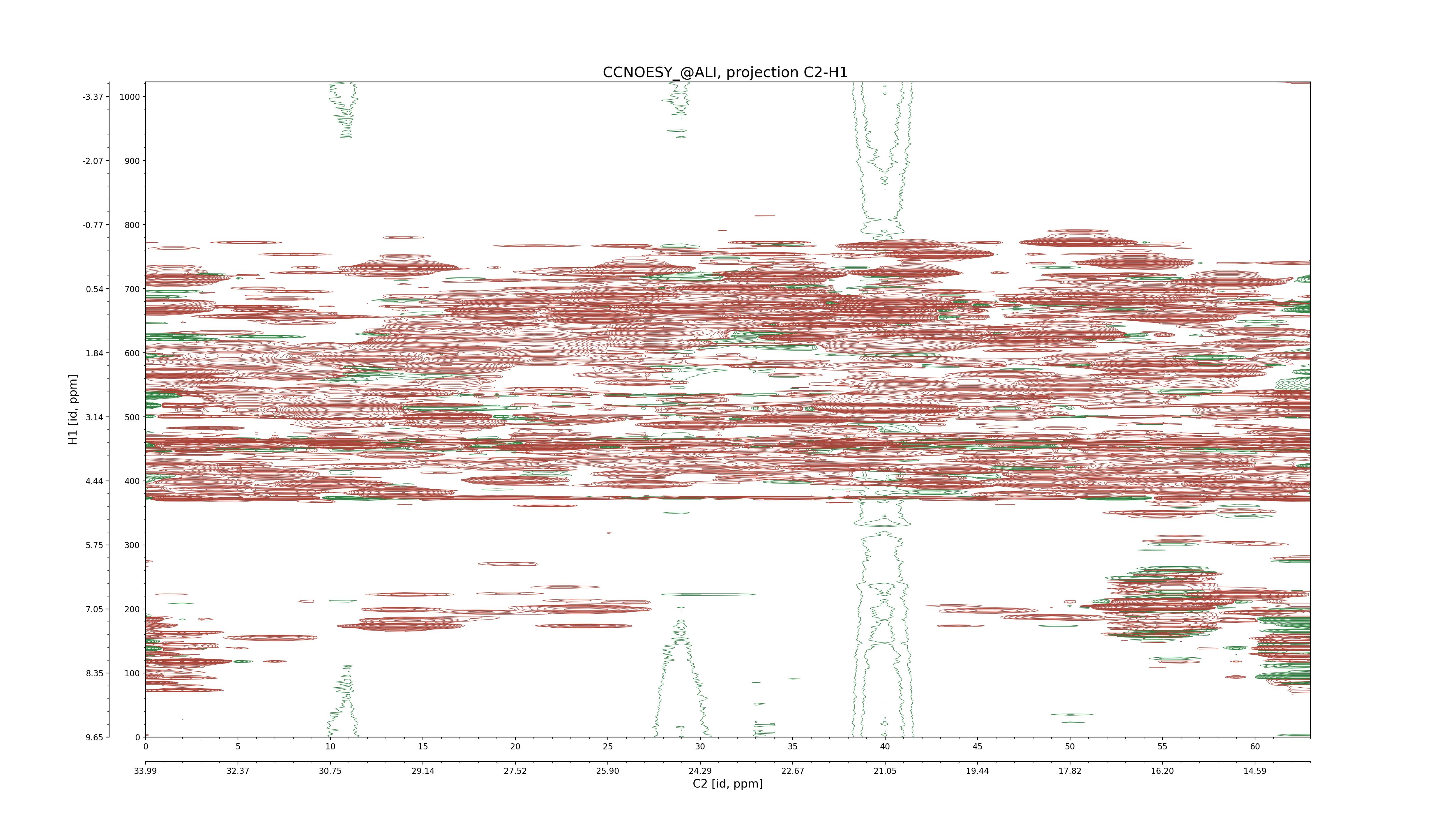{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
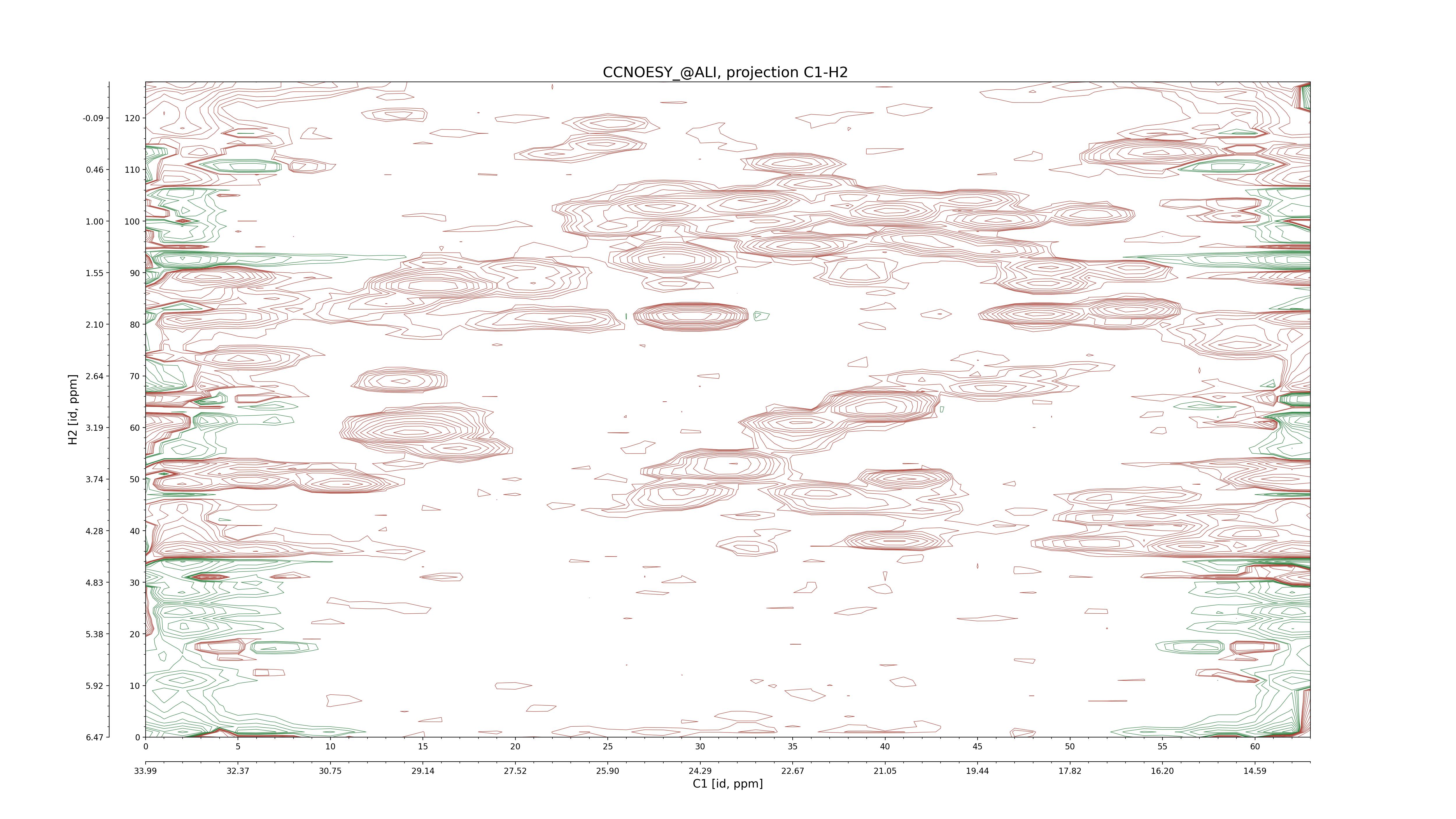{kind=link}
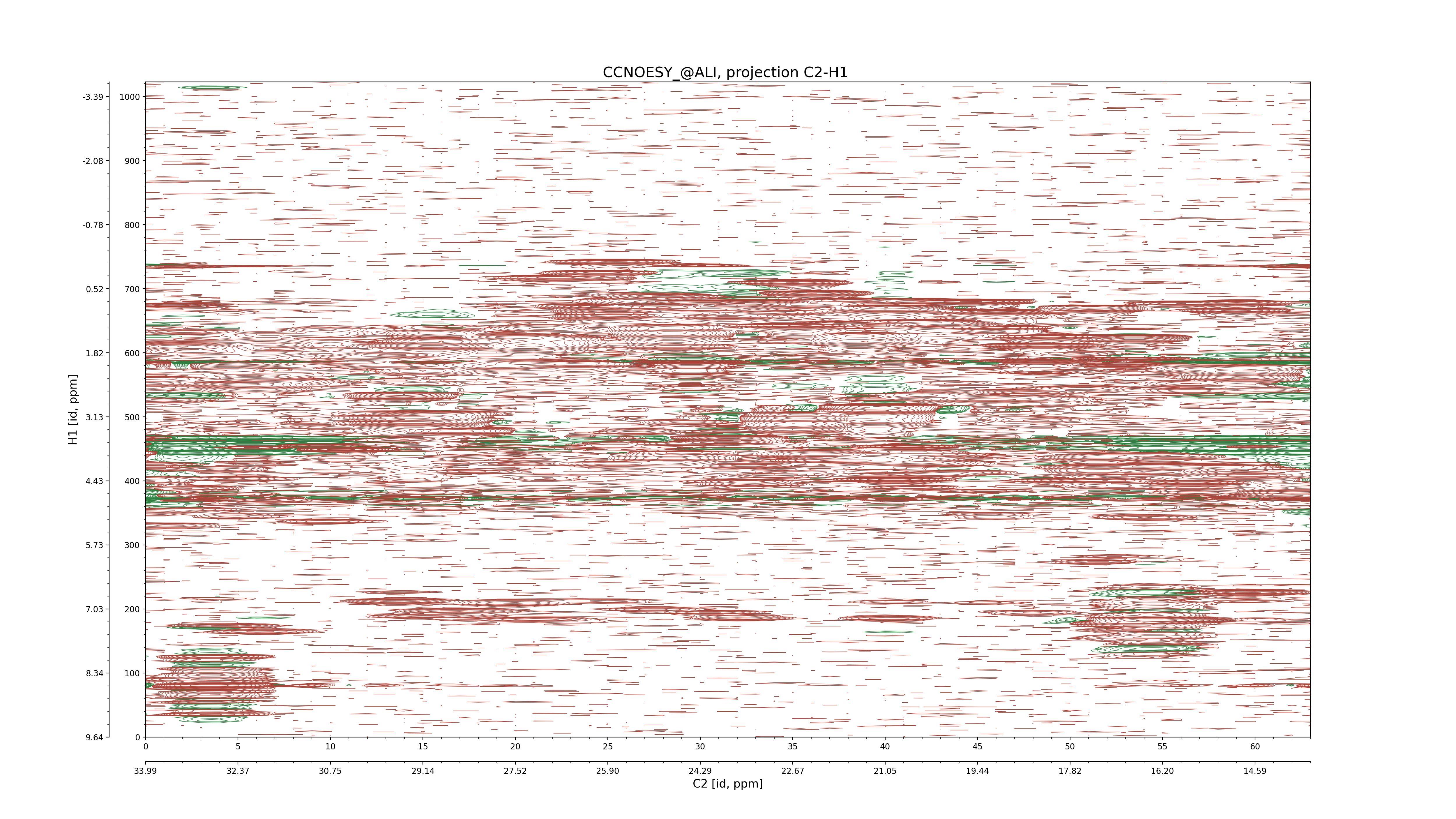{kind=link}
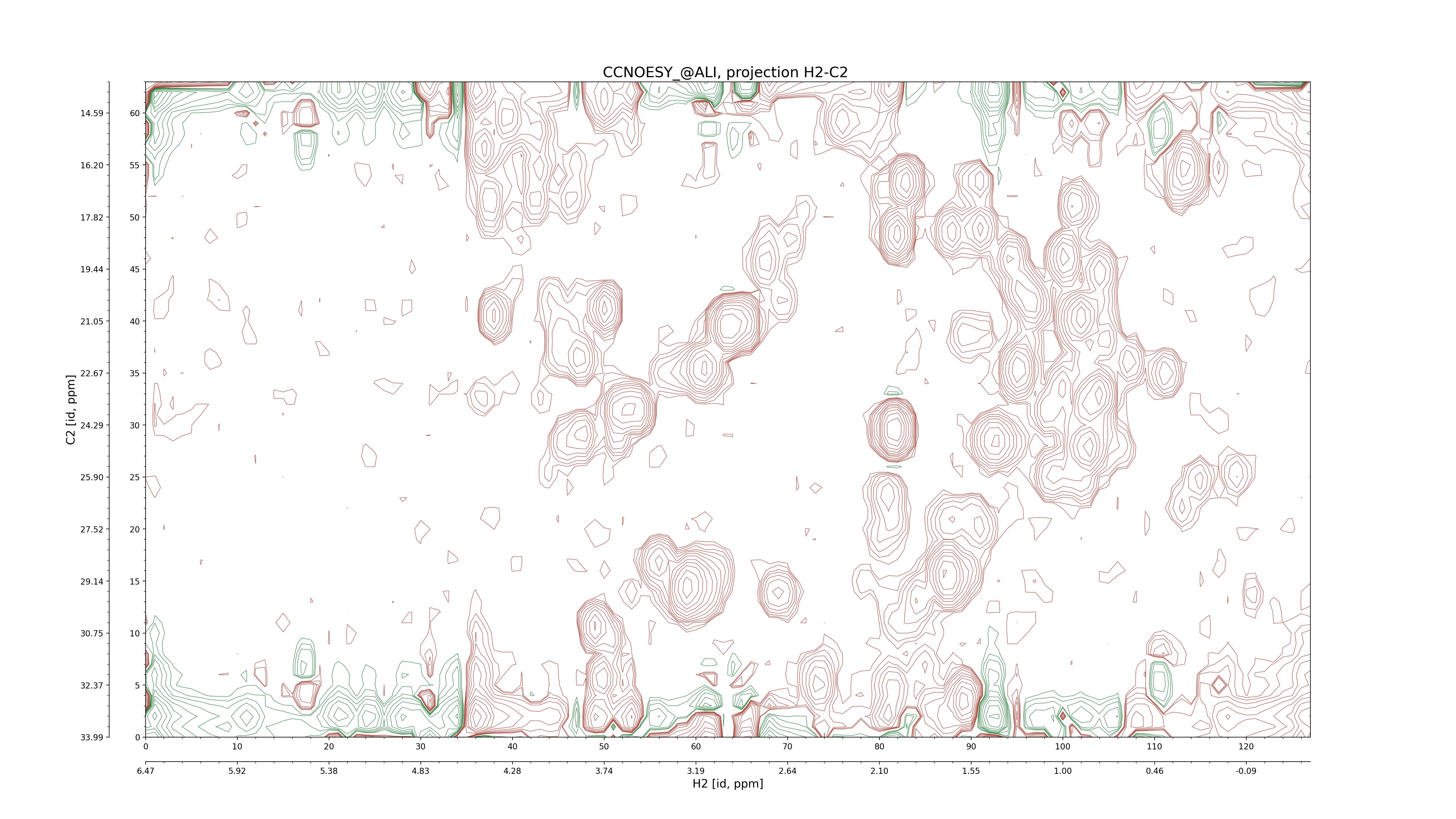{kind=link}
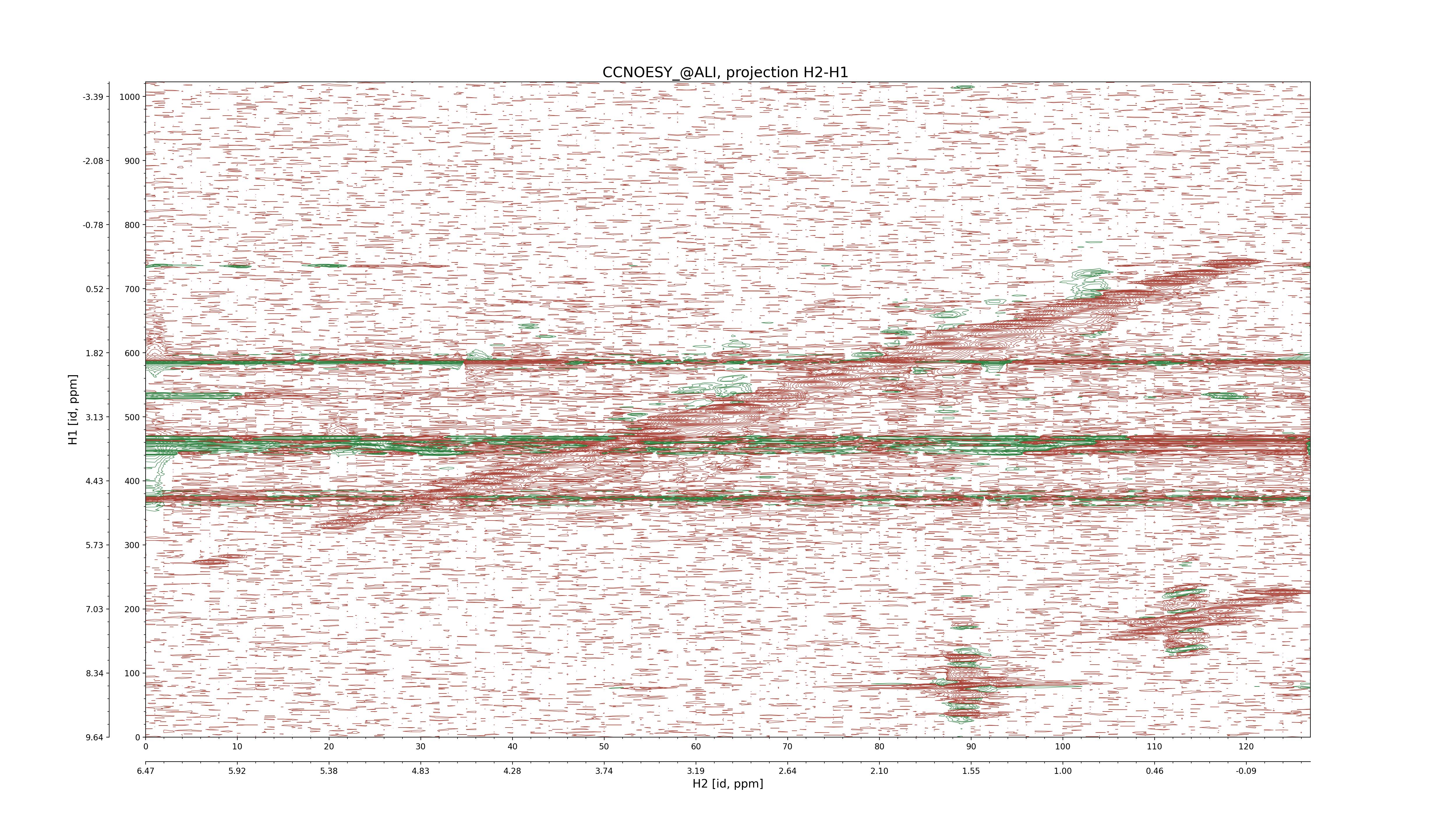{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
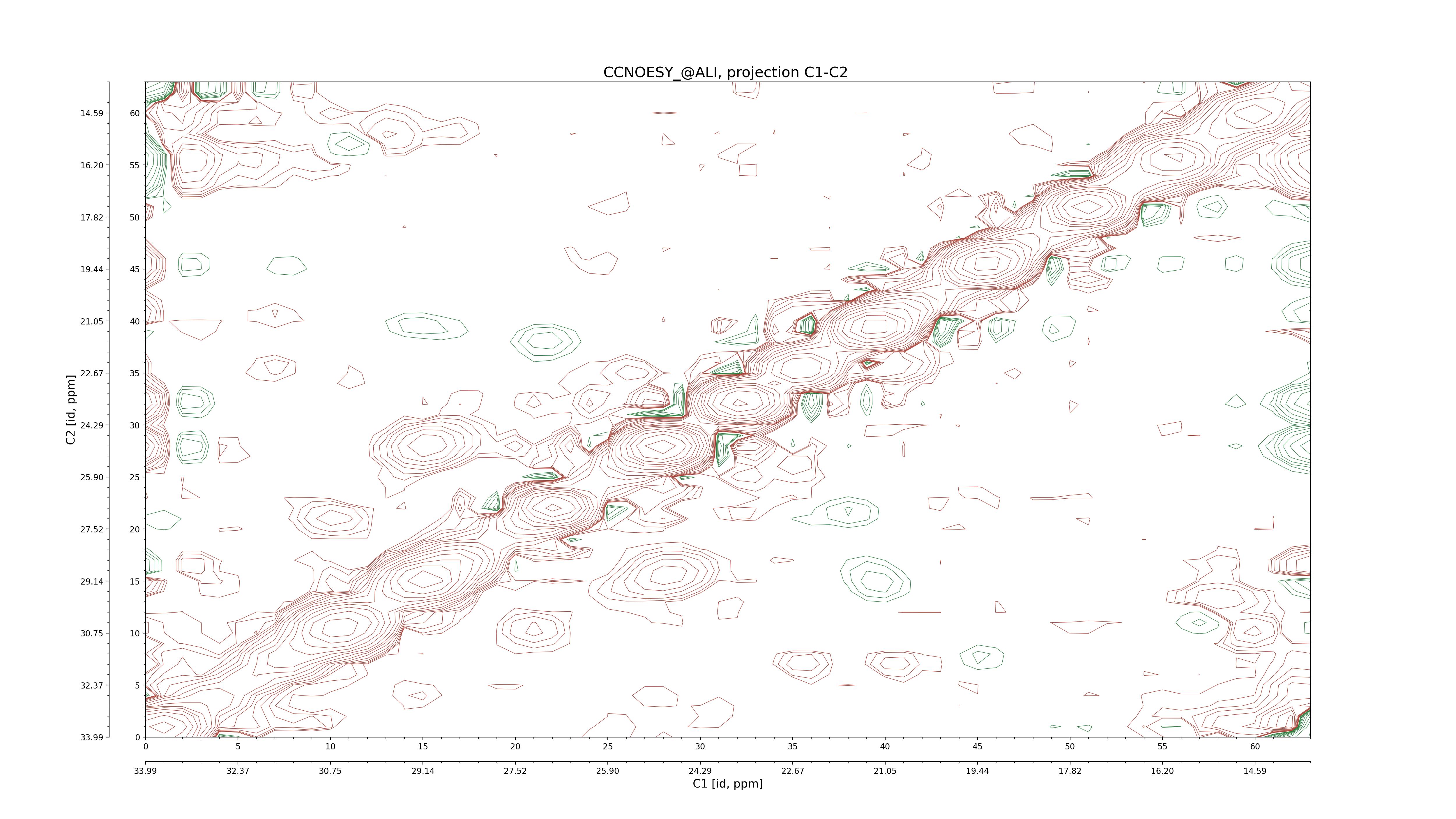{kind=link}
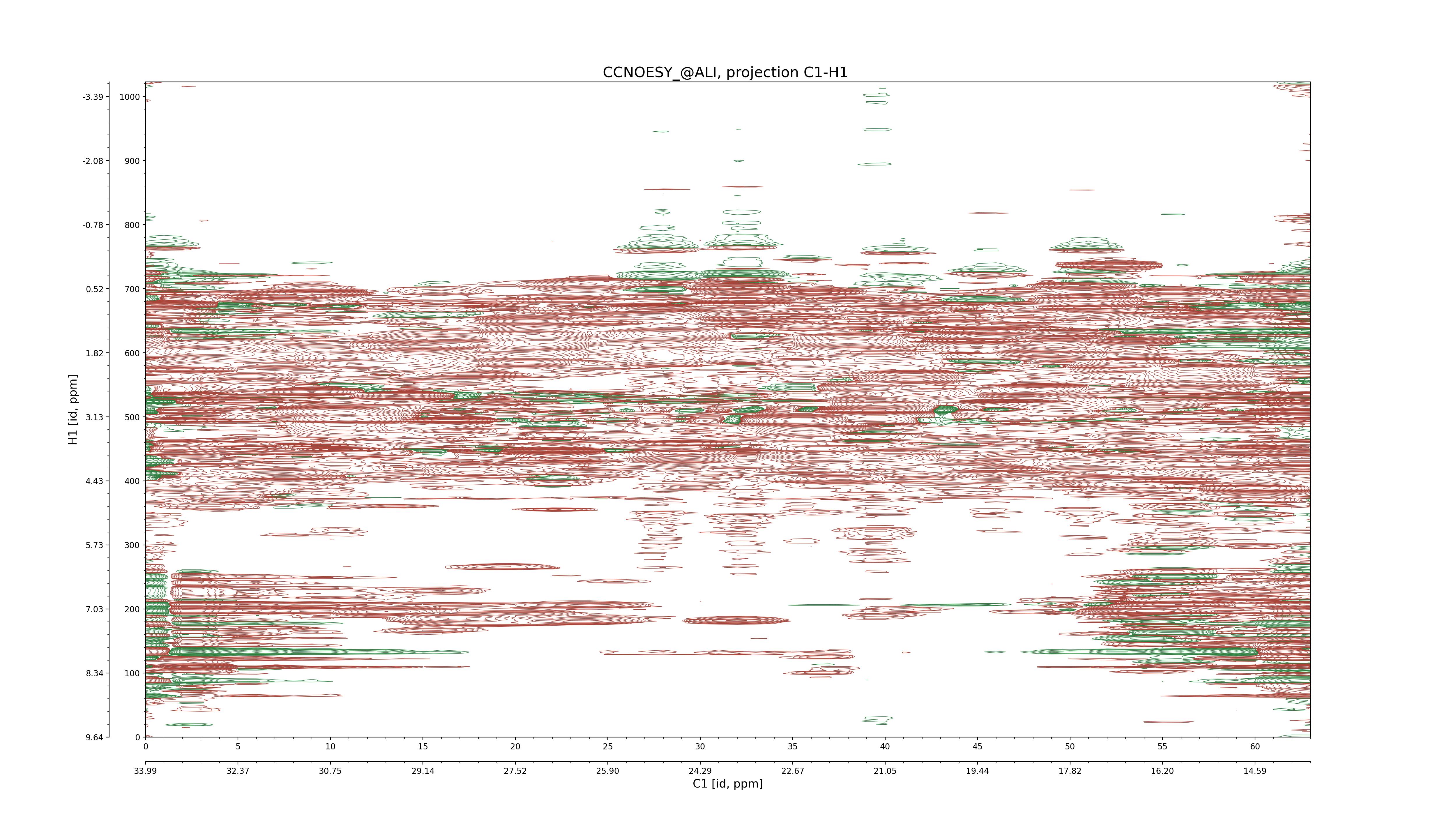{kind=link}
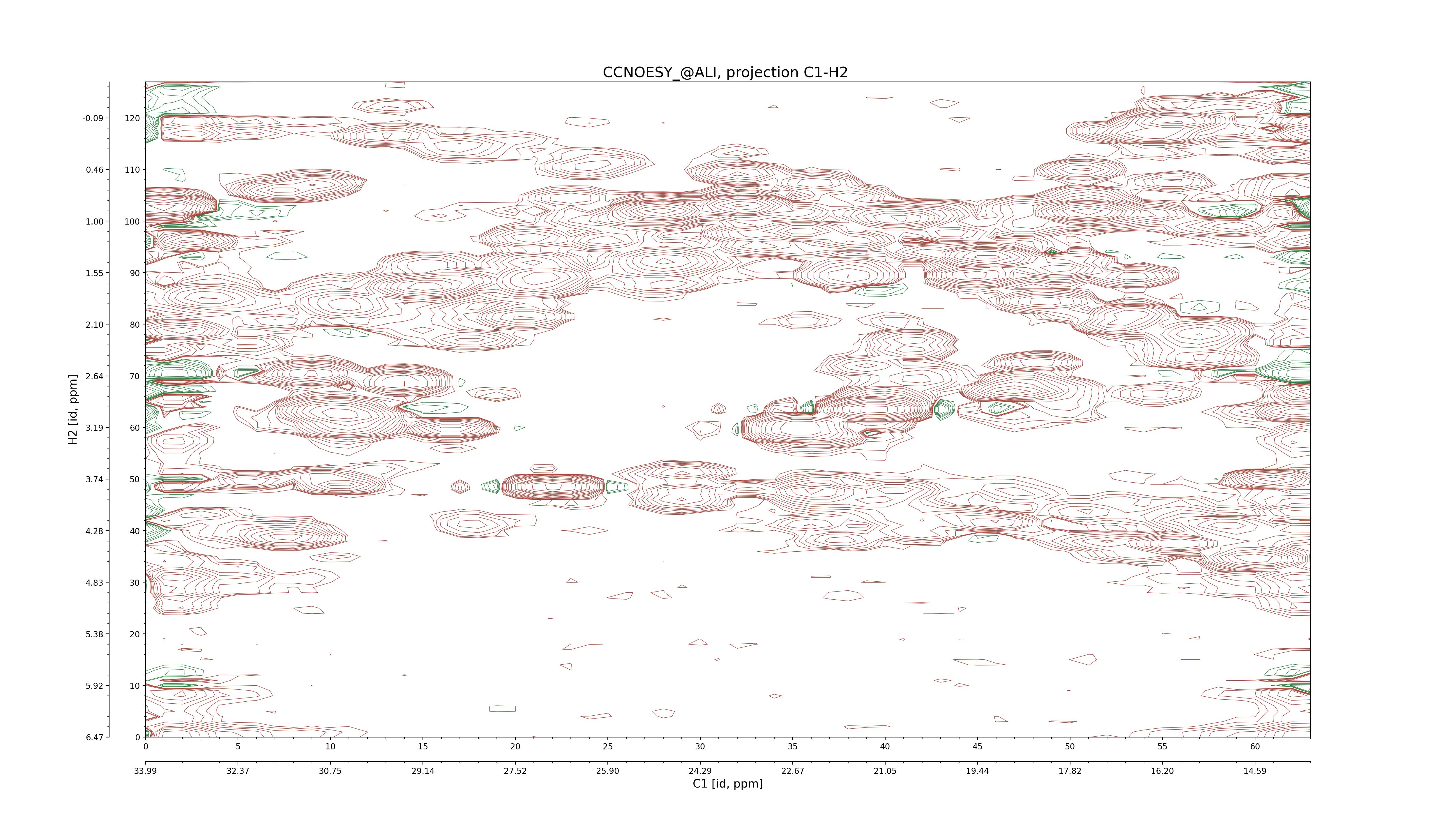{kind=link}
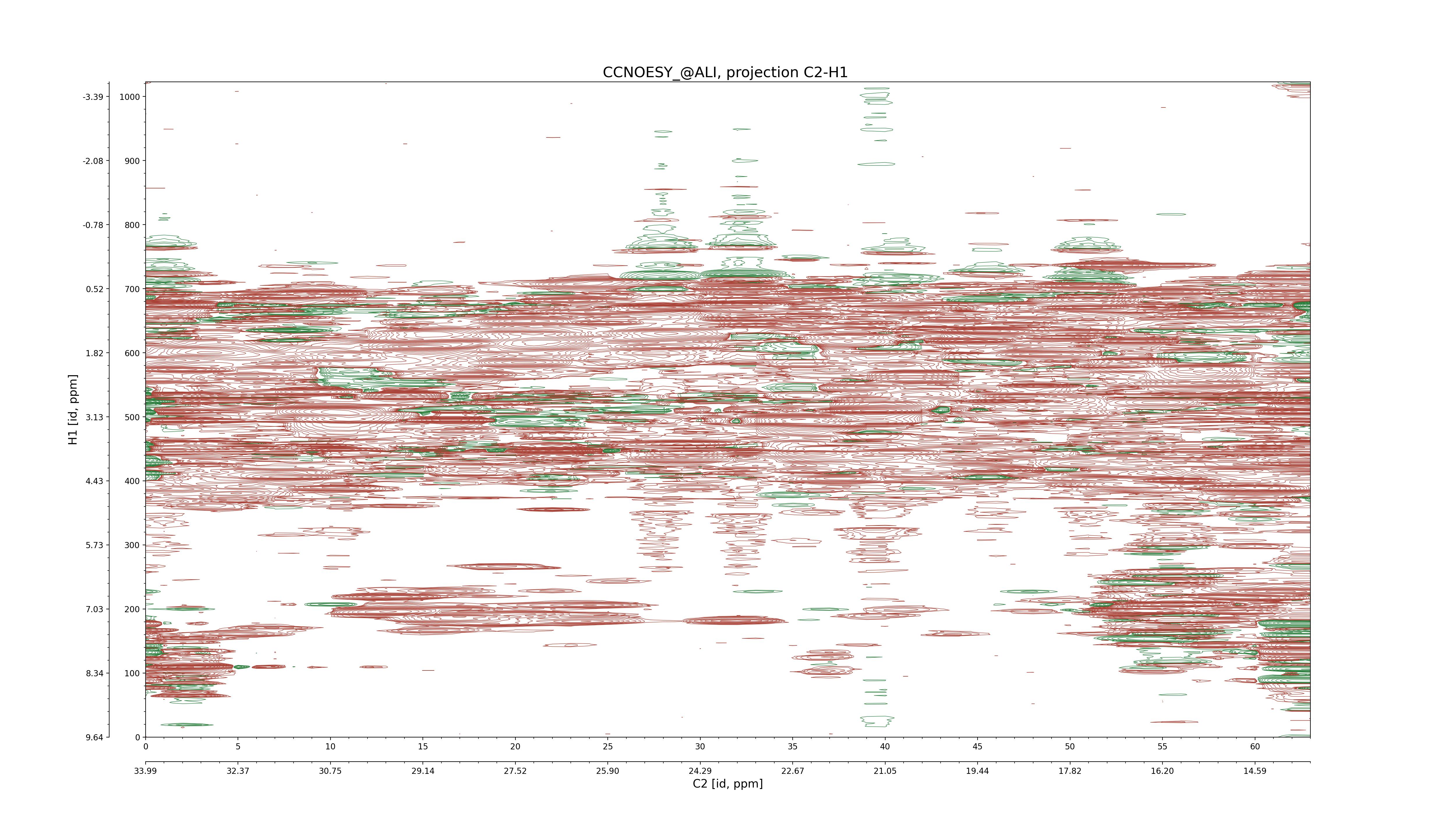{kind=link}
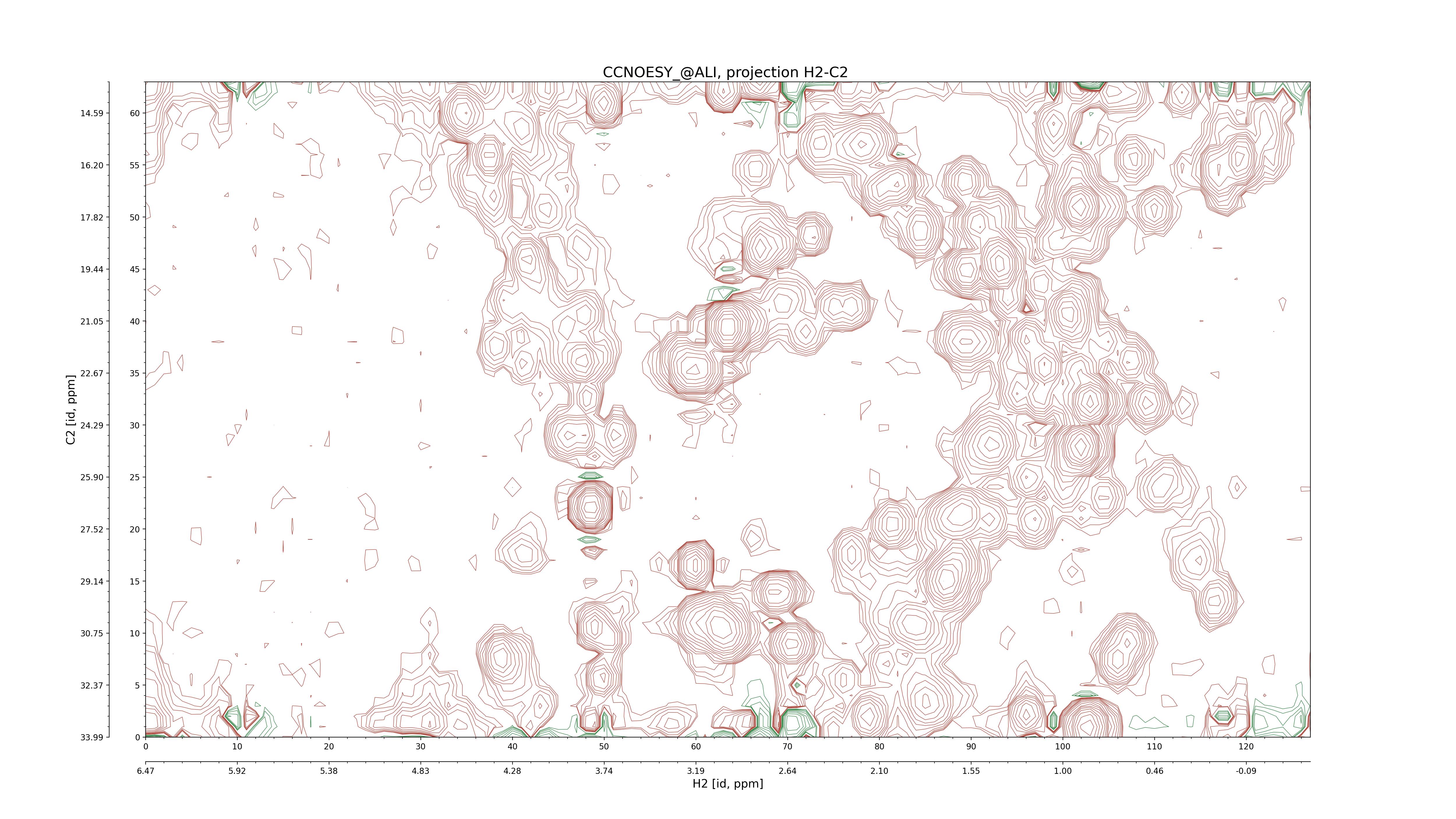{kind=link}
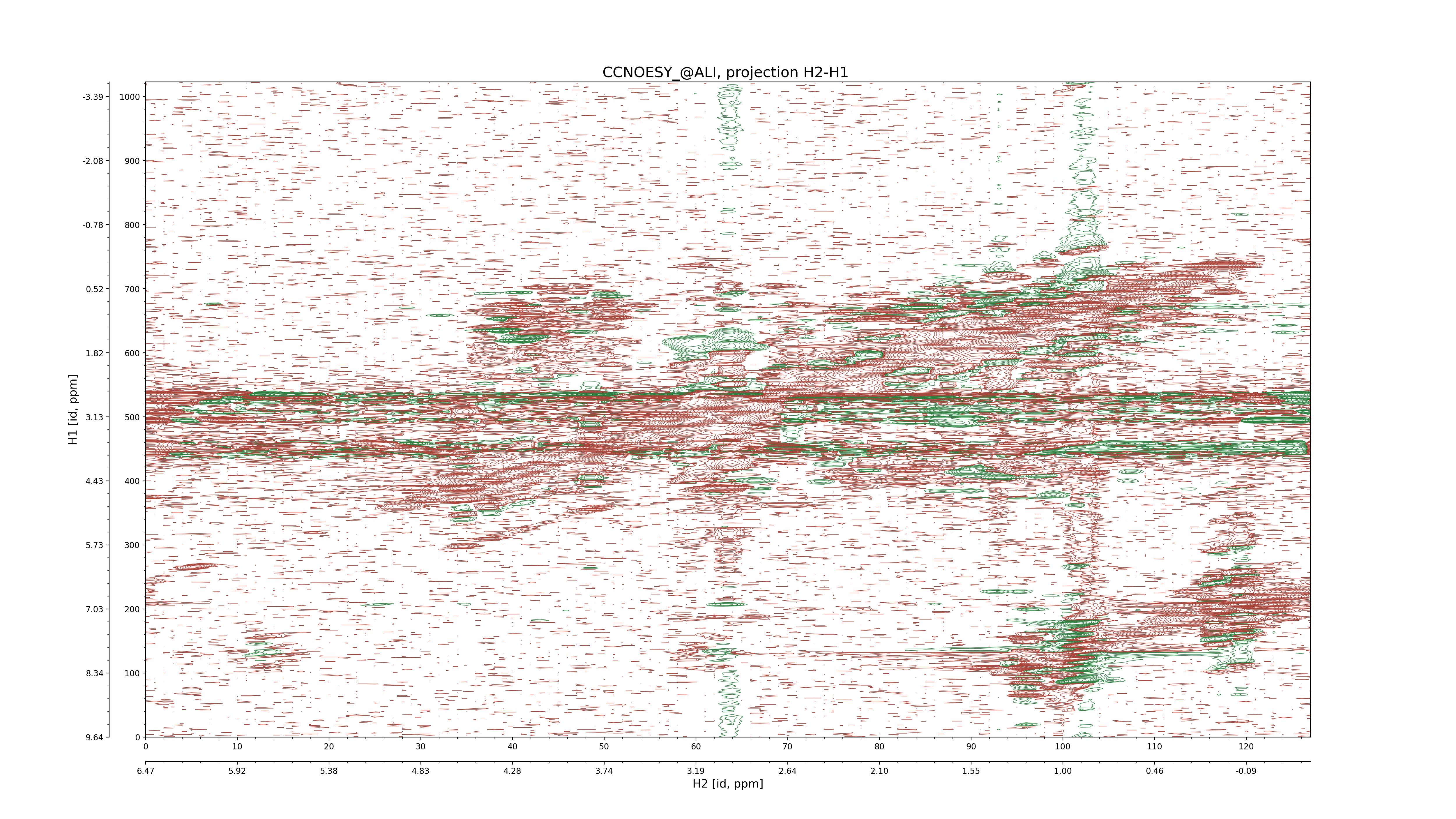{kind=link}
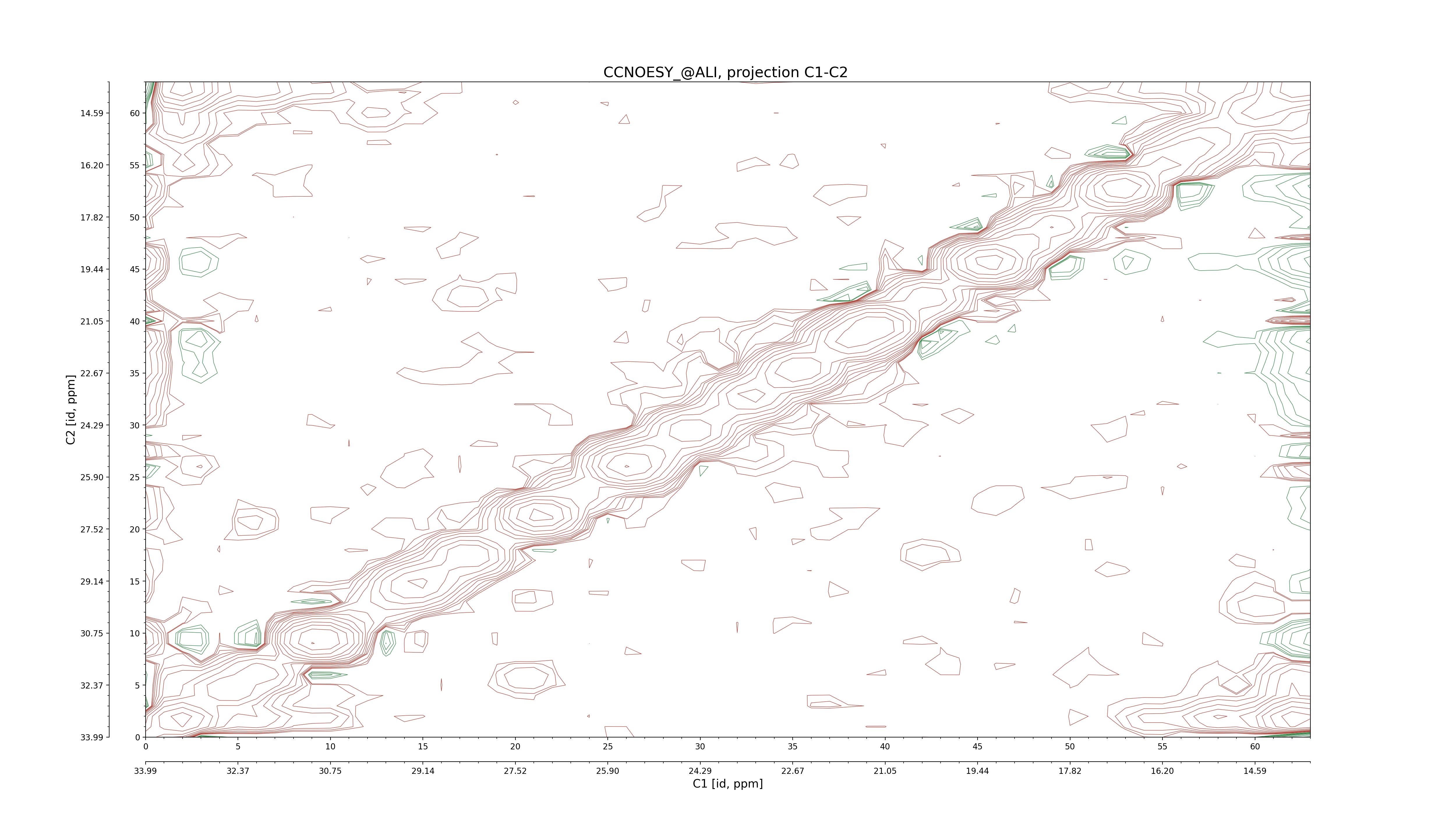{kind=link}
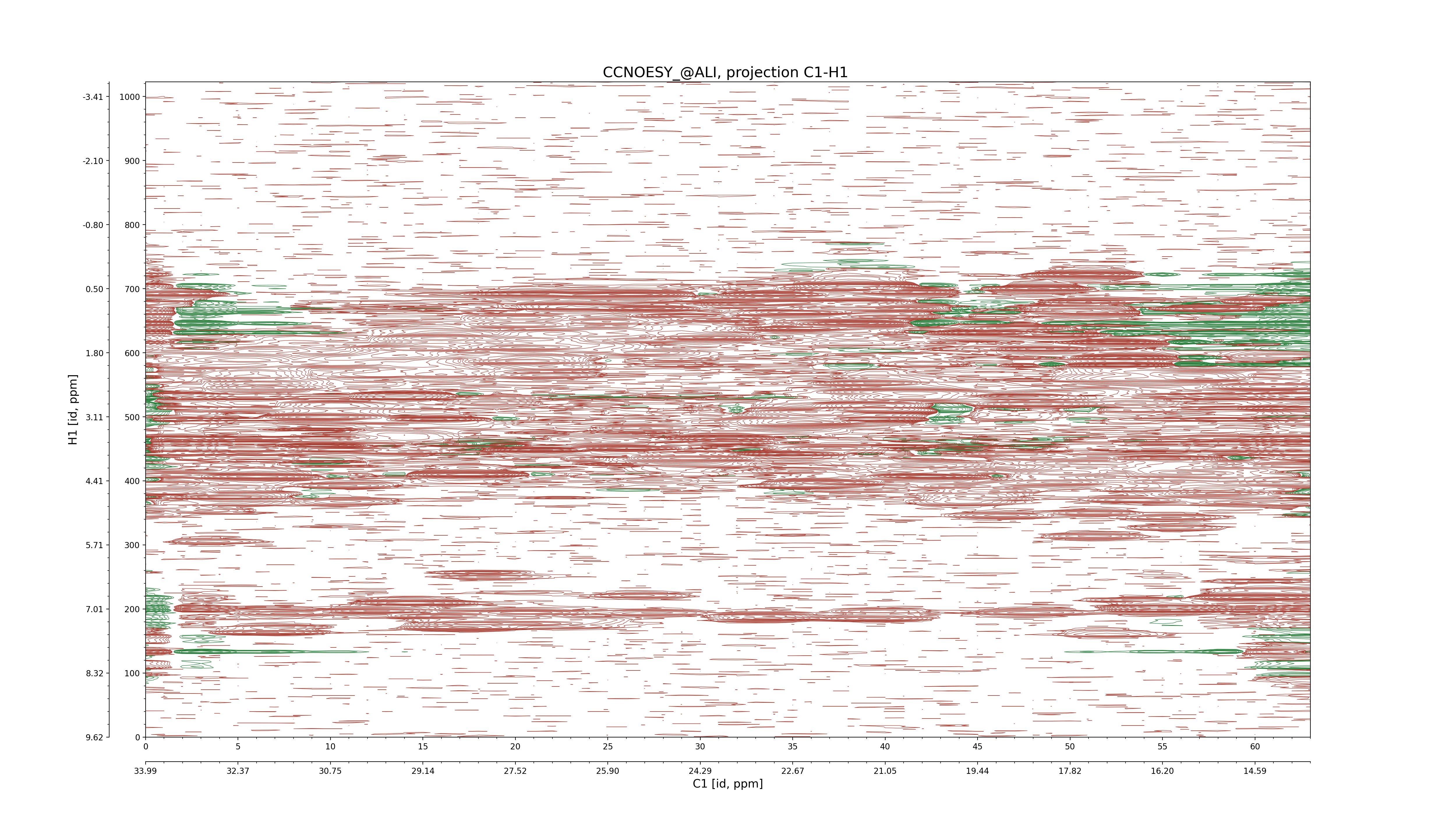{kind=link}
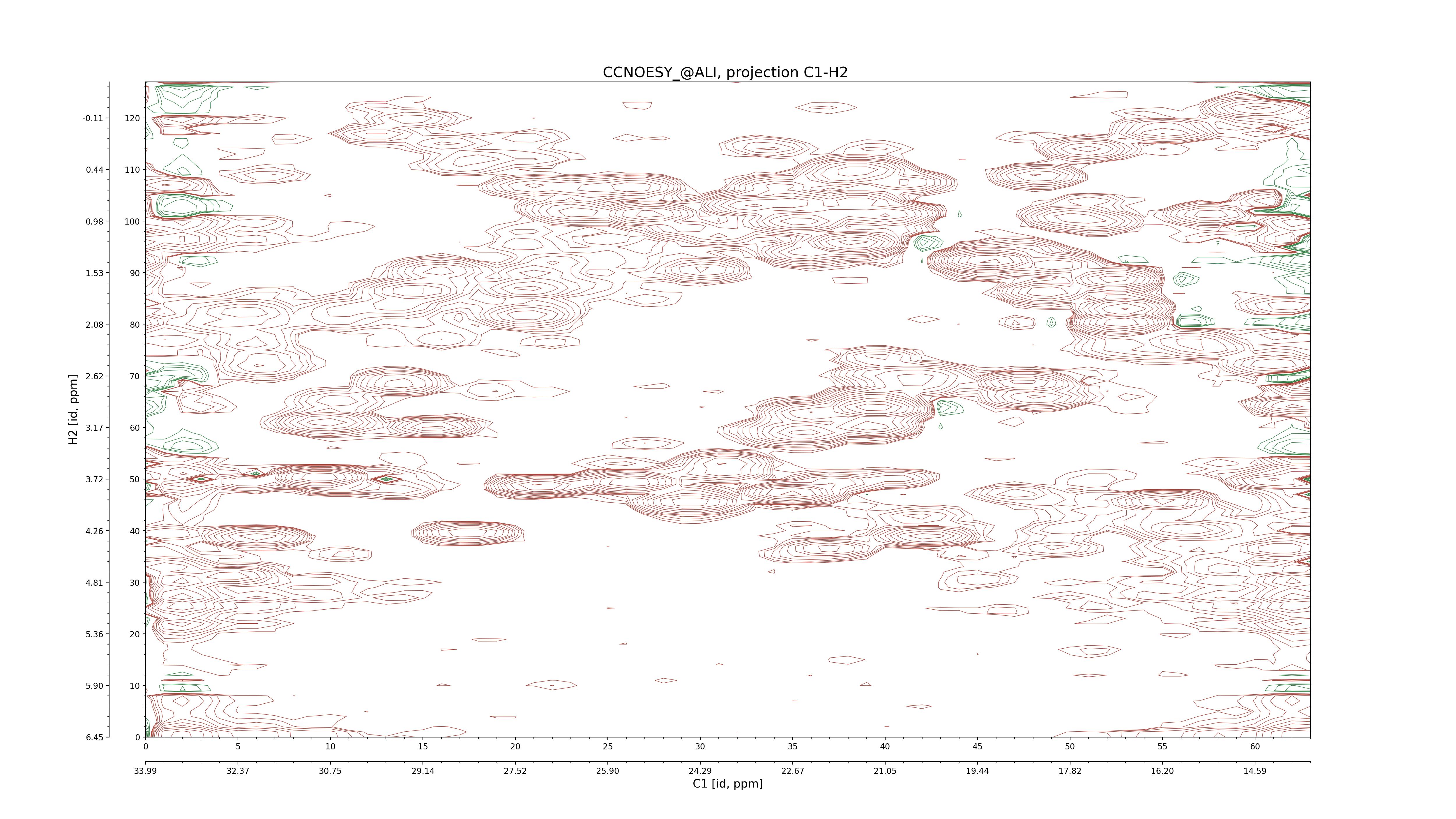{kind=link}
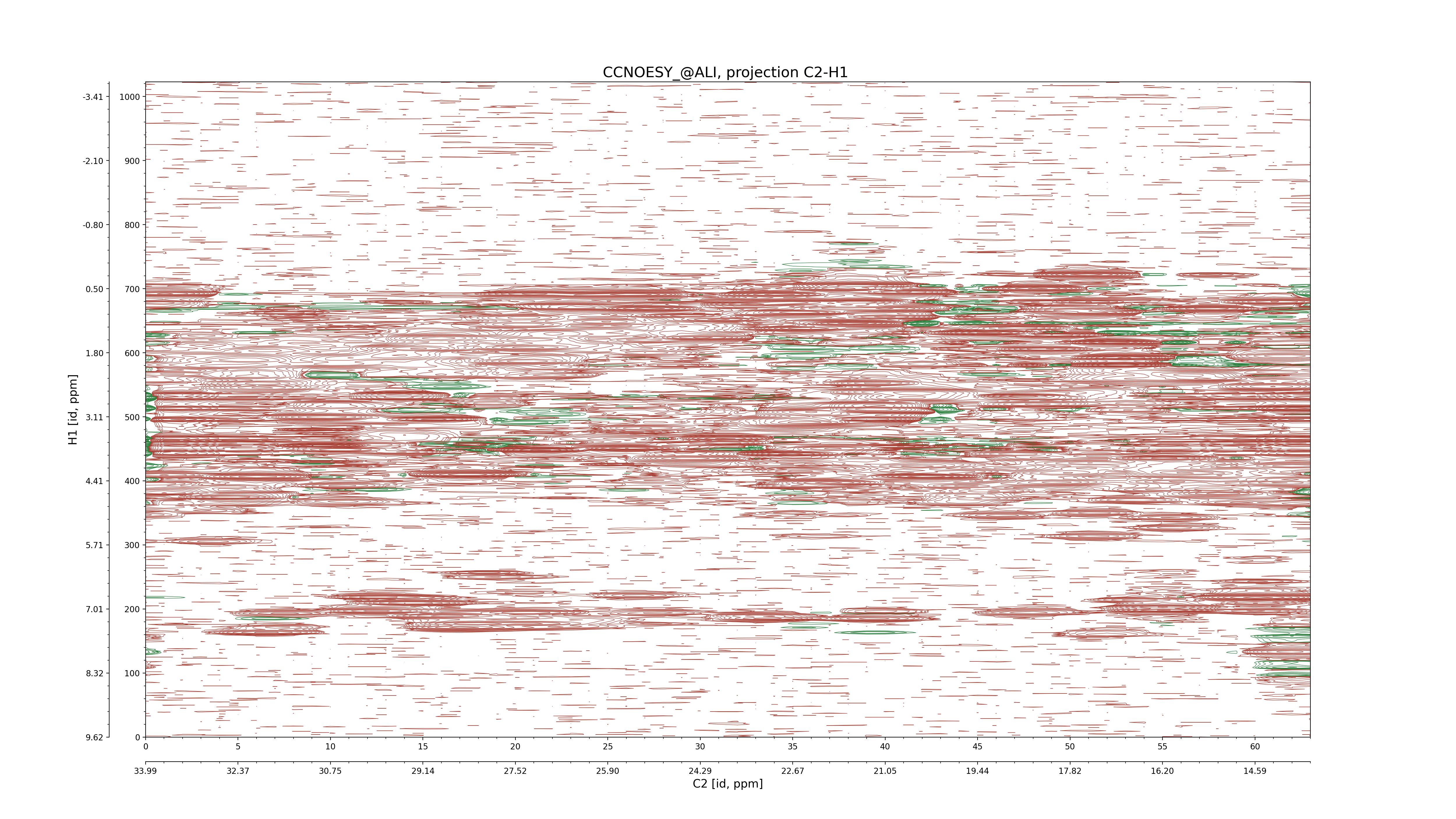{kind=link}
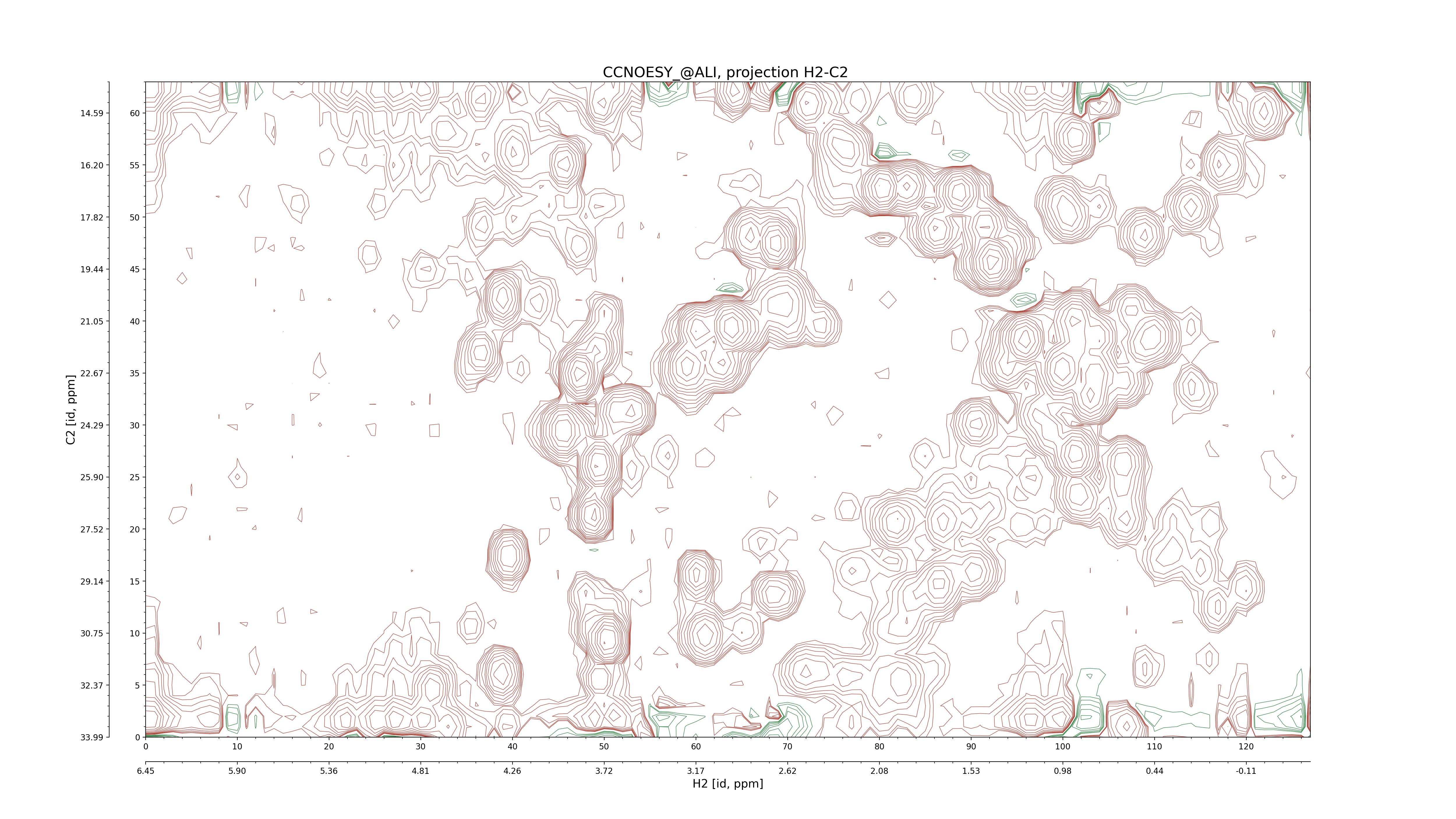{kind=link}
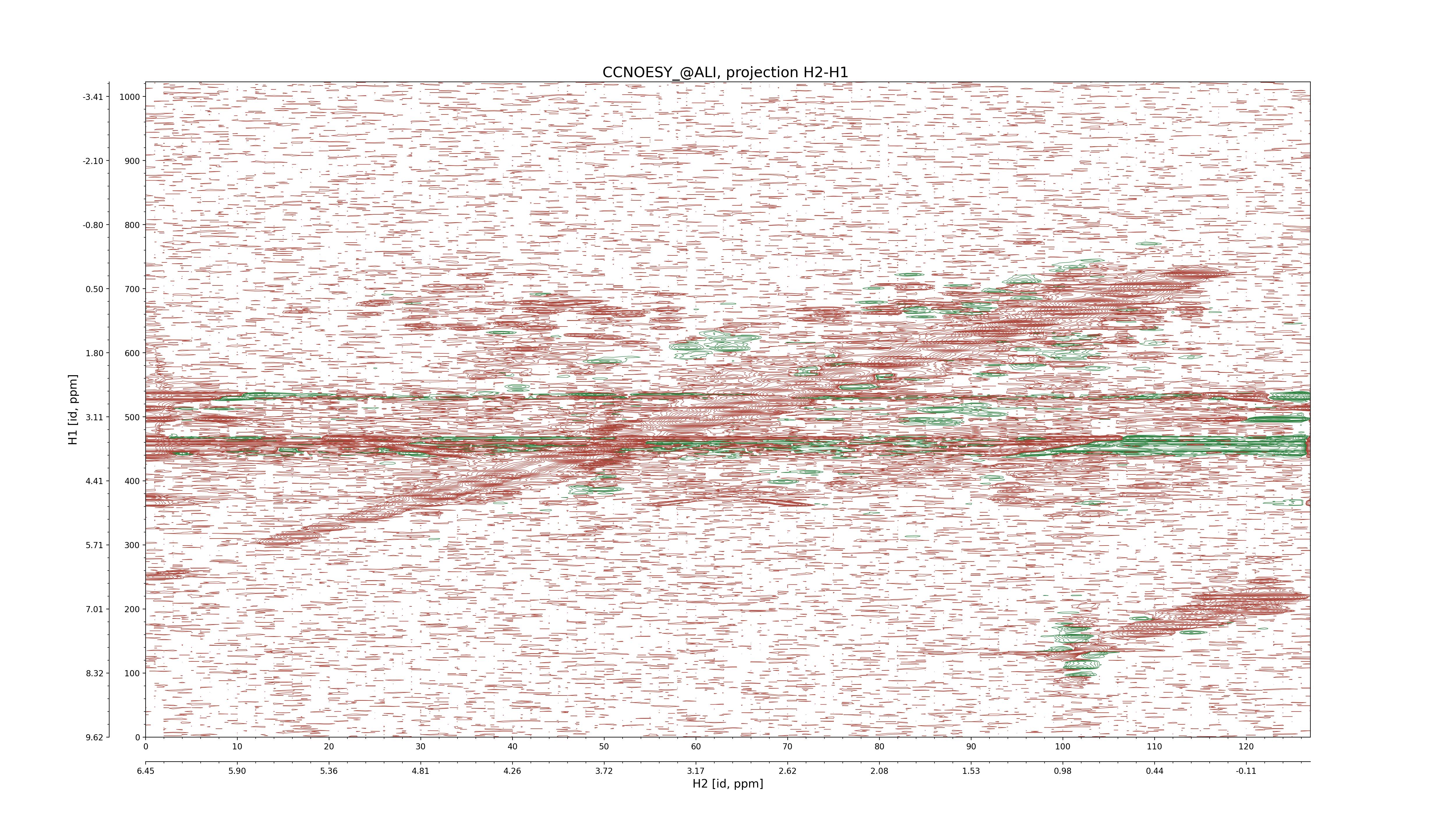{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
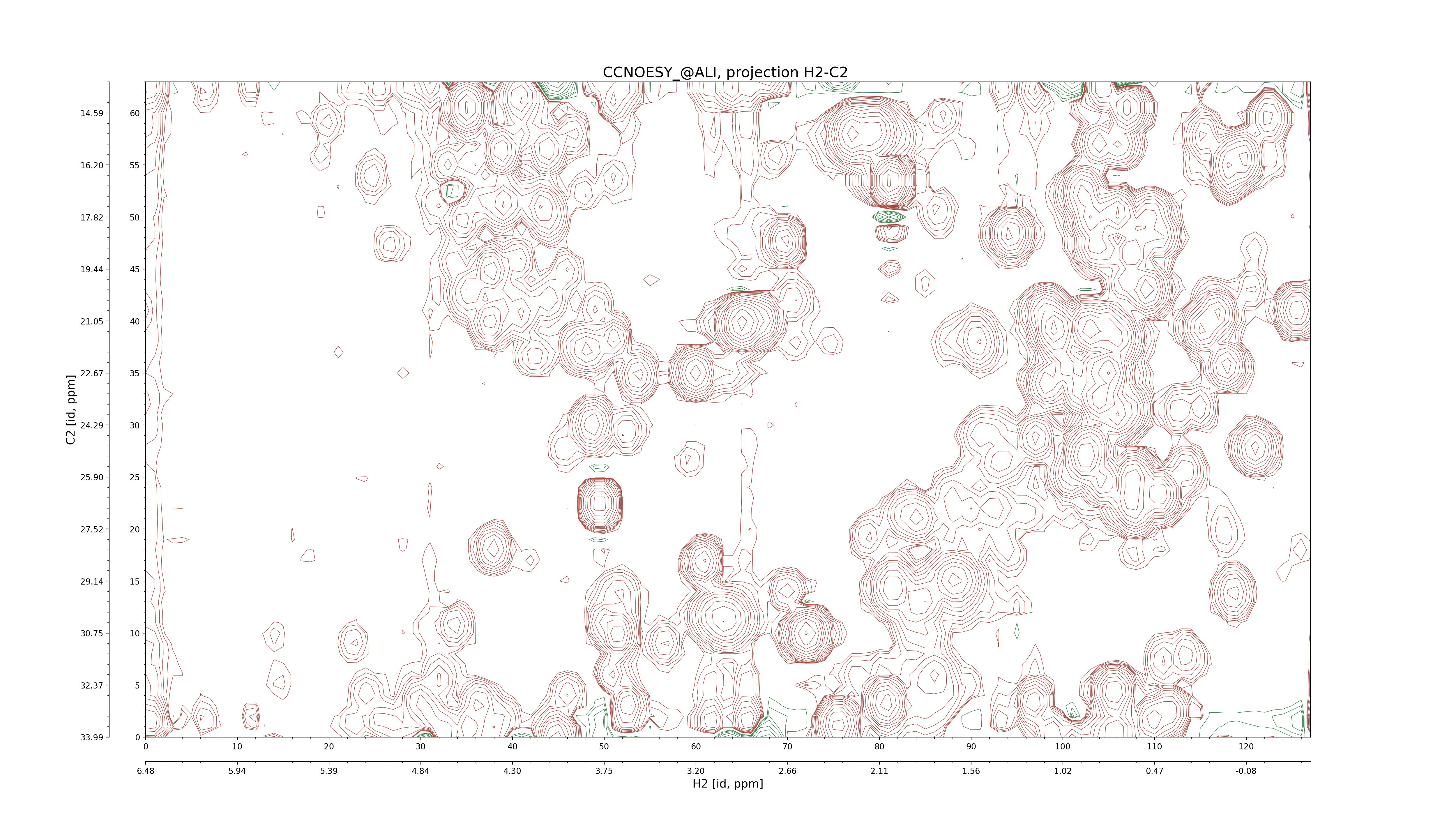{kind=link}
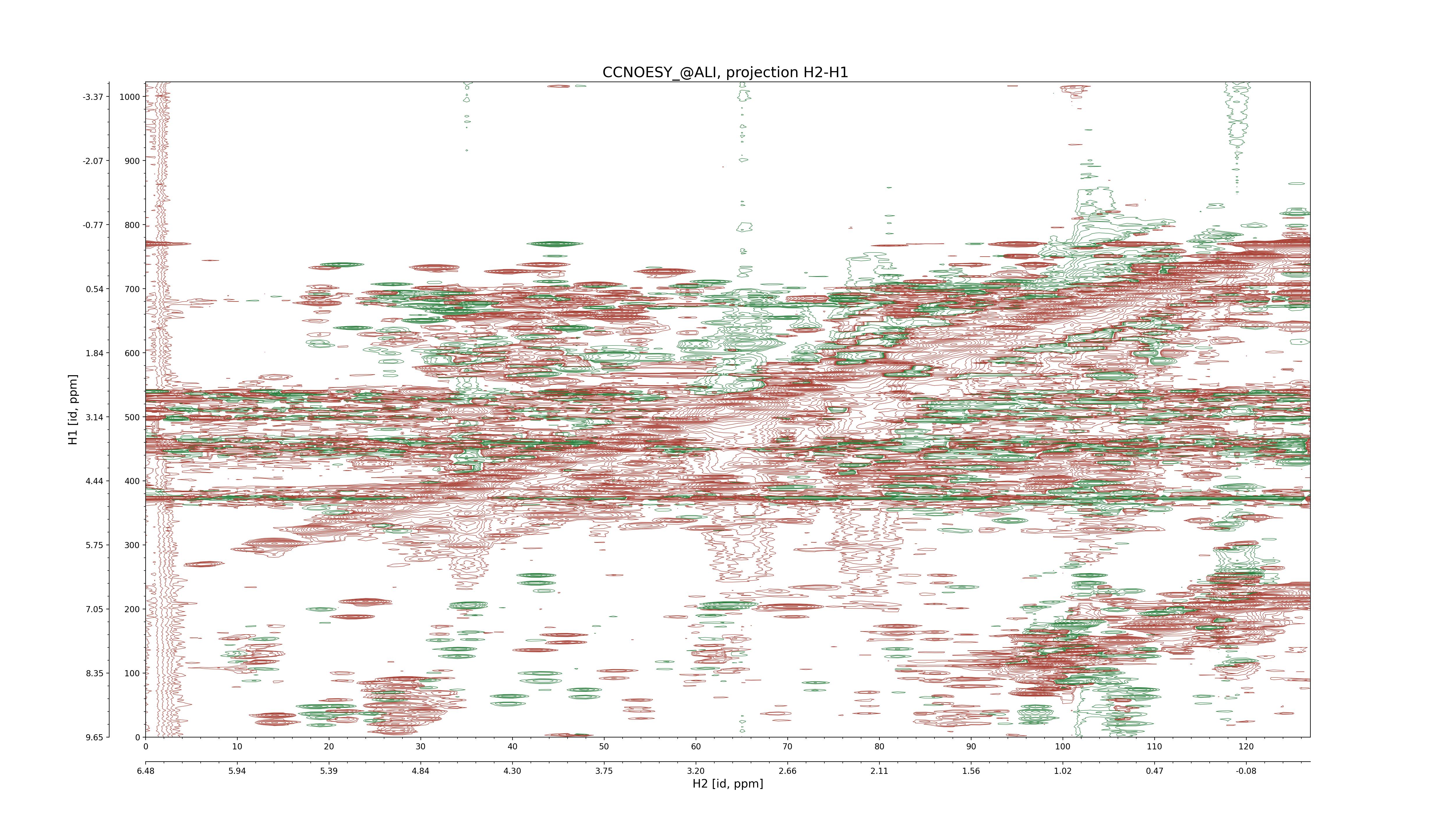{kind=link}
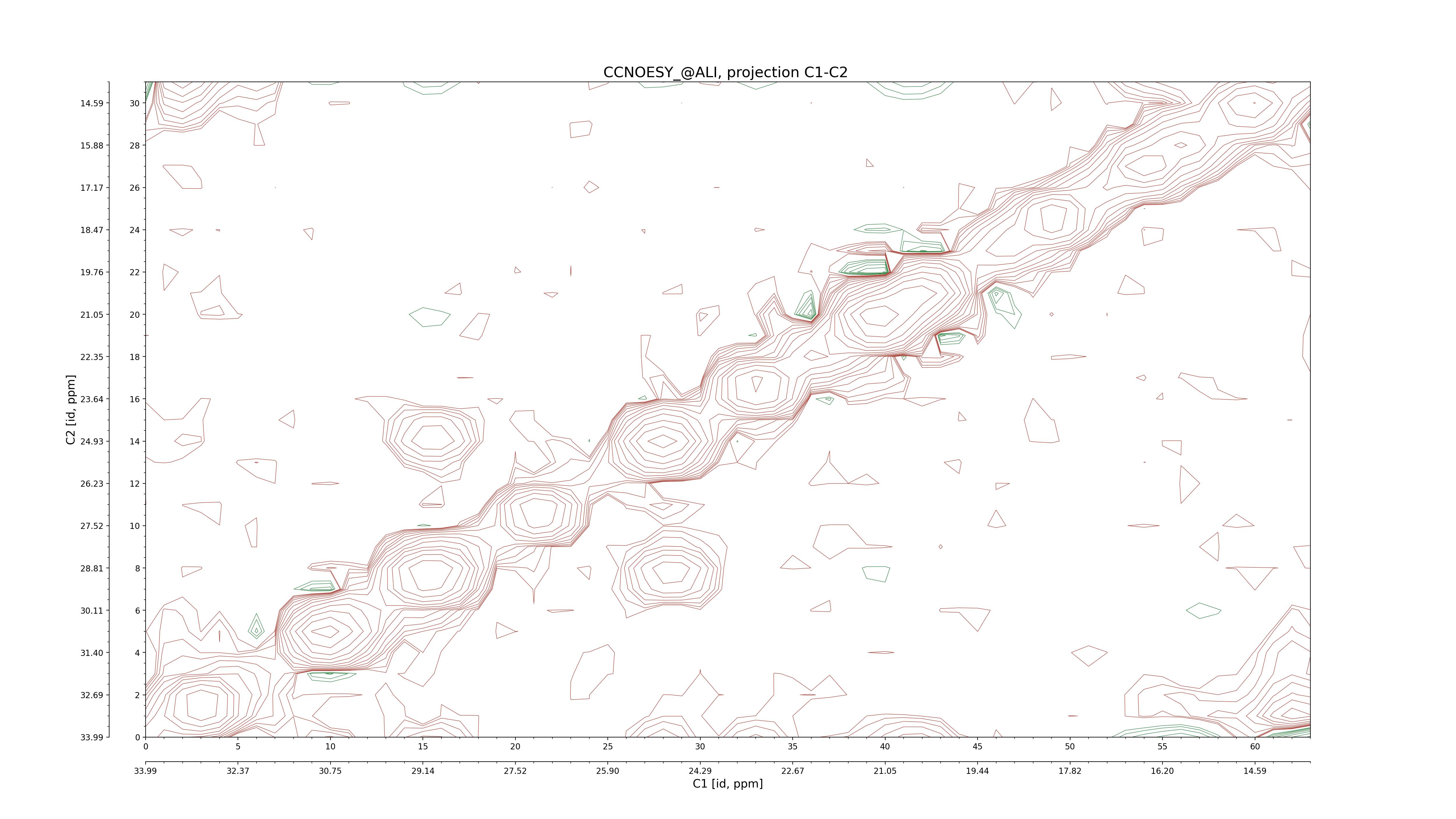{kind=link}
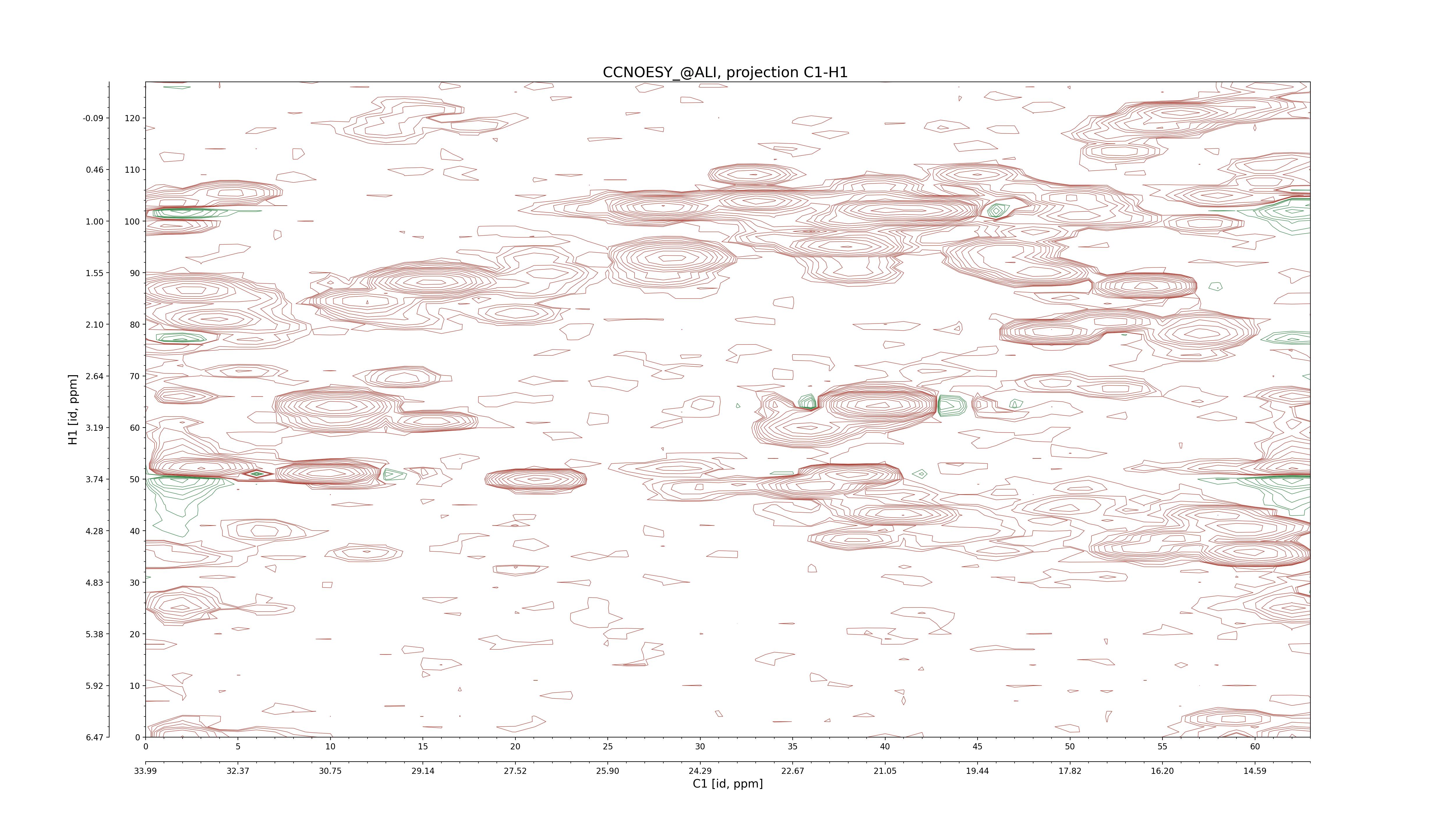{kind=link}
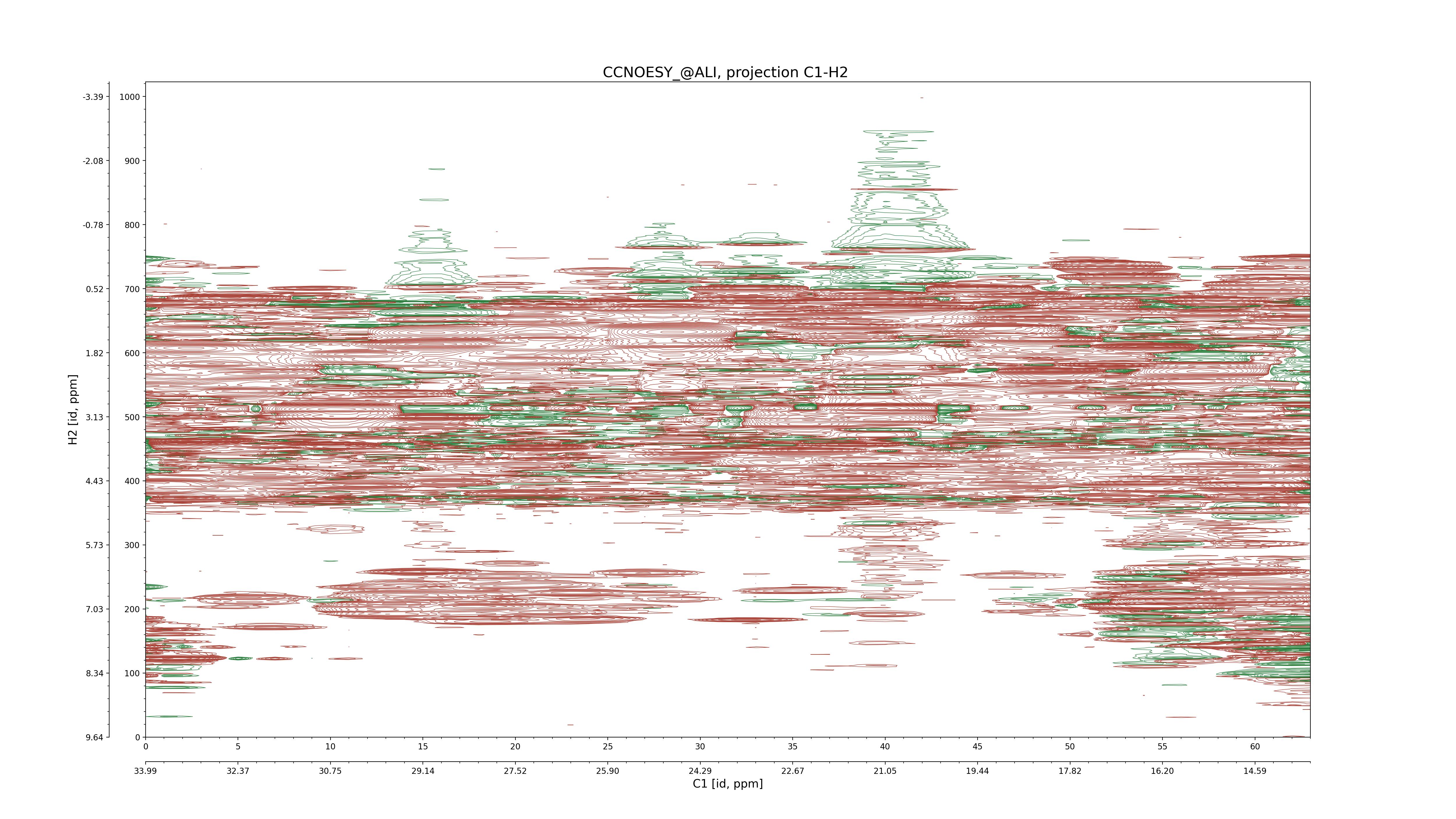{kind=link}
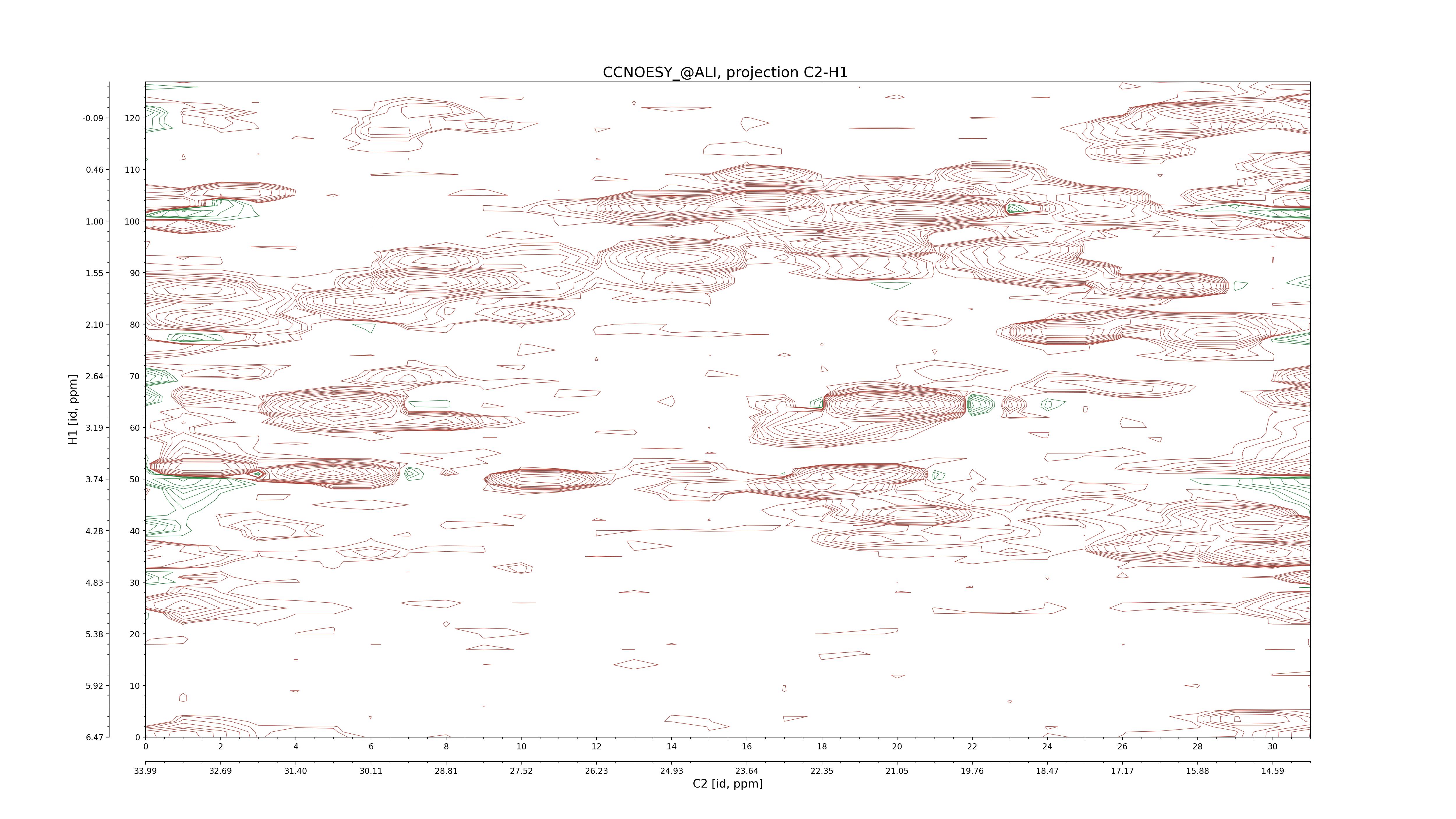{kind=link}
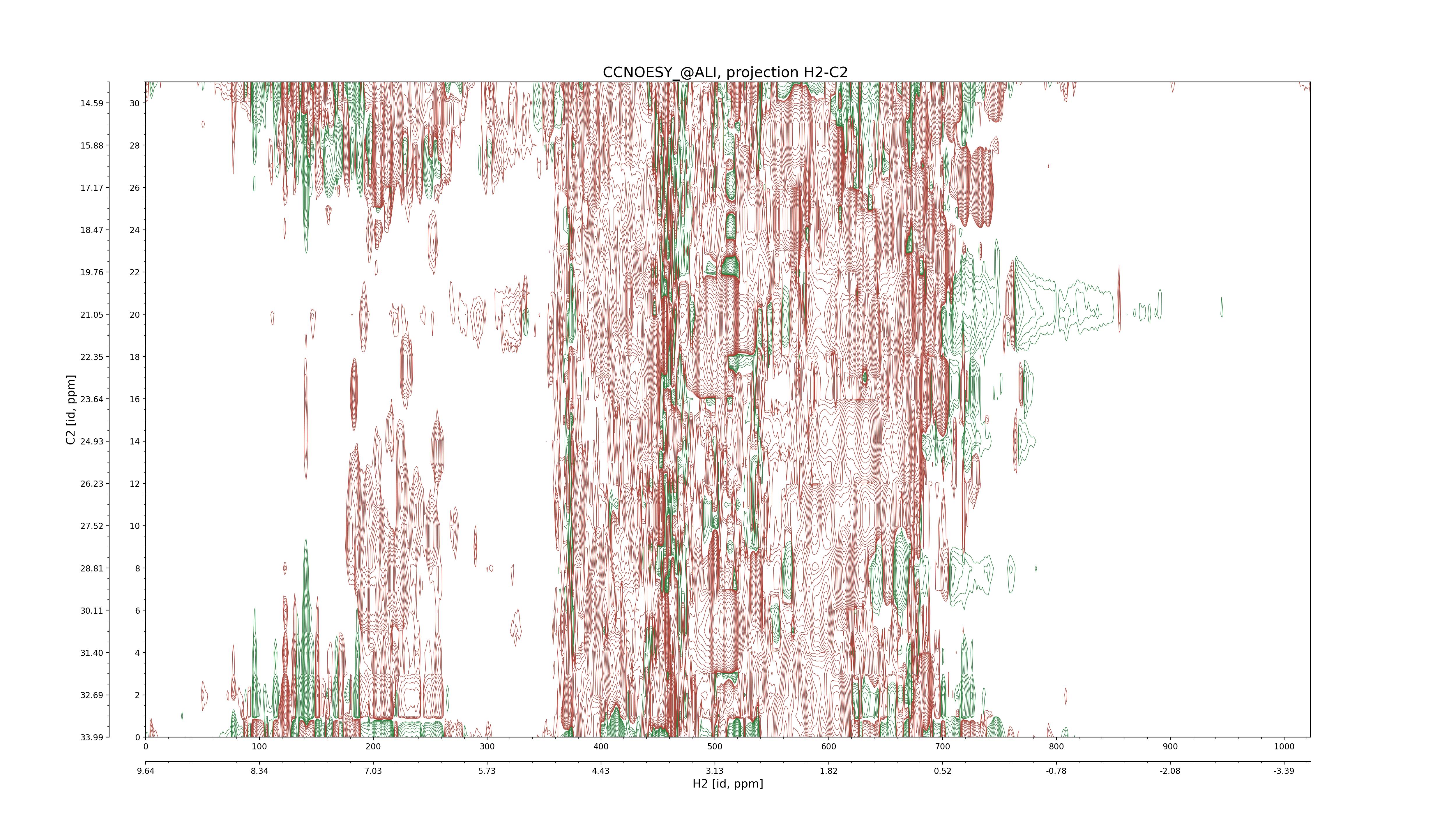{kind=link}
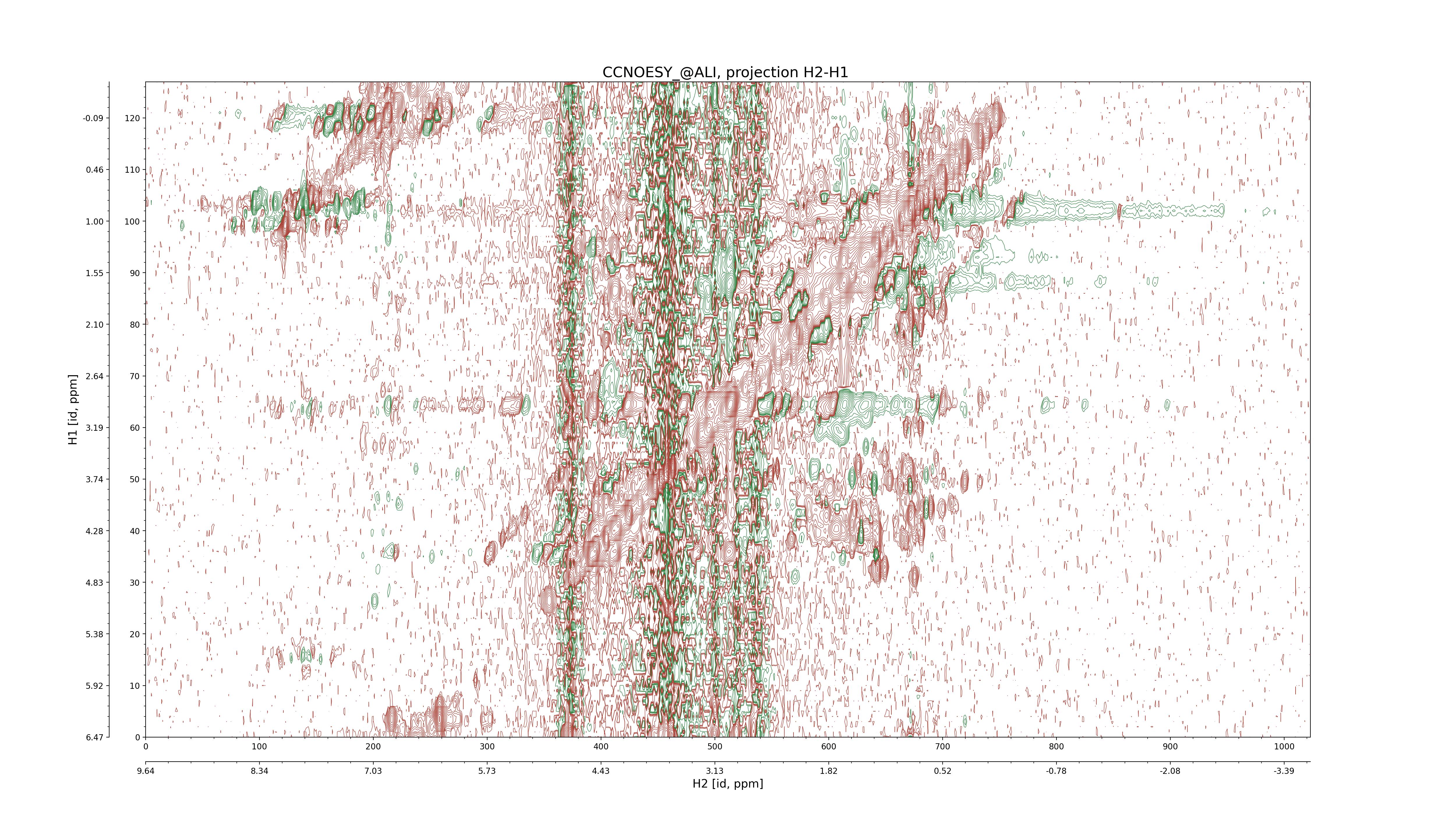{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
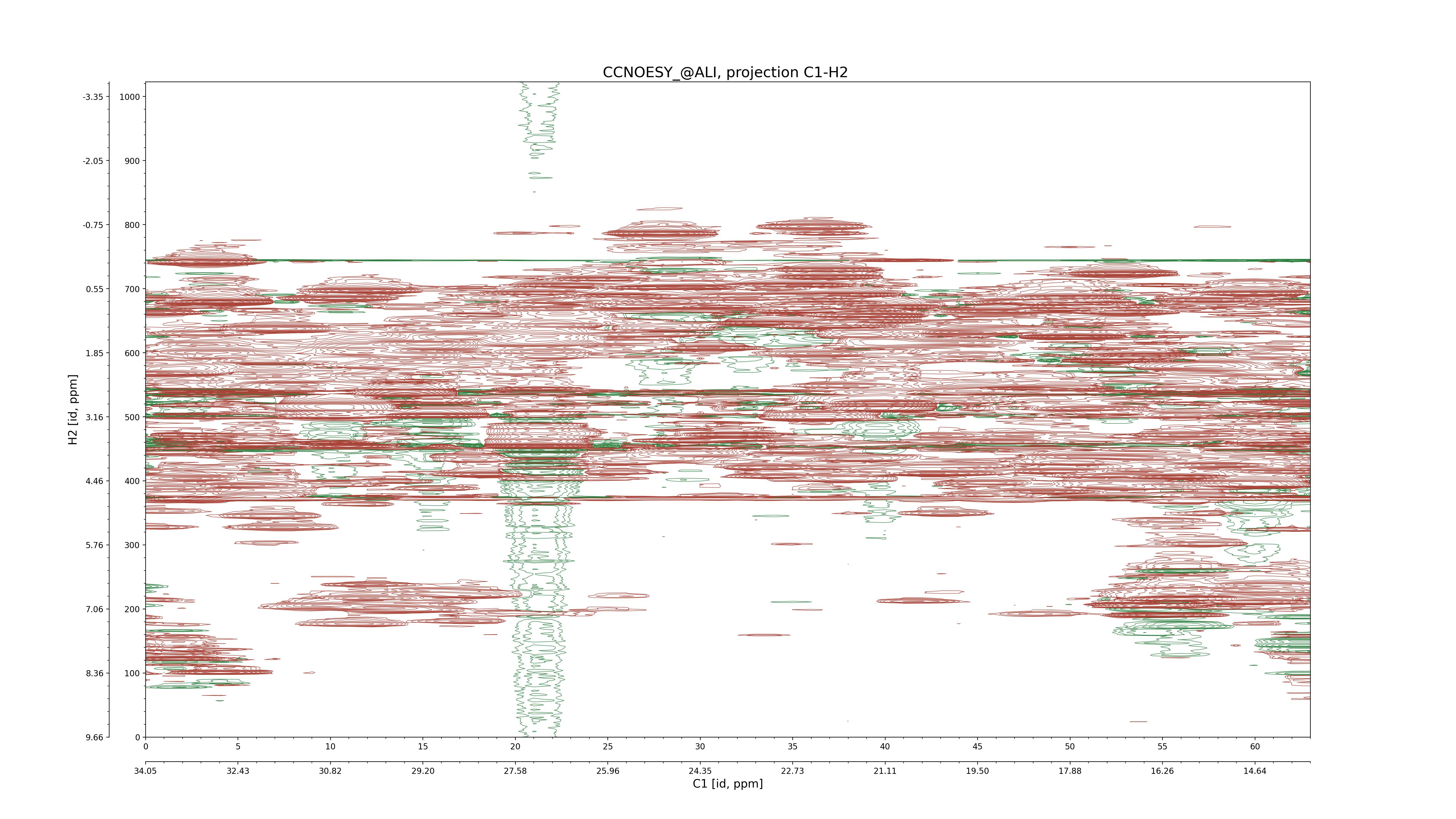{kind=link}
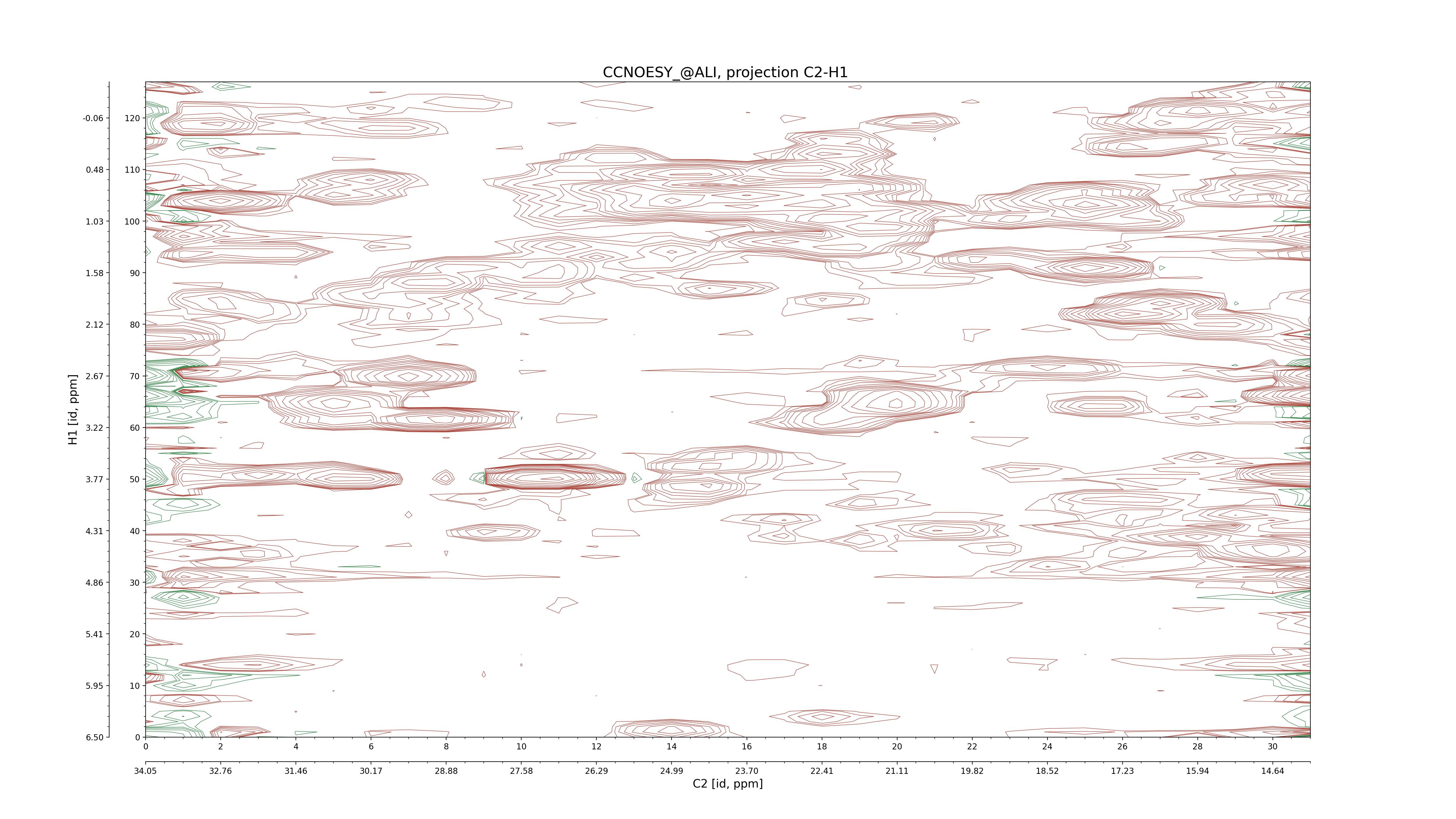{kind=link}
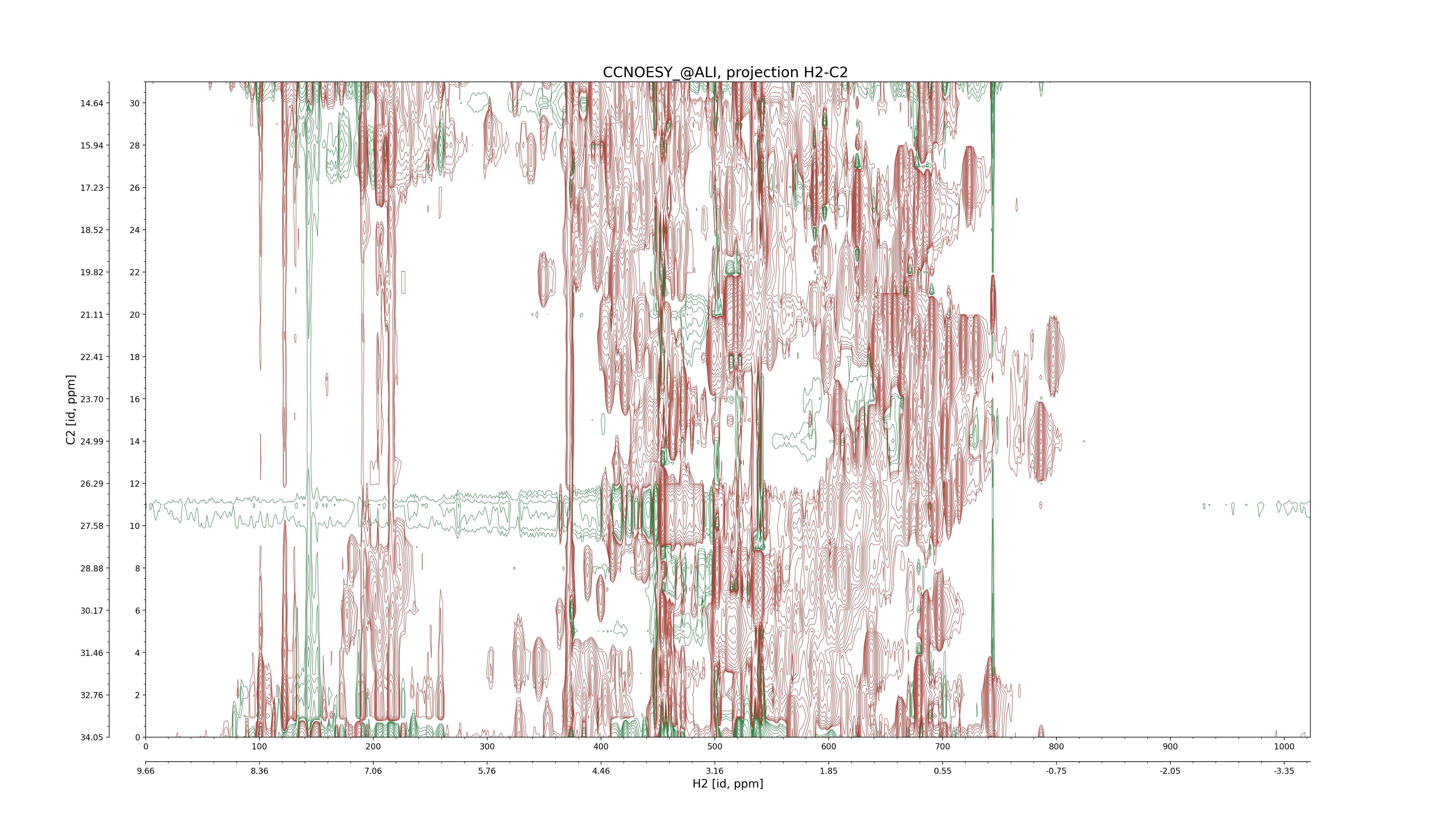{kind=link}
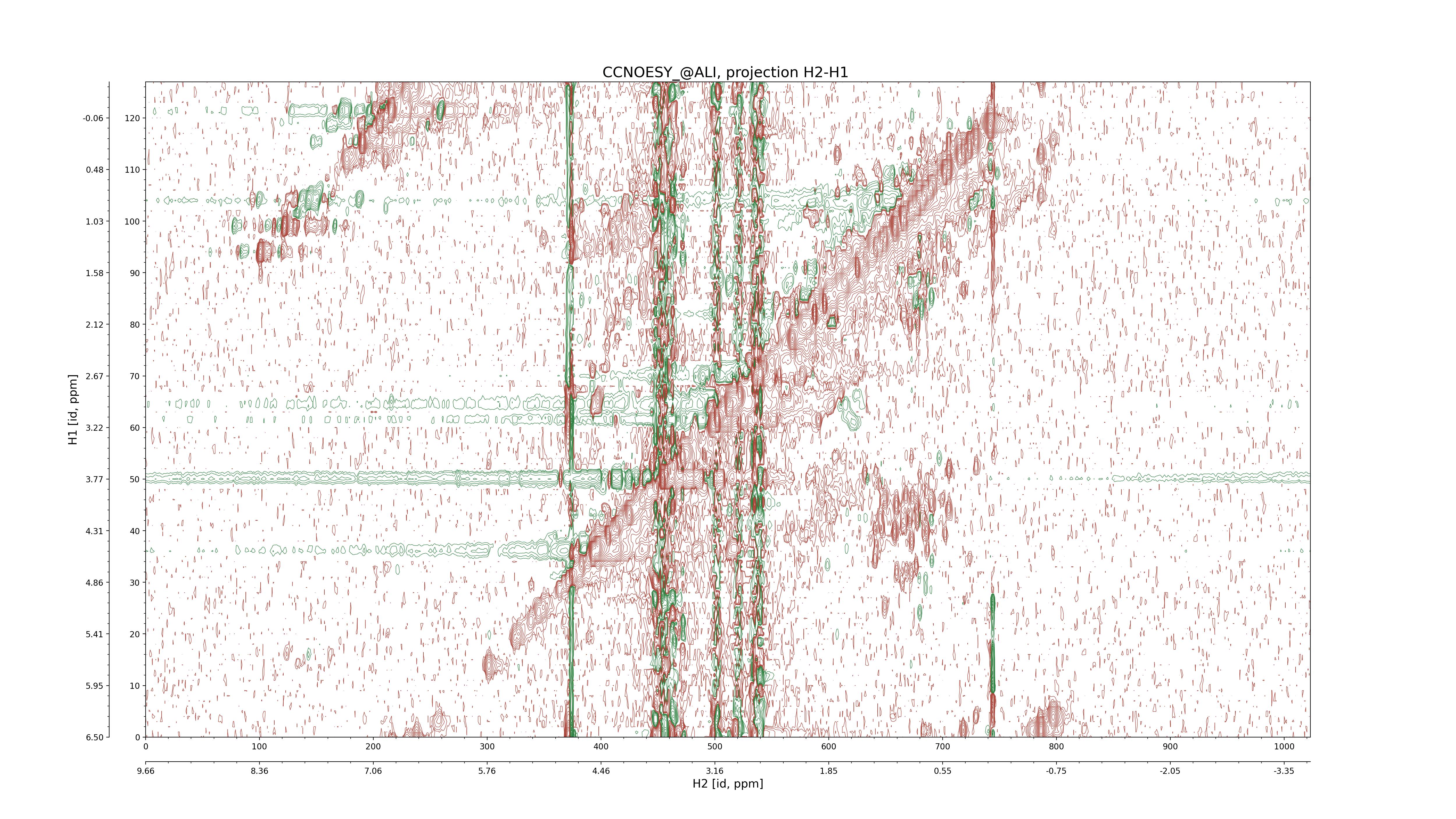{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
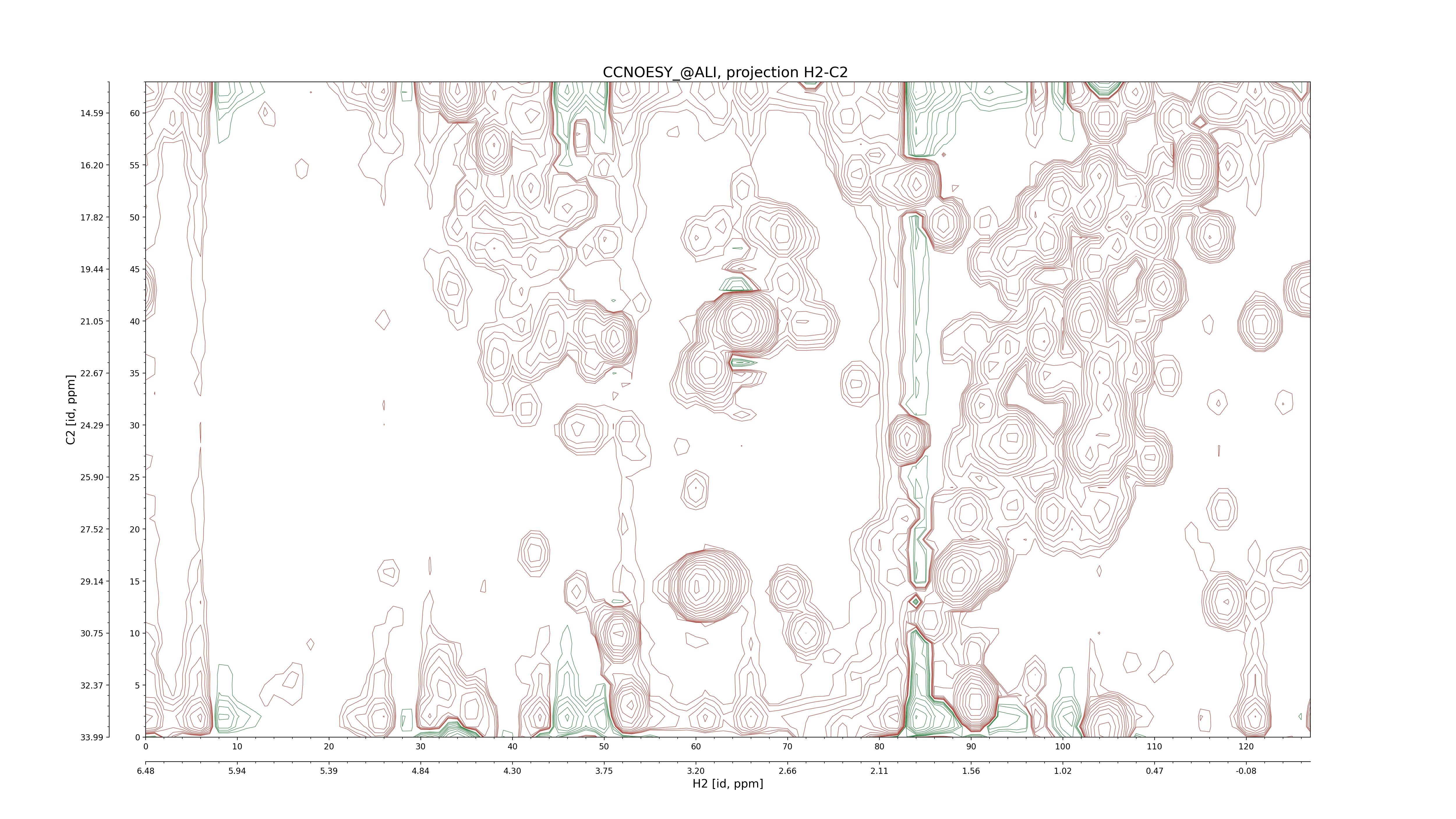{kind=link}
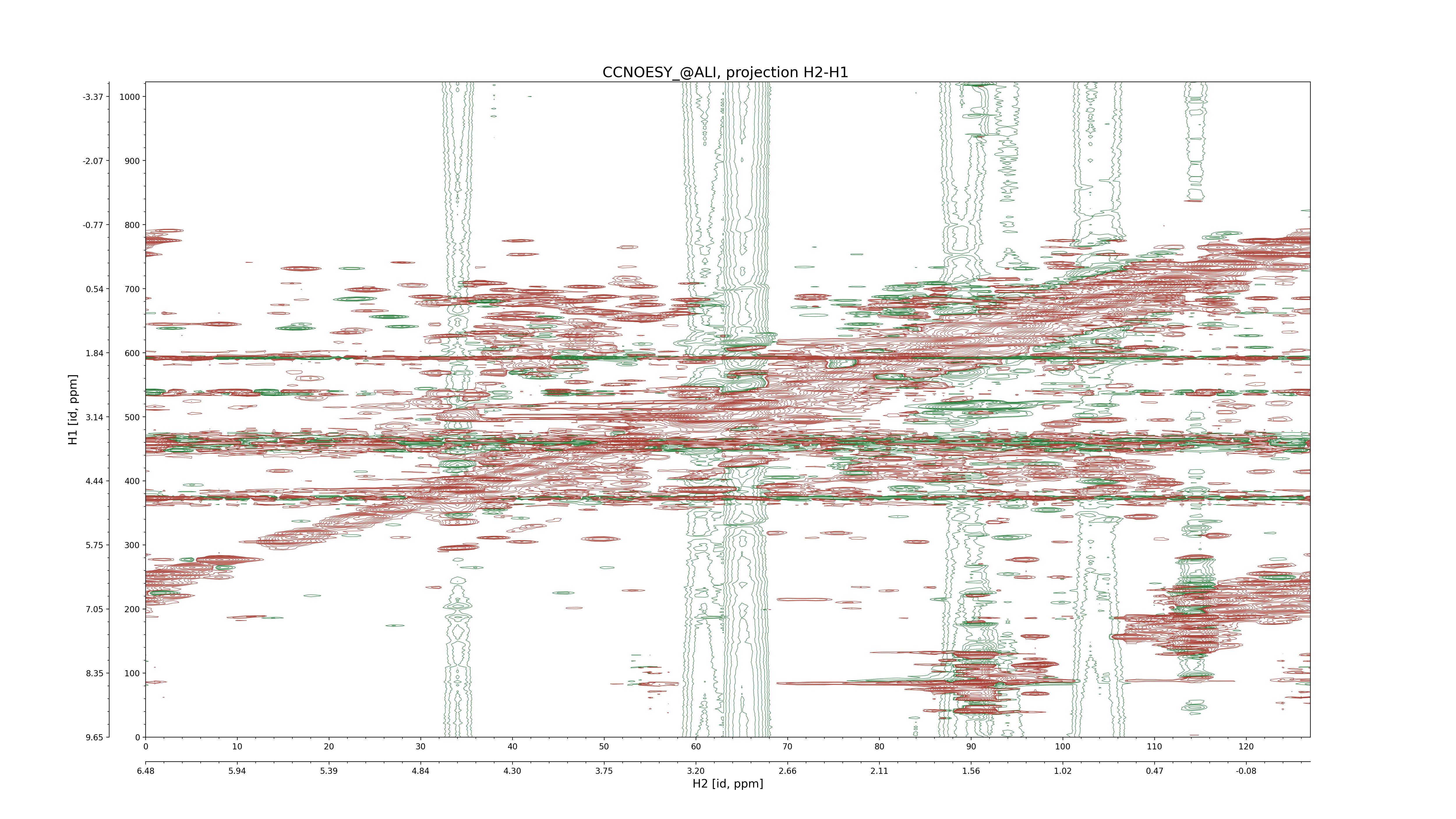{kind=link}
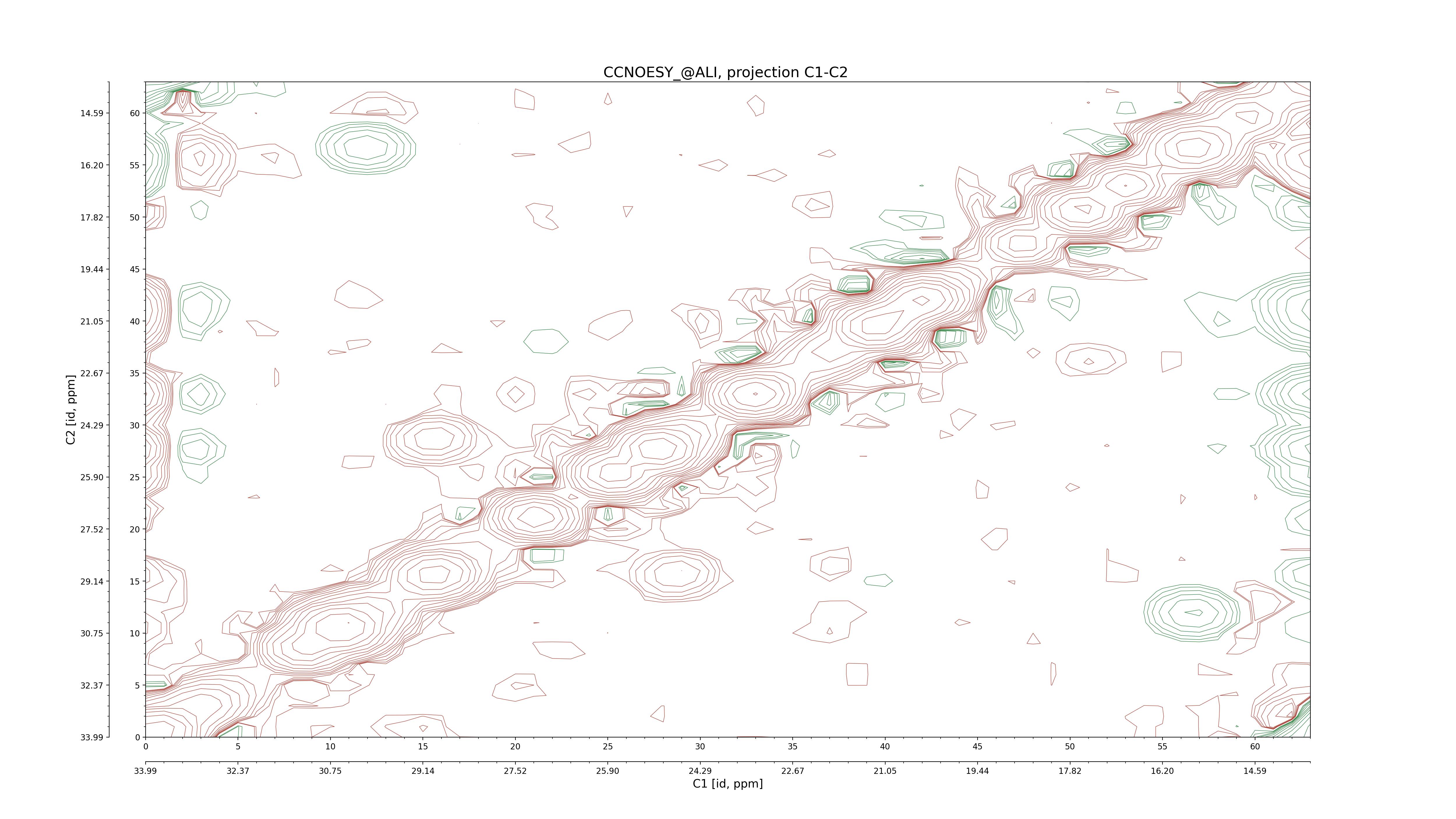{kind=link}
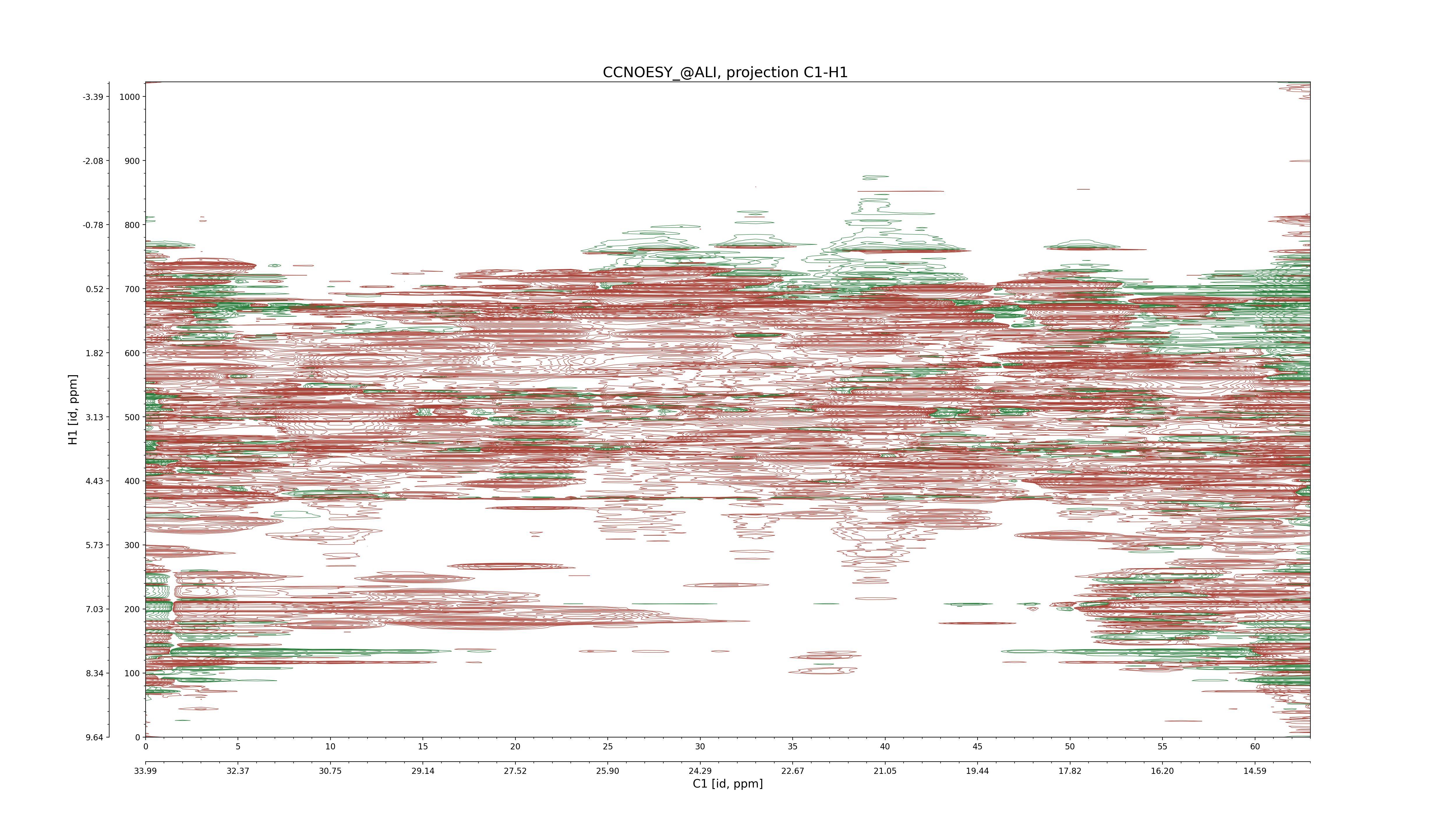{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
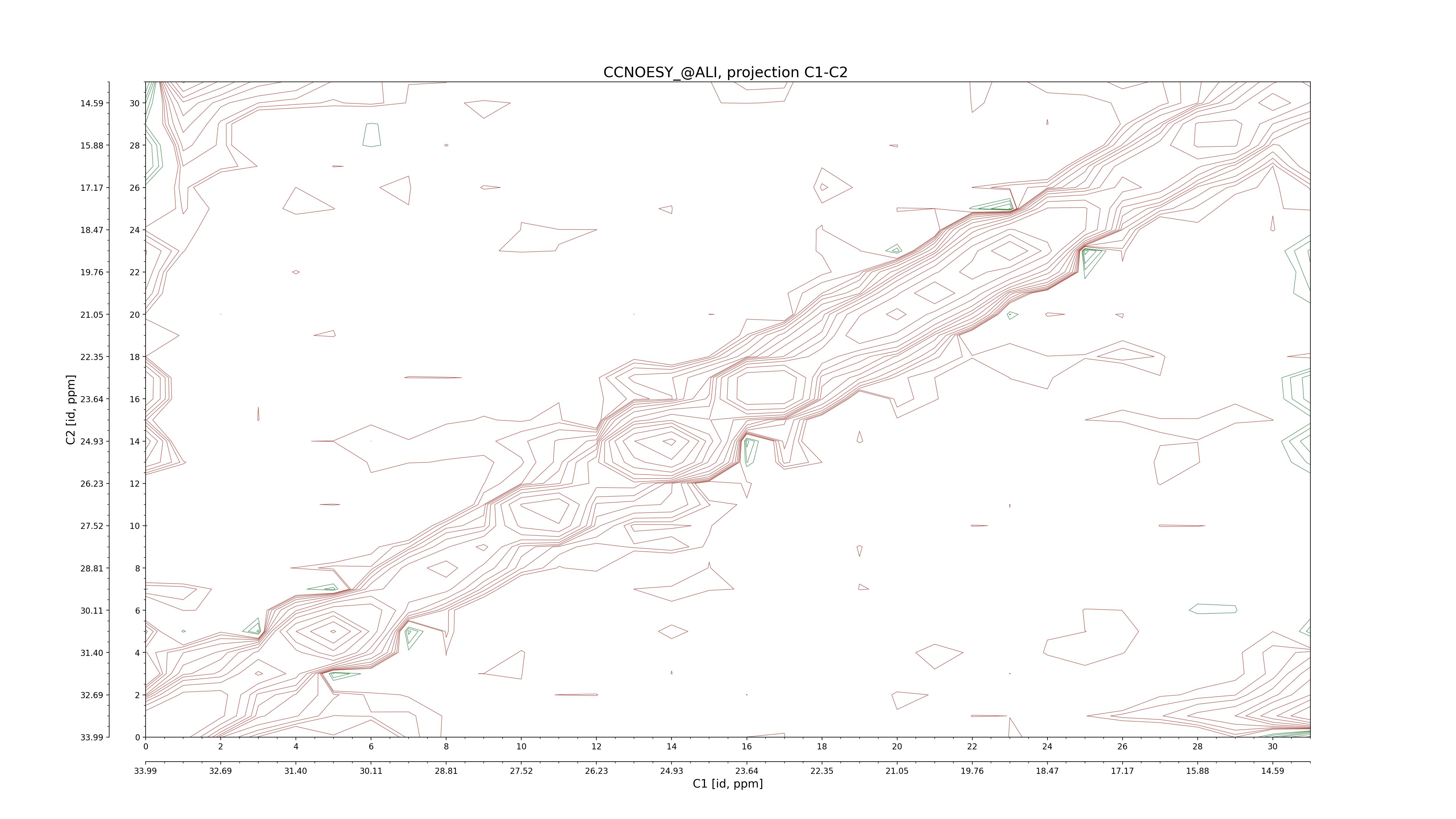{kind=link}
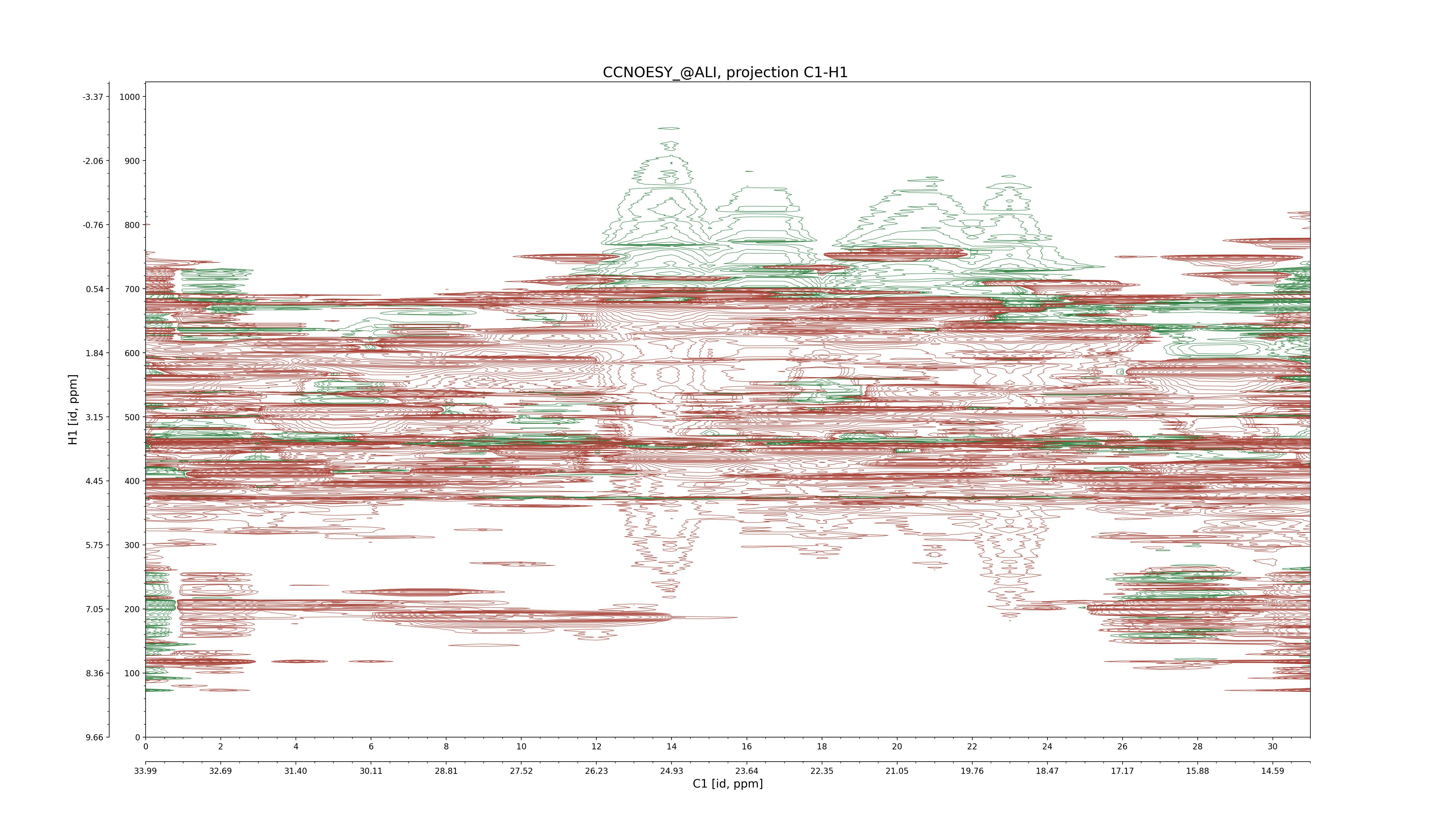{kind=link}
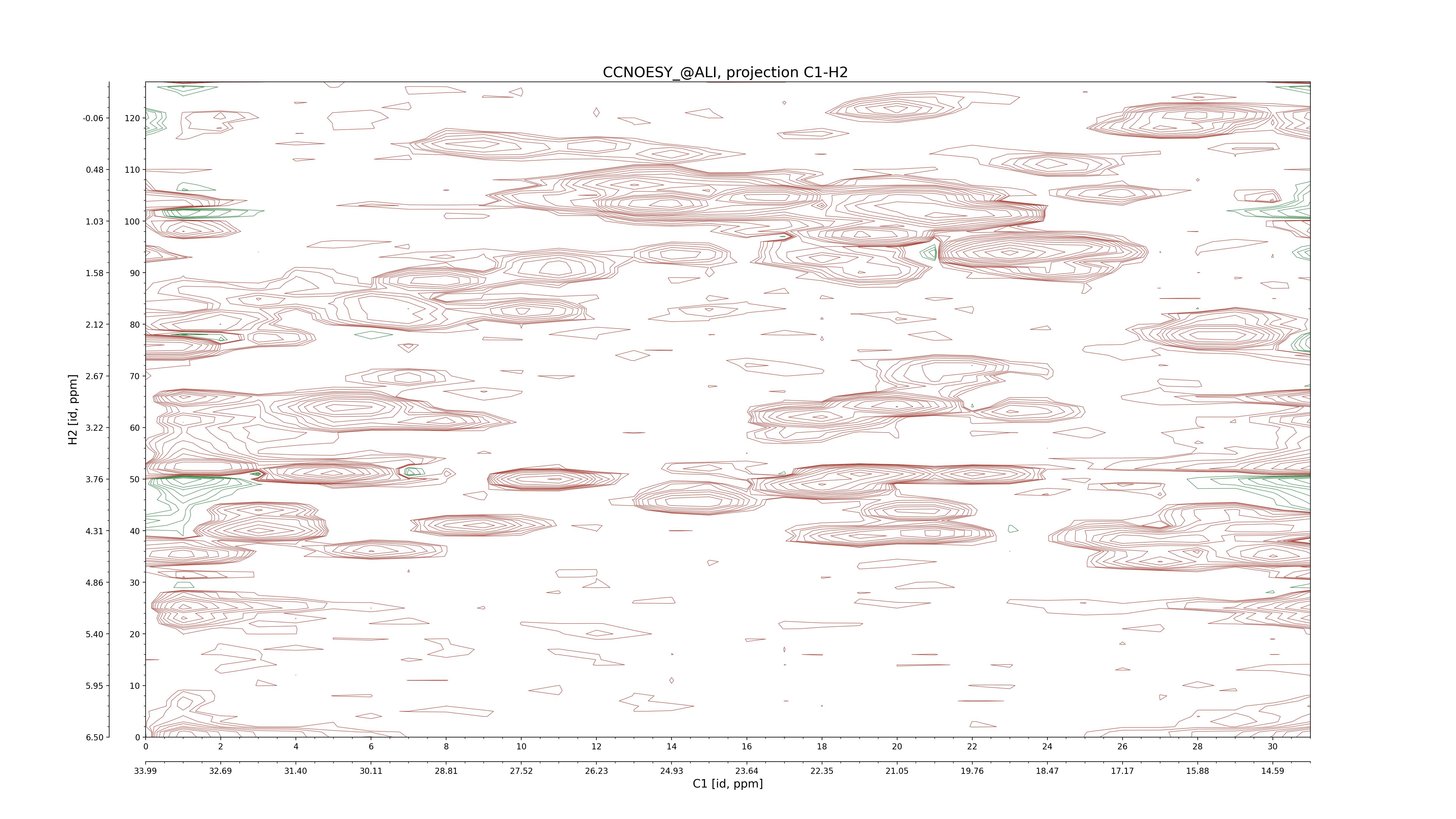{kind=link}
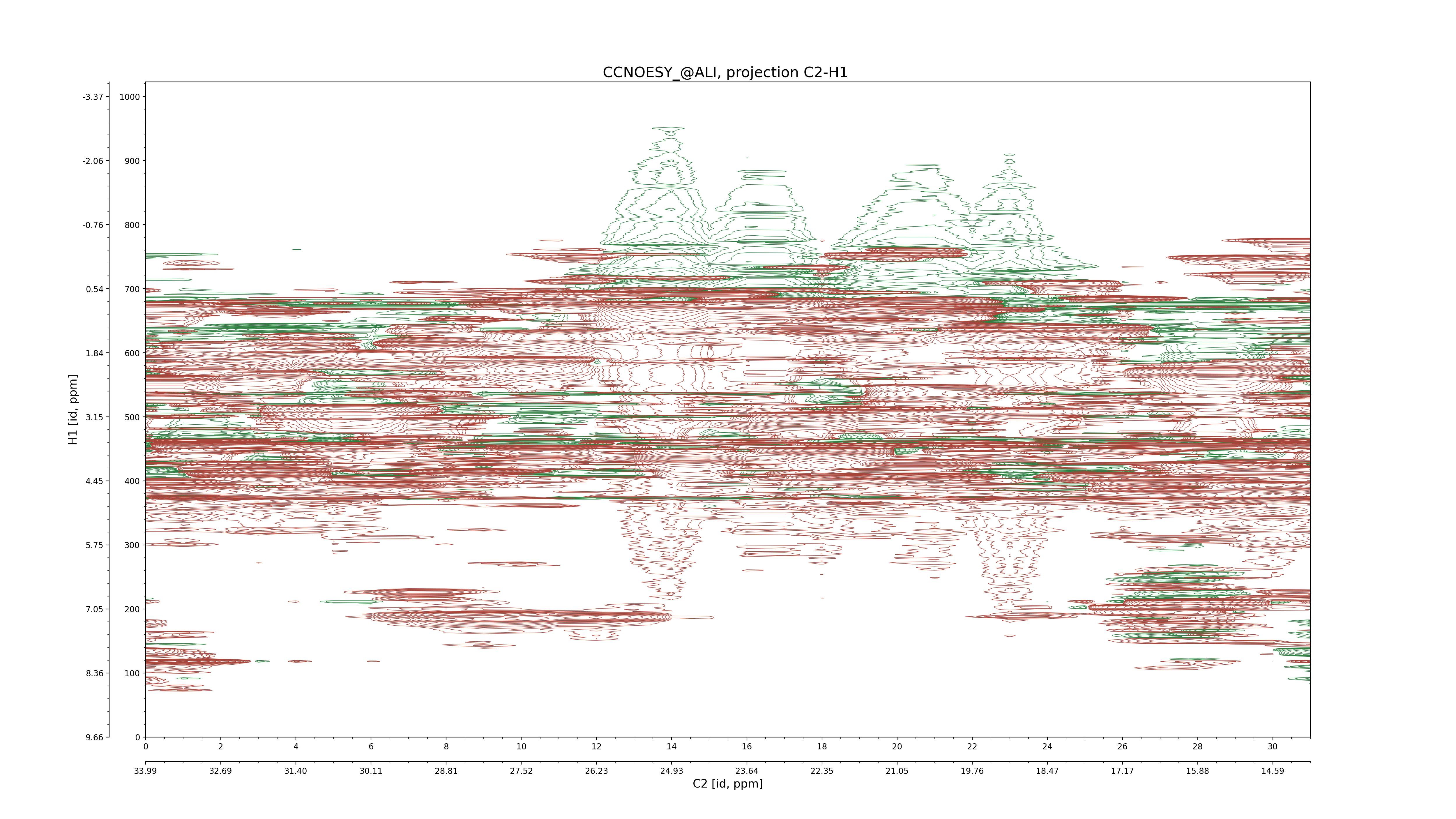{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
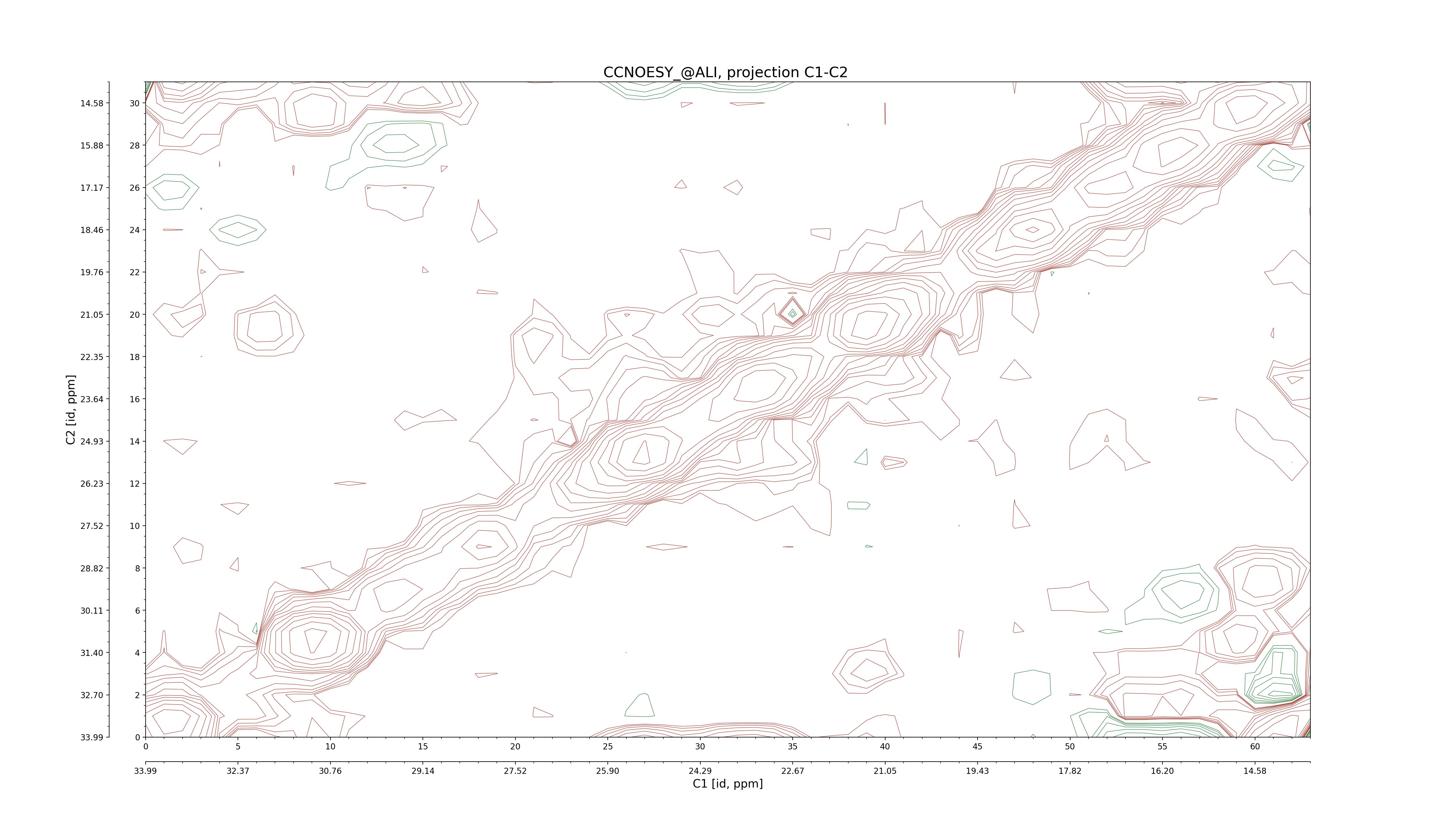{kind=link}
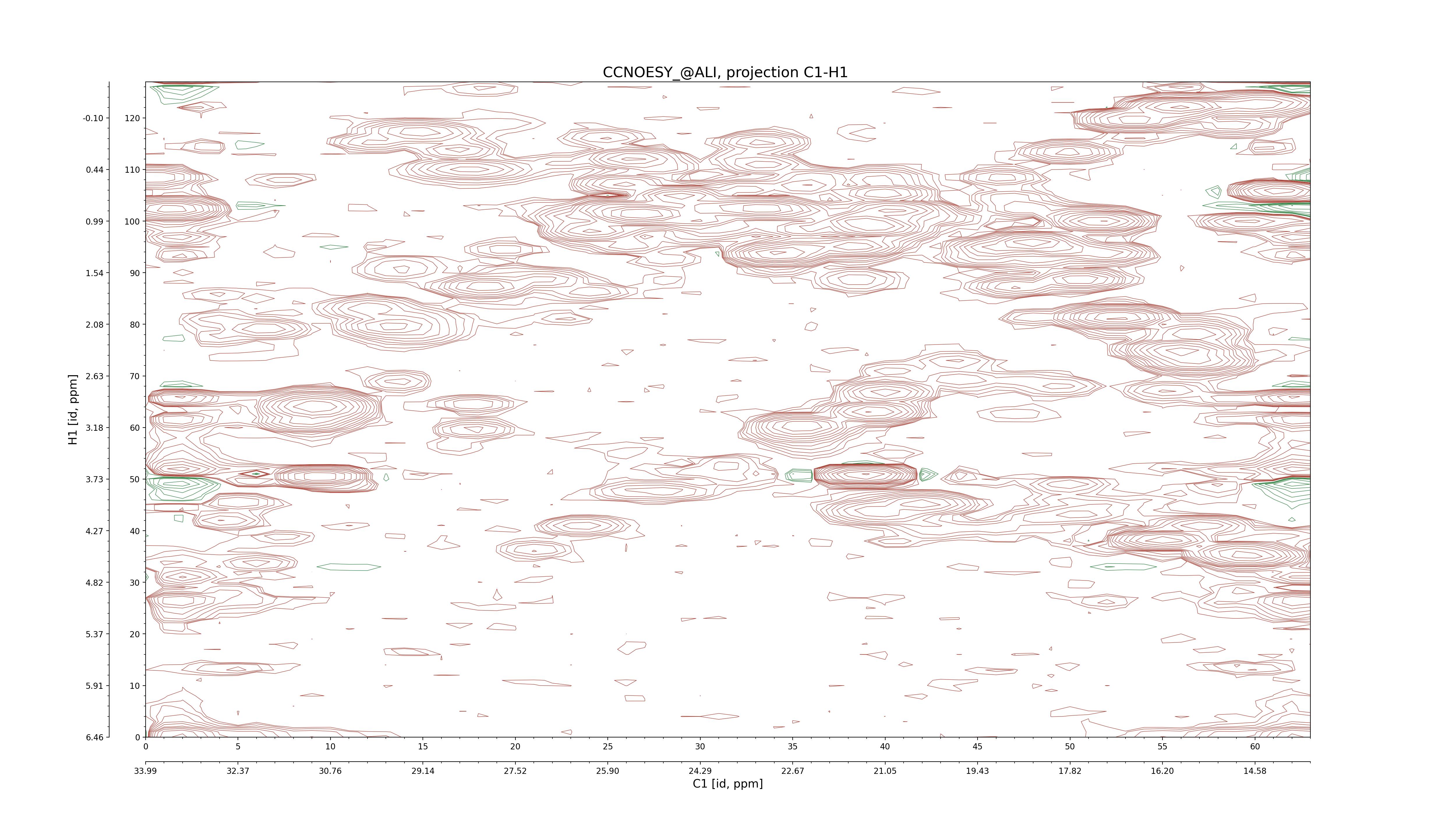{kind=link}
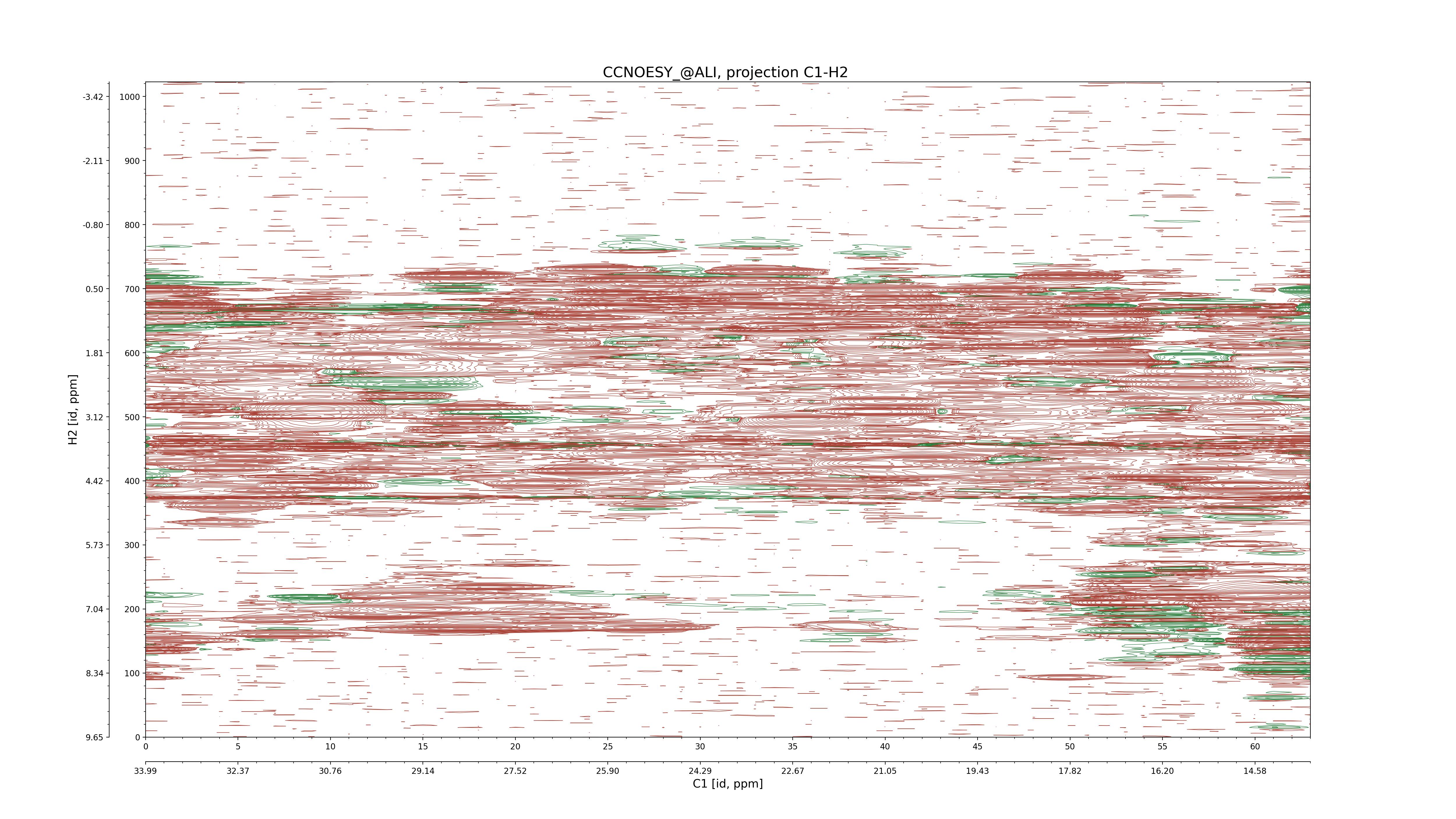{kind=link}
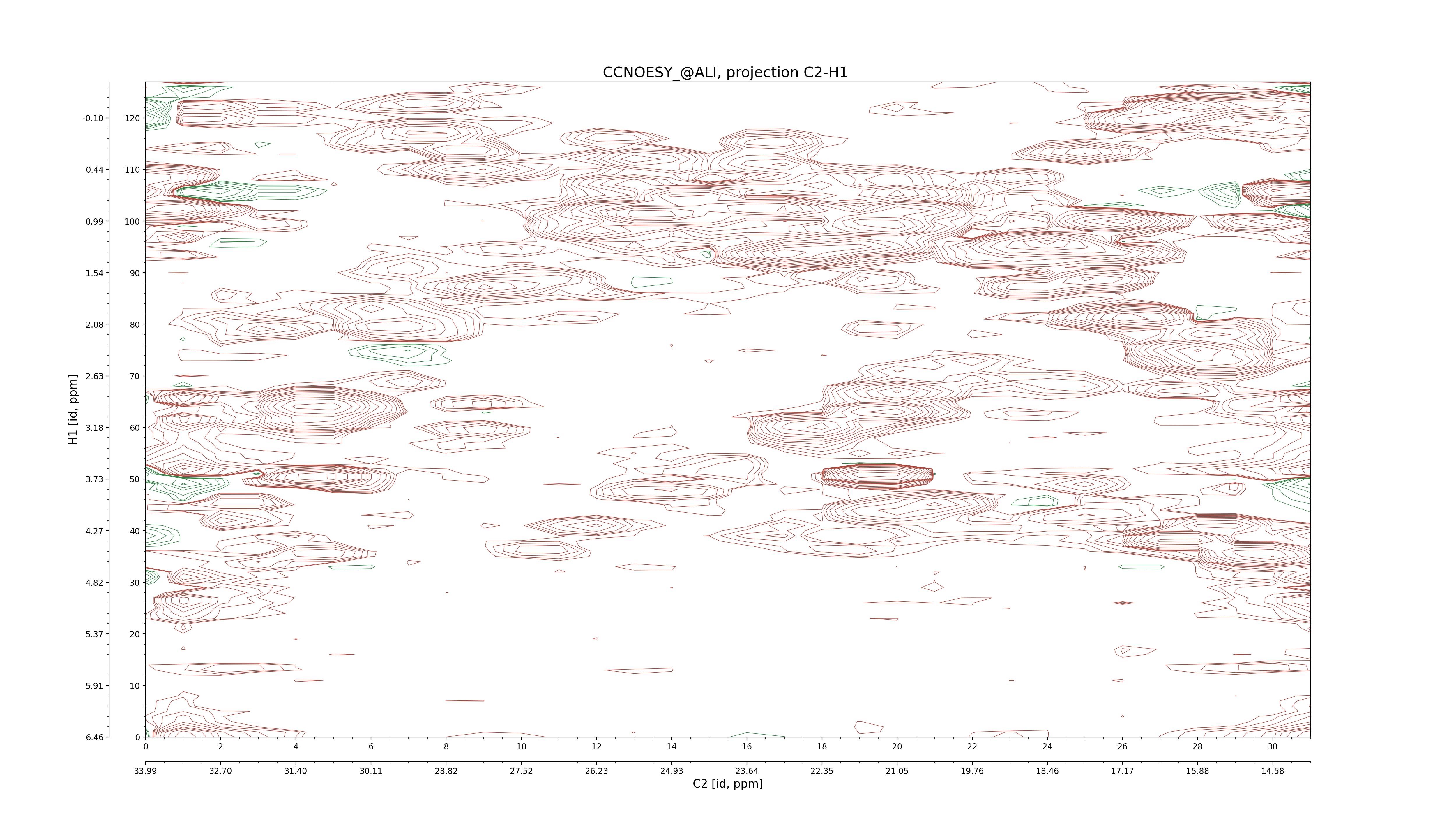{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
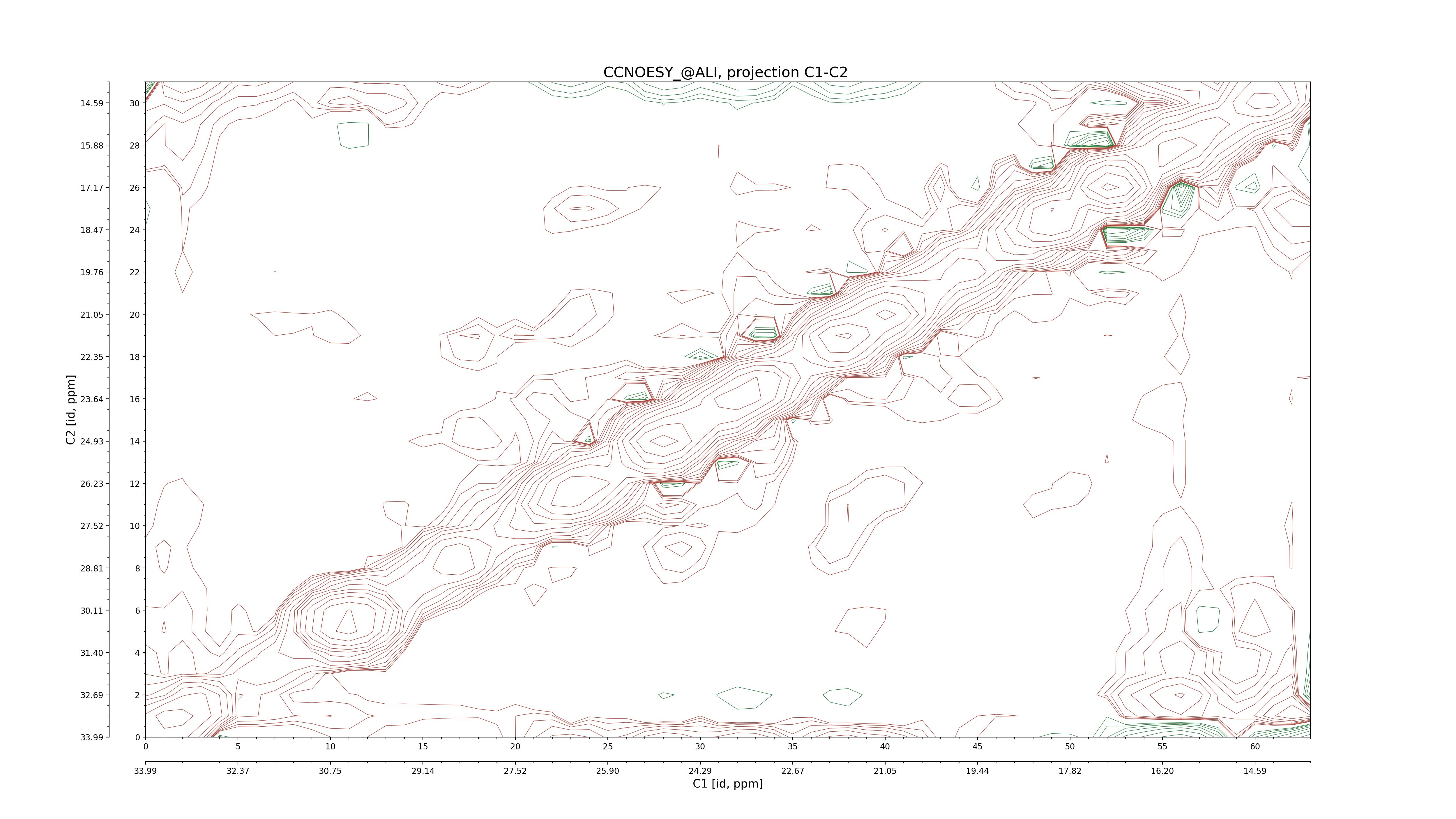{kind=link}
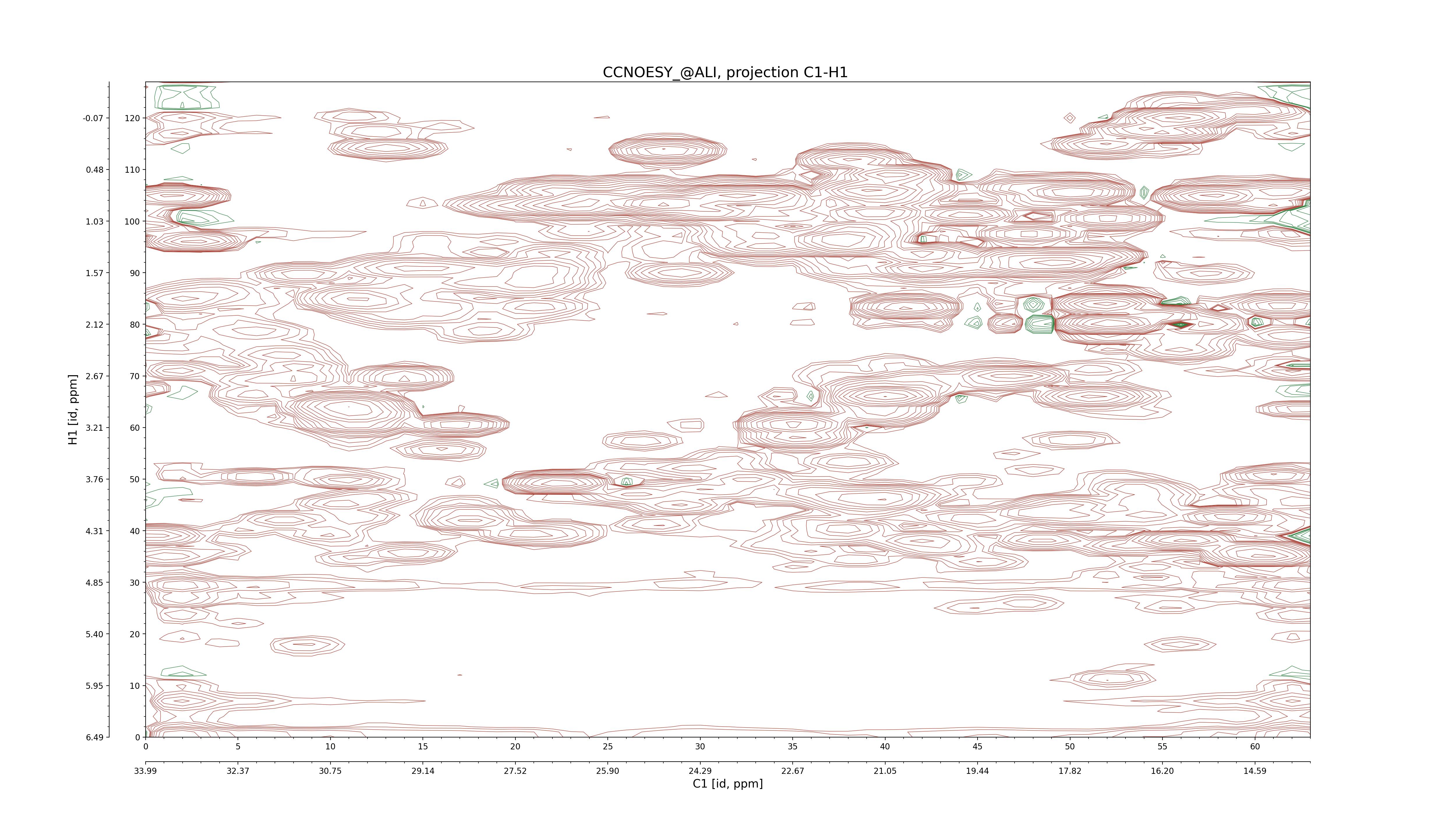{kind=link}
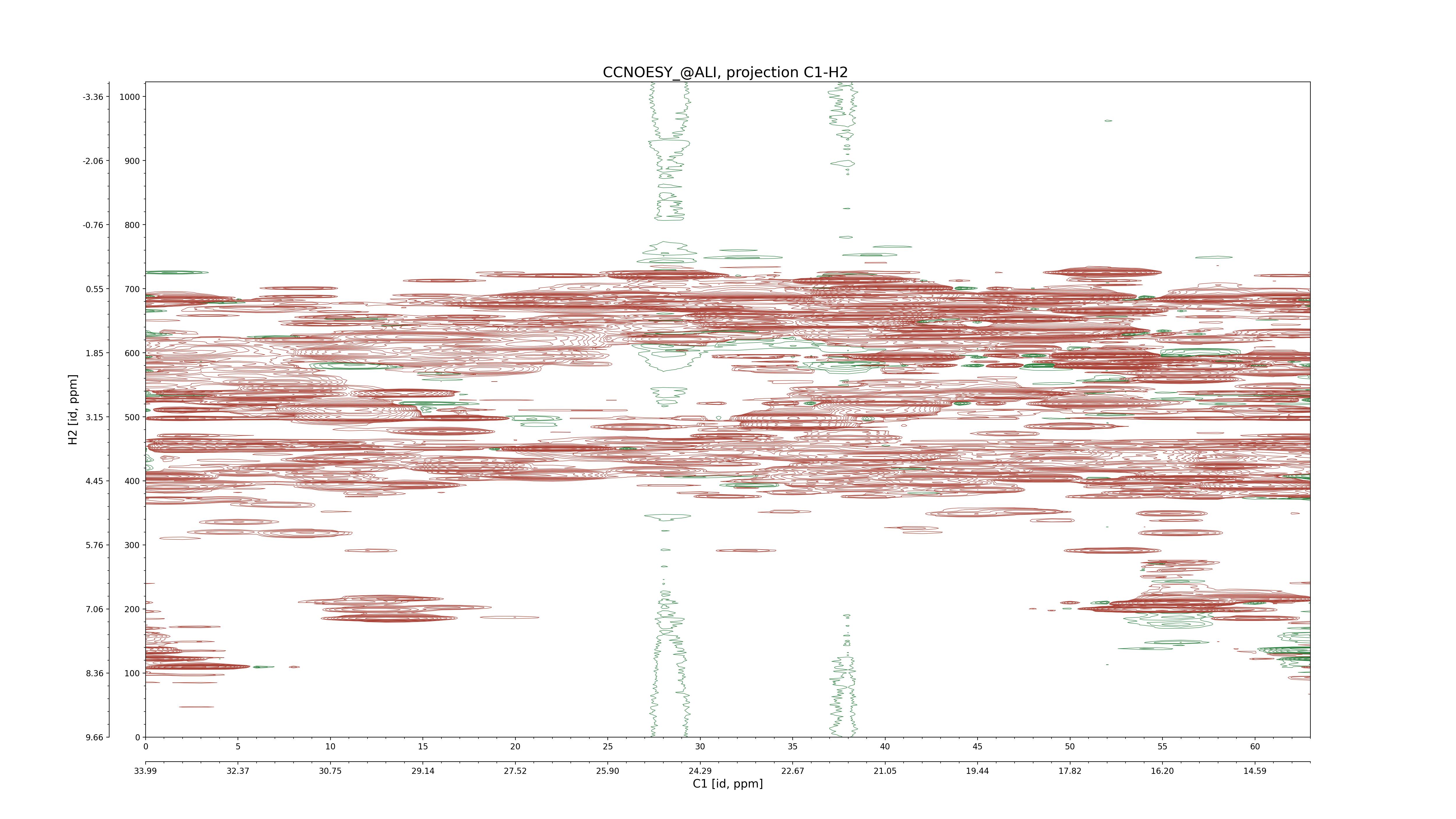{kind=link}
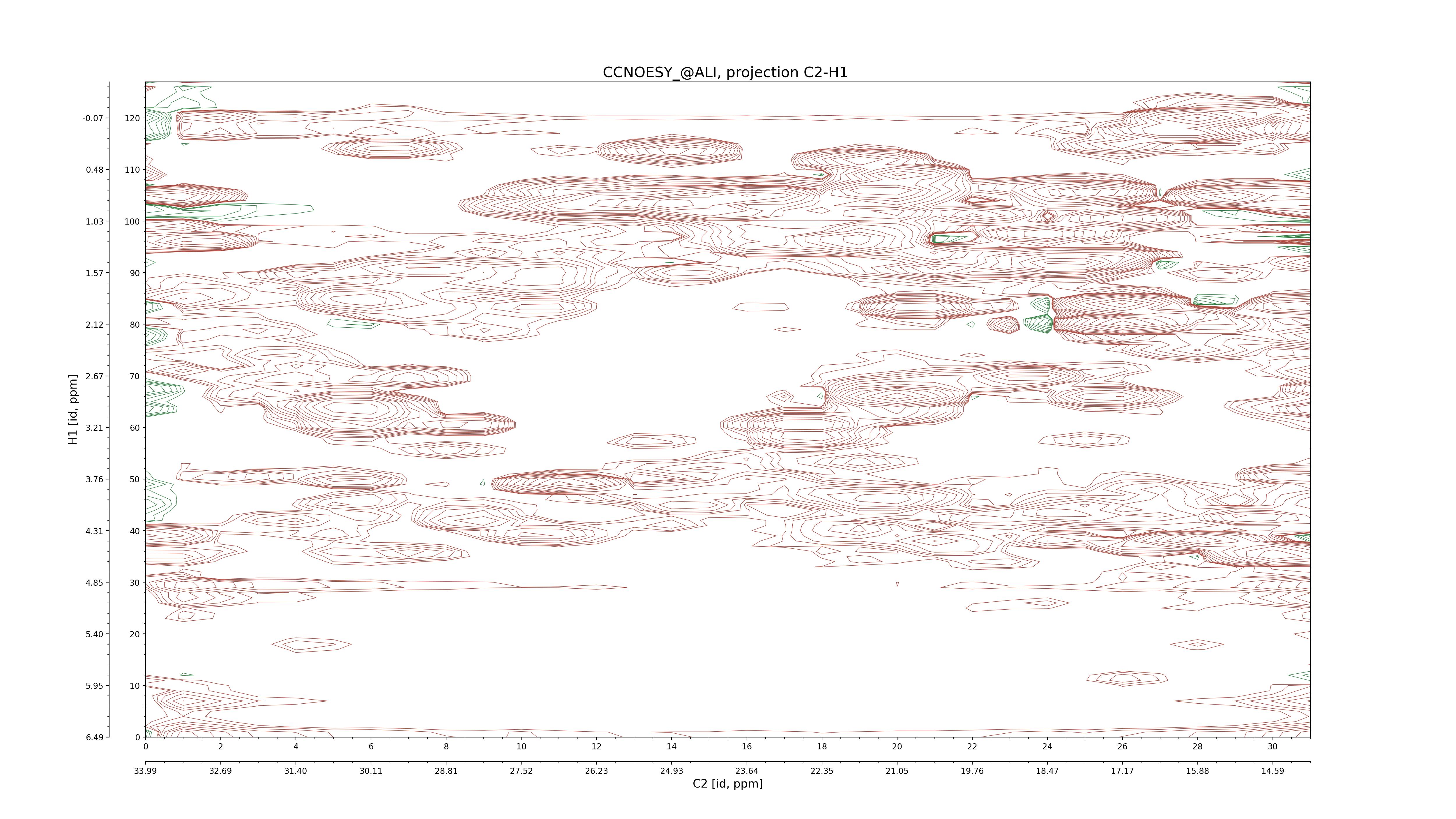{kind=link}
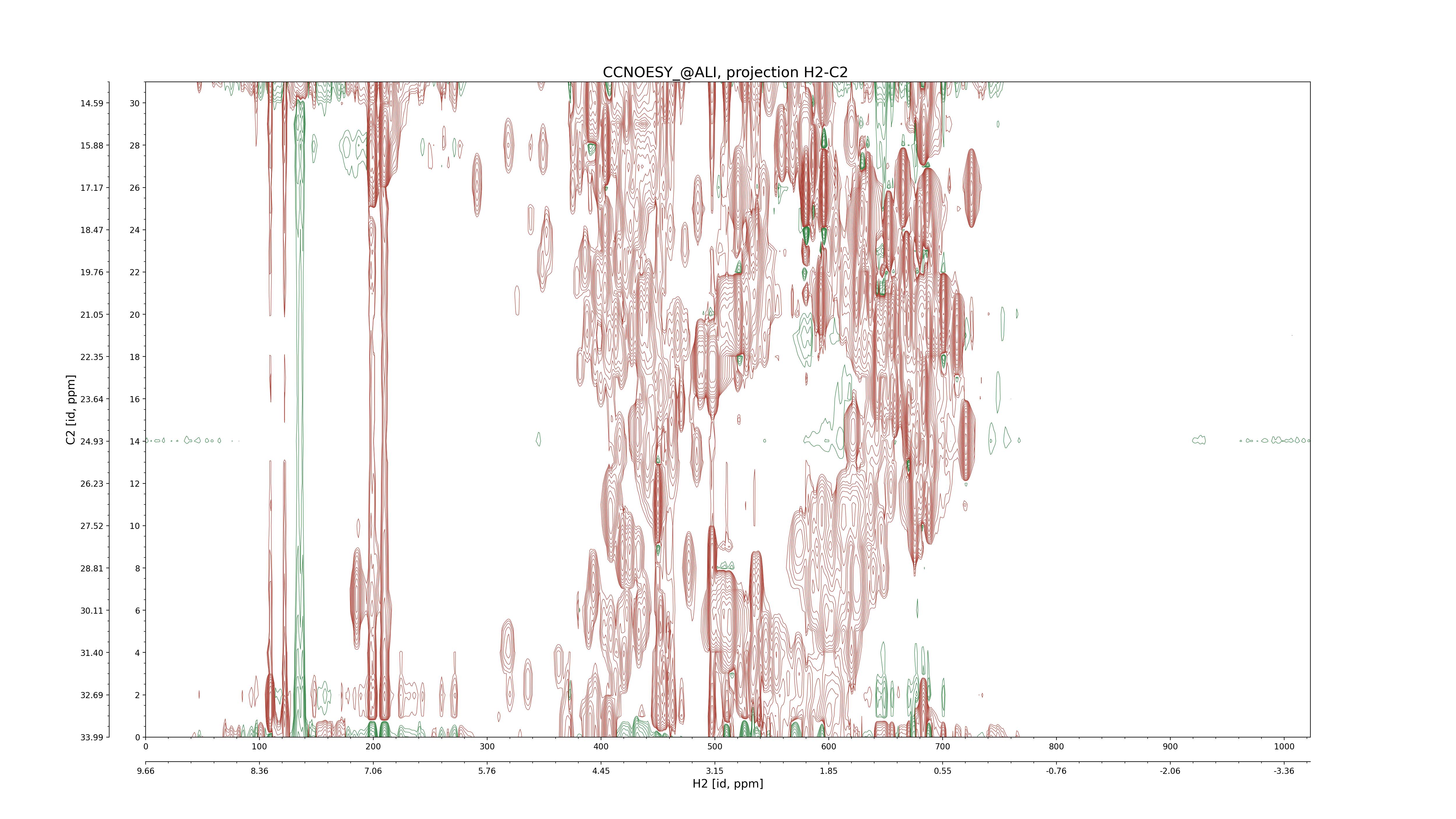{kind=link}
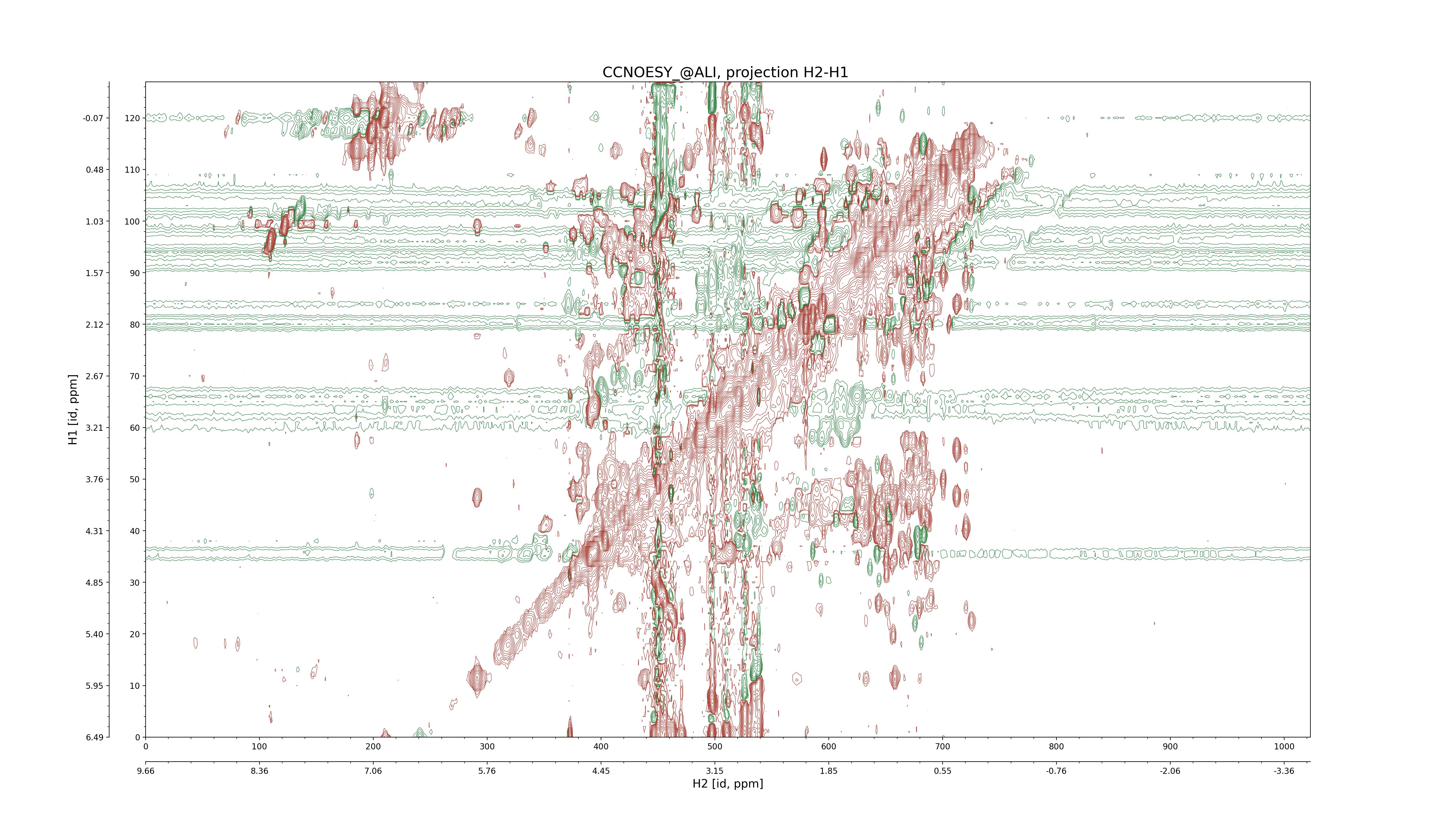{kind=link}
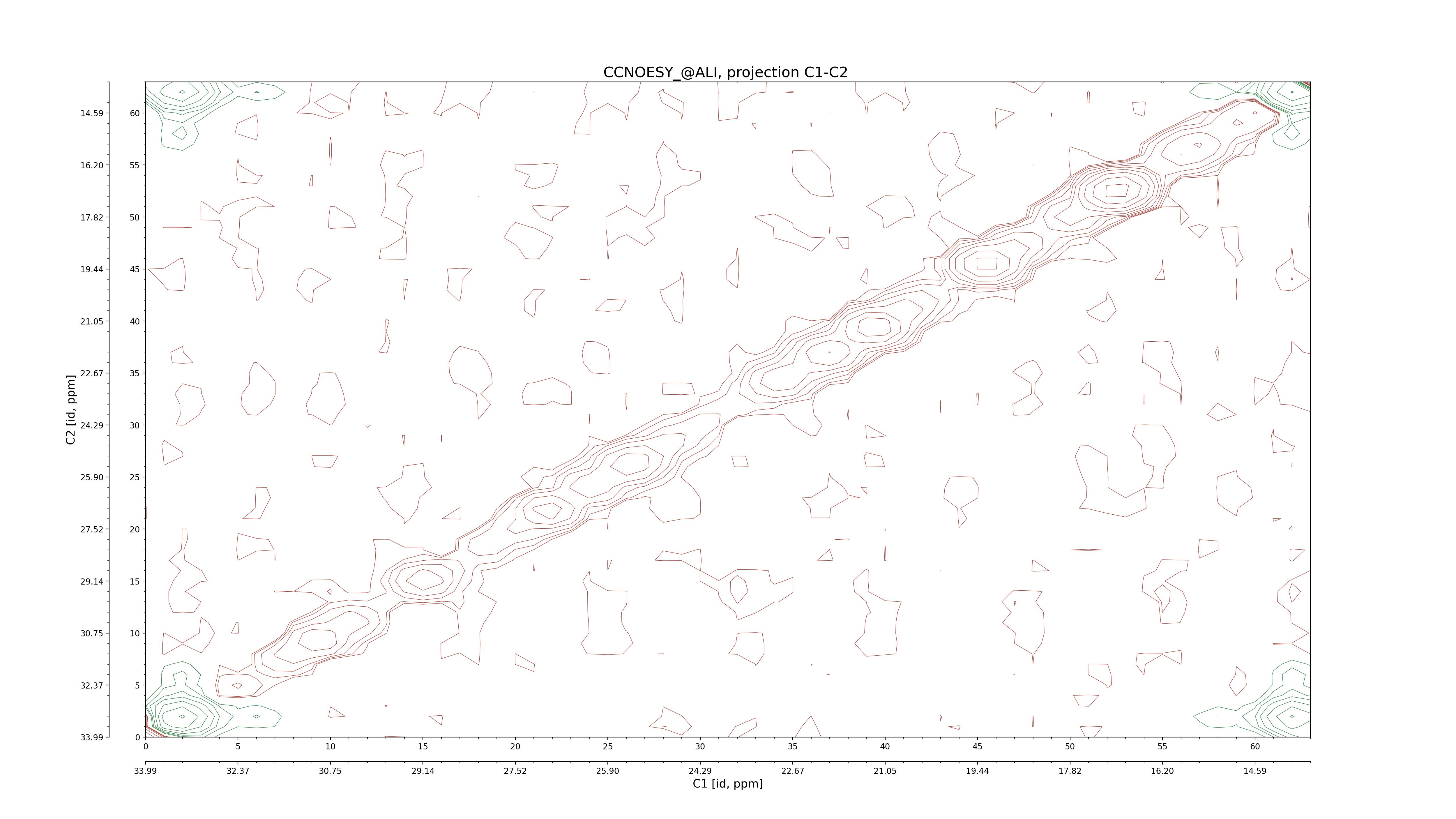{kind=link}
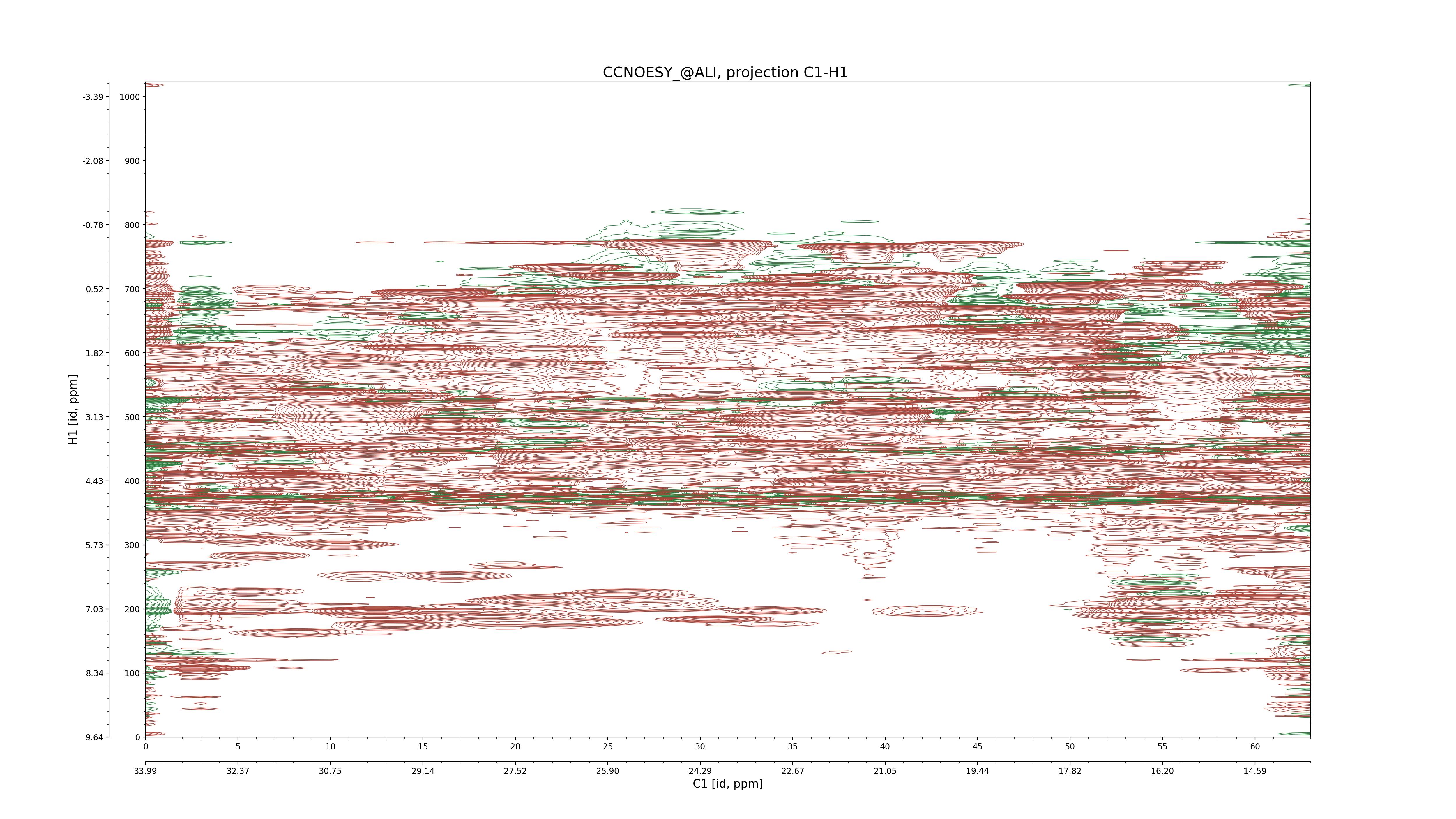{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
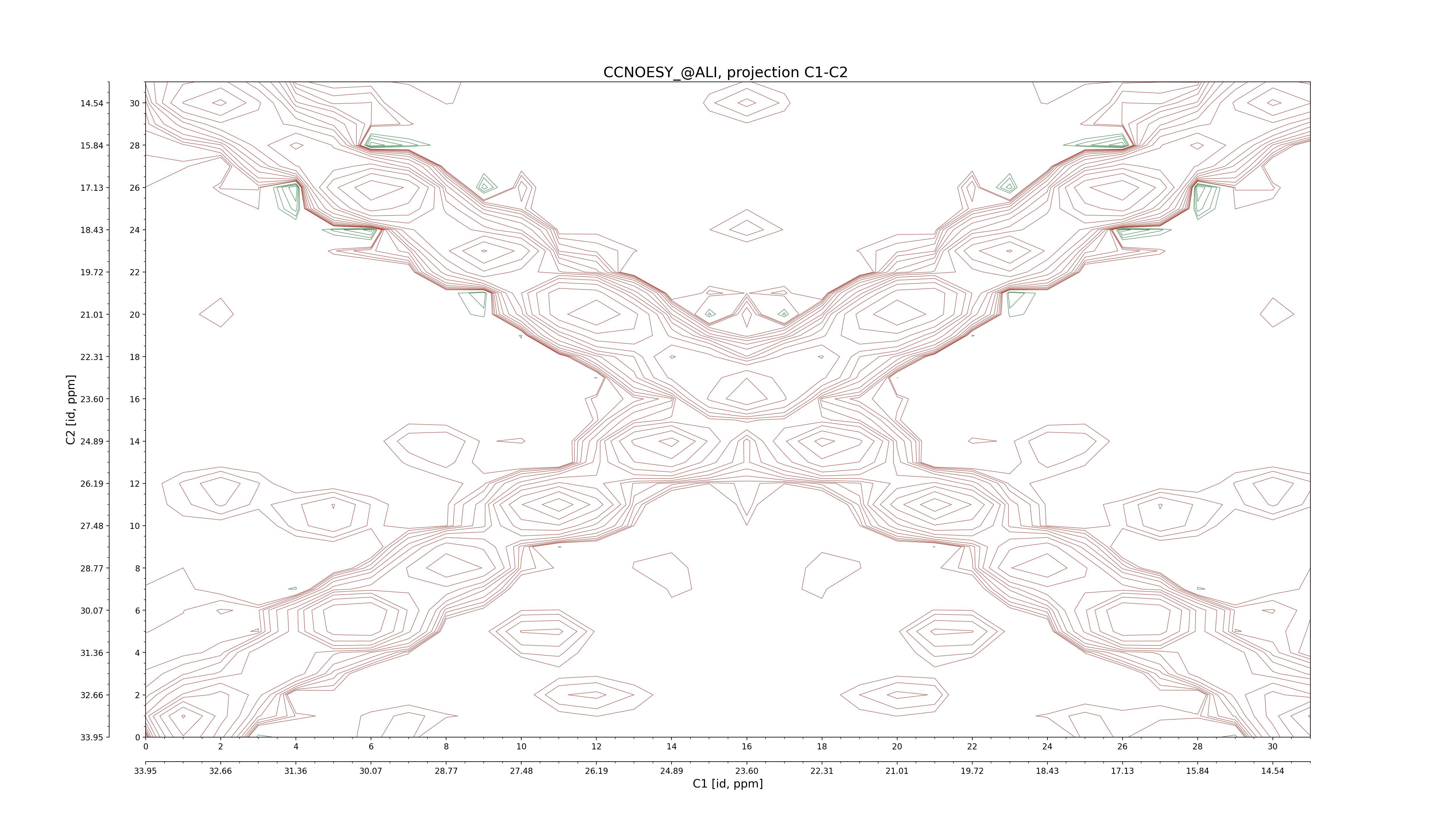{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
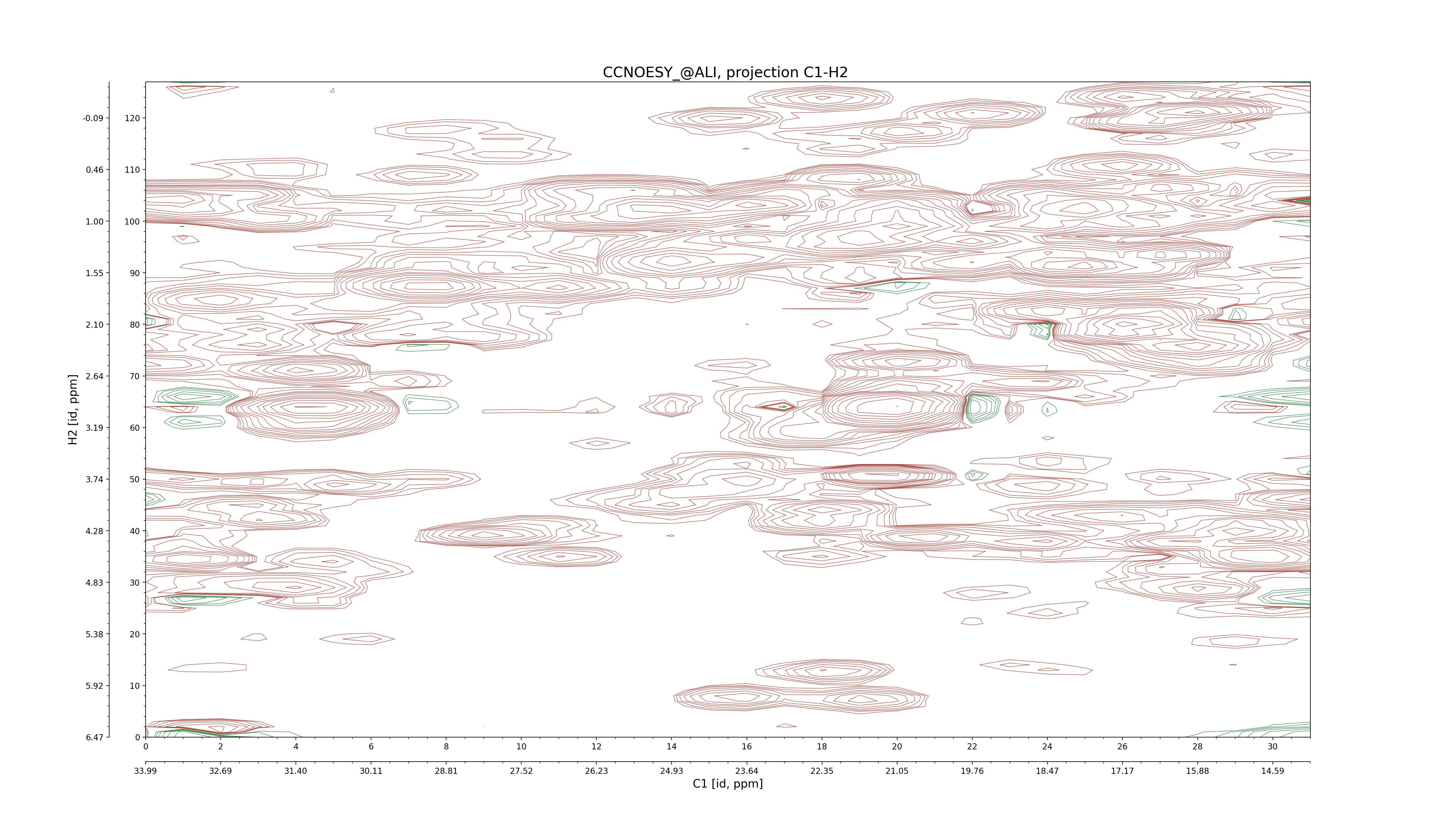{kind=link}
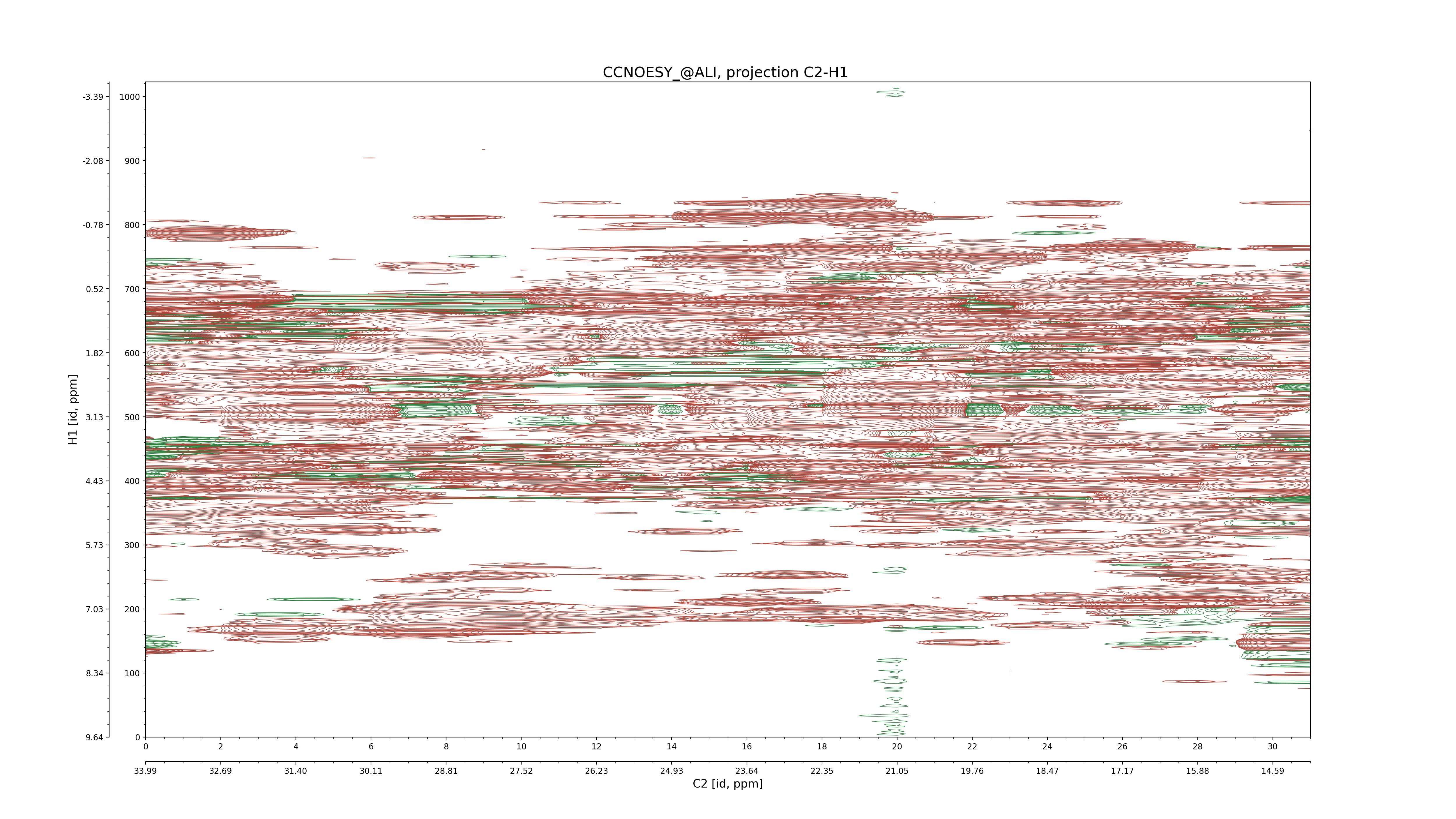{kind=link}
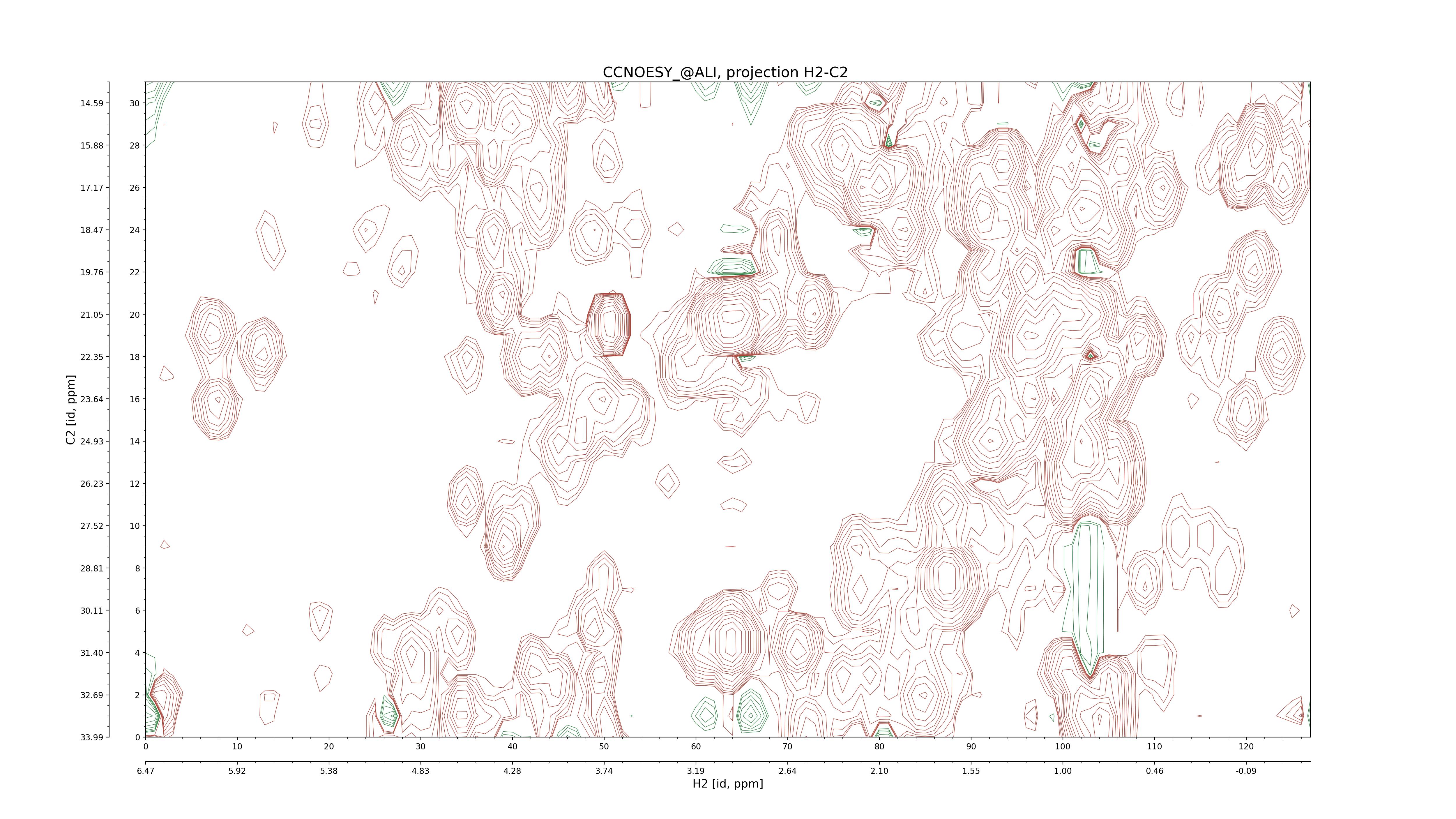{kind=link}
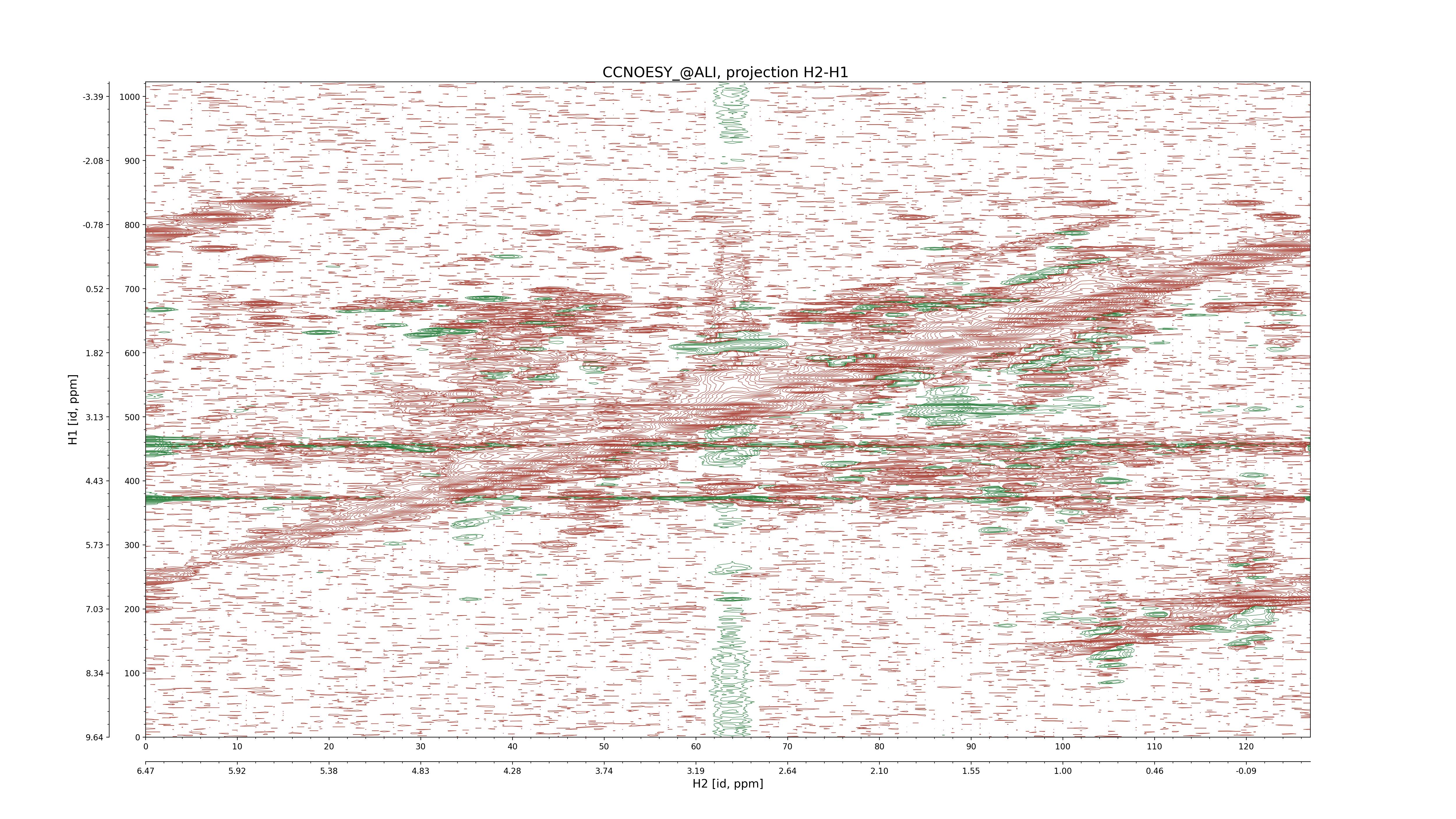{kind=link}